如何结合 PaddleOCR 与 OceanBase 实现企业资产智能化的第一公里
作者:杨有志,百度飞桨星河社区
为什么是”第一公里”不是”最后一公里”?
你可能在阅读技术文章或了解产品时,经常看到宣传文案上写着”某 Agent 的推出,标志着企业面向 Agent 的最后一公里”。但据我观察,许多企业仍处于数字化转型过程中,其业务形态多样且持续变化,现有的智能体框架或产品未必是最终的解决方案。
与其追求看似颠覆性的”最后一公里”,我们更应该务实关注 AI 数字化转型的”第一公里”——如何将企业内大量非结构化的数据,通过 PaddleOCR 等工具进行解析,并经过入库流程,真正沉淀为企业级可用的知识资产。
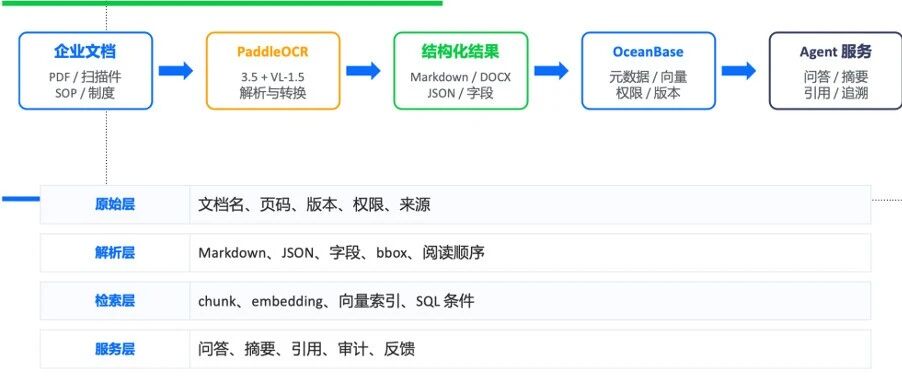
一、企业智能化的第一公里:文档资产化
在与团队内部同事交流 AI 相关问题时,一个经典场景是:他们拥有大量 PDF、Excel、PPT 等文档,当试图将这些复杂文档直接丢给智能体时,智能体往往无法胜任。其核心问题在于,企业或个人的大量文档尚未转化为智能体可理解、可消费、可增删改查、可迭代的知识资产。
PaddleOCR 在其中扮演的角色是:将原始的非结构化、复杂排版、智能体难以直接理解的数据,转换为 Agent 可消费的数据格式(如 Markdown 或 JSON)。在此基础上,我们才能进行后续加工,无论是做 Embedding、文本切分(chunking),还是进行知识抽取。
例如,最新发布的 PaddleOCR-VL-1.6 版本,正在把”文档解析”这件事推向新的精度高度。相比此前版本,PaddleOCR-VL-1.6 不只是一次常规升级,而是在企业级复杂文档场景中,进一步强化了 OCR 作为”AI 数据入口”的能力。
全新 SOTA 精度:重新定义文档解析上限
PaddleOCR-VL-1.6 在 OmniDocBench v1.6 上取得了 96.3% 的最新 SOTA 成绩,同时在 OmniDocBench v1.5、Real5-OmniDocBench 等多个基准测试中继续刷新纪录,文本、公式、表格等核心能力全面领先开源与闭源方案。
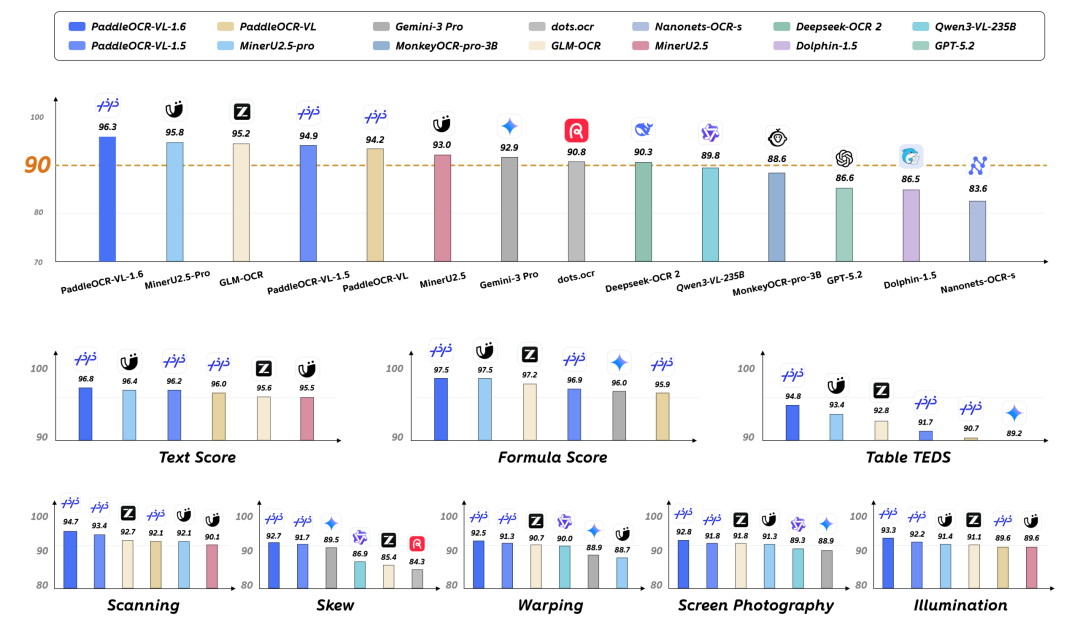
