classSentenceTransformerCustomEmbeddingFunction(EmbeddingFunction[Documents]): """ A custom embedding function using sentence-transformers with a specific model. """
def__init__(self, model_name: str = "all-mpnet-base-v2", device: str = "cpu"): # TODO: your own model name and device """ Initialize the sentence-transformer embedding function. Args: model_name: Name of the sentence-transformers model to use device: Device to run the model on ('cpu' or 'cuda') """ self.model_name = model_name or os.environ.get('SENTENCE_TRANSFORMERS_MODEL_NAME') self.device = device or os.environ.get('SENTENCE_TRANSFORMERS_DEVICE') self._model = None self._dimension = None
def_ensure_model_loaded(self): """Lazy load the embedding model""" if self._model isNone: try: from sentence_transformers import SentenceTransformer self._model = SentenceTransformer(self.model_name, device=self.device) # Get dimension from model test_embedding = self._model.encode(["test"], convert_to_numpy=True) self._dimension = len(test_embedding[0]) except ImportError: raise ImportError( "sentence-transformers is not installed. " "Please install it with: pip install sentence-transformers" )
@property defdimension(self) -> int: """Get the dimension of embeddings produced by this function""" self._ensure_model_loaded() return self._dimension
def__call__(self, input: Documents) -> Embeddings: """ Generate embeddings for the given documents. Args: input: Single document (str) or list of documents (List[str]) Returns: List of embedding vectors """ self._ensure_model_loaded()
# Handle single string input ifisinstance(input, str): input = [input]
# Convert numpy arrays to lists return [embedding.tolist() for embedding in embeddings]
classOpenAIEmbeddingFunction(EmbeddingFunction[Documents]): """ A custom embedding function using Embedding API. """
def__init__(self, model_name: str = "", api_key: str = "", base_url: str = ""): """ Initialize the Embedding API embedding function. Args: model_name: Name of the Embedding API embedding model api_key: Embedding API key (if not provided, uses EMBEDDING_API_KEY env var) """ self.model_name = model_name or os.environ.get('EMBEDDING_MODEL_NAME') self.api_key = api_key or os.environ.get('EMBEDDING_API_KEY') self.base_url = base_url or os.environ.get('EMBEDDING_BASE_URL') self._dimension = None ifnot self.api_key: raise ValueError("Embedding API key is required")
def_ensure_model_loaded(self): """Lazy load the Embedding API model""" try: client = OpenAI( api_key=self.api_key, base_url=self.base_url ) response = client.embeddings.create( model=self.model_name, input=["test"] ) self._dimension = len(response.data[0].embedding) except Exception as e: raise ValueError(f"Failed to load Embedding API model: {e}")
@property defdimension(self) -> int: """Get the dimension of embeddings produced by this function""" self._ensure_model_loaded() return self._dimension
def__call__(self, input: Documents) -> Embeddings: """ Generate embeddings using Embedding API. Args: input: Single document (str) or list of documents (List[str]) Returns: List of embedding vectors """ # Handle single string input ifisinstance(input, str): input = [input]
defget_seekdb_collection(client, collection_name: str = "embeddings", embedding_function: Optional[EmbeddingFunction] = DefaultEmbeddingFunction(), drop_if_exists: bool = True): """ Get or create a collection using pyseekdb's get_or_create_collection. Args: client: seekdb client instance collection_name: Name of the collection embedding_function: Embedding function (required for automatic embedding generation) drop_if_exists: Whether to drop existing collection if it exists Returns: Collection object """ if drop_if_exists and client.has_collection(collection_name): print(f"Collection '{collection_name}' already exists, deleting old data...") client.delete_collection(collection_name)
if embedding_function isNone: raise ValueError("embedding_function is required")
definsert_embeddings(collection, data: List[Dict[str, Any]]): """ Insert data into collection. Embeddings are automatically generated by collection's embedding_function. Args: collection: Collection object (must have embedding_function configured) data: List of data dictionaries containing 'text', 'source_file', 'chunk_index' """ try: ids = [f"{item['source_file']}_{item.get('chunk_index', 0)}"for item in data] documents = [item['text'] for item in data] metadatas = [{'source_file': item['source_file'], 'chunk_index': item.get('chunk_index', 0)} for item in data]
# Collection's embedding_function will automatically generate embeddings from documents collection.add( ids=ids, documents=documents, metadatas=metadatas )
# 导入单个文档 uv run python seekdb_insert.py ../../README.md
# 或导入目录下的所有 Markdown 文档 uv run python seekdb_insert.py path/to/your_dir