尤其是在”表格结构识别,古籍、生僻字识别,印章、Spotting 场景,图表与复杂版面解析,描件、倾斜拍摄、低质量文档恢复”等复杂场景中,能力提升非常明显。这意味着,企业过去难以结构化处理的 PDF、扫描件、票据、历史档案等内容,现在都可以更稳定地转化为 AI 可消费的数据资产。
典型应用场景
PaddleOCR-VL-1.6 的意义,并不只是 benchmark 上再提升几个百分点。真正卡住企业的问题往往在于,文档仍然无法被 AI 稳定消费:复杂表格难解析、扫描件质量不稳定、古籍与生僻字识别困难、合同与票据结构混乱。而 PaddleOCR-VL-1.6 的提升,正是在解决这些”第一公里”问题。

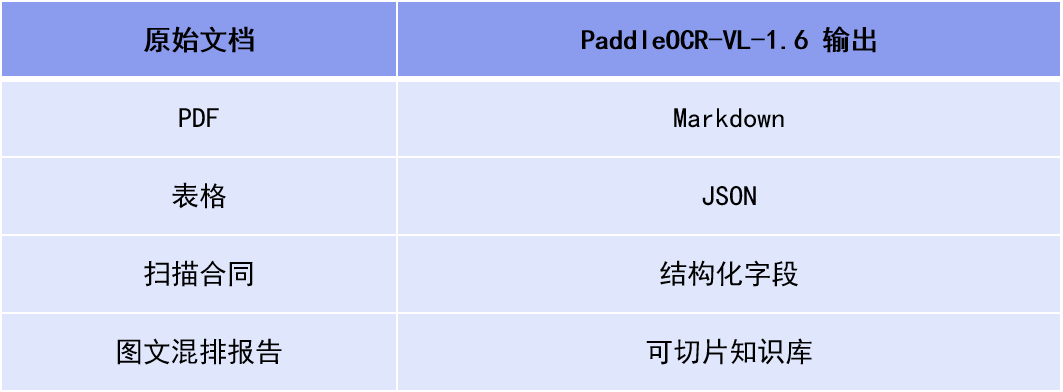
无论是金融合同、企业报表,还是历史档案、教育试卷,这些过去高度依赖人工处理的文档,现在都能更稳定地转化为 Markdown、JSON 等 AI 可直接使用的数据格式。
PaddleOCR-VL-1.6 已经不仅仅是 OCR 模型,更像是企业 AI 数据链路中的”解析基础设施”。
从办公文档到 AI 友好数据:Markdown、JSON 直接进入链路
PaddleOCR-VL-1.6 并不仅仅只会”识别文字”。它更重要的能力,是将企业内部大量非结构化文档,直接转化为适用于 Agent、RAG、知识库系统的大模型友好格式。
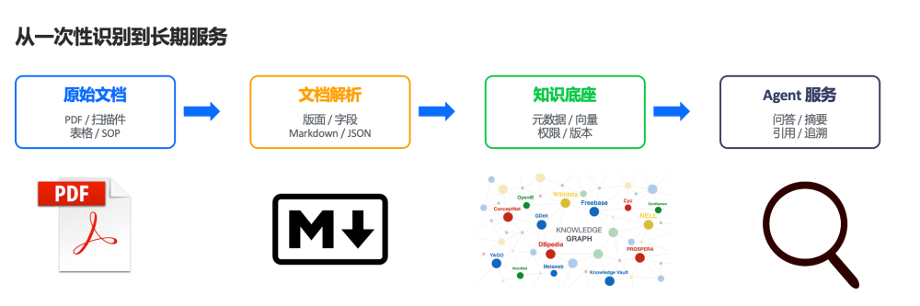
你无需再进行大量有损格式转换(例如 PPT 转 PDF、截图转文本),而是可以直接对原始文档进行高质量解析。
零成本迁移
虽然能力大幅升级,但 PaddleOCR-VL-1.6 在工程侧几乎没有迁移成本。其模型结构与 PaddleOCR-VL-1.5 完全一致:推理链路无需重构、原有接口基本兼容、部署方式保持一致、可直接替换升级。对于企业来说,这意味着不需要重新改造整套 OCR Pipeline,就可以直接获得更高精度与更强泛化能力。
二、文档资产智能化链路:从解析到入库与检索
PaddleOCR 的核心价值在于将非结构化数据转化为 Agent 可消费格式。后续通常还需对知识进行进一步处理。例如:法律公司处理案件时,可能需要将文档信息抽取成实体和关系,构建知识图谱;出版行业可能只需对书籍内容进行 Embedding 和切片处理,然后存入 OceanBase 数据库。
在数据资产入库后,即可在 OceanBase 上利用其支持的检索接口(关键词检索、向量检索、混合检索等),并通过 Agent 定义相应的工具来提供检索服务。从技术流来看,PaddleOCR 处于知识文档解析的上游,OceanBase 则是下游的数据存储与检索层。
这条”解析→入库→检索”的链路,已经在 ClawMaster 项目(OpenClaw 的管理工具)中跑通了端到端的闭环。ClawMaster 底层接入了 PowerMem 作为知识底座,内置 paddleocr-doc-parsing 技能。不止于”存进去、搜出来”,这条链路还可以让知识资产持续”生长”。ClawMaster 的 LLM Wiki 功能就是一例:PaddleOCR 解析出的 Markdown 被注入 Wiki 后,LLM 会自动抽取实体、建立交叉引用、检测事实冲突。
适用于个人开发者的低门槛链路
面向开发者的轻量级 AI 原生数据库 OceanBase seekdb,让”解析→入库→检索”这条链路的门槛进一步降低。seekdb 继承了 OceanBase 的存储引擎和 MySQL 兼容性,同时原生支持向量索引(HNSW/IVF)、全文索引(BM25)和混合搜索——一条 SQL 即可完成多路召回与重排序。

seekdb 内置了 AI_EMBED、AI_COMPLETE、AI_RERANK 等 AI Function,支持在 SQL 中直接调用模型做库内推理——这意味着 PaddleOCR 解析出的文档内容,从切片、Embedding 到入库检索,甚至推理问答,都可以在同一个数据库实例内闭环完成。seekdb 支持 1C2G 小规格运行,也支持嵌入式部署(原生 Python 集成)。
相关链接:
- 体验 PaddleOCR 能力:aistudio.baidu.com
- 轻量级 AI 原生数据库 seekdb:https://github.com/oceanbase/seekdb
- 长期记忆系统 PowerMem:https://github.com/oceanbase/powermem
- 龙虾管理大师 ClawMaster:https://github.com/openmaster-ai/clawmaster-workshop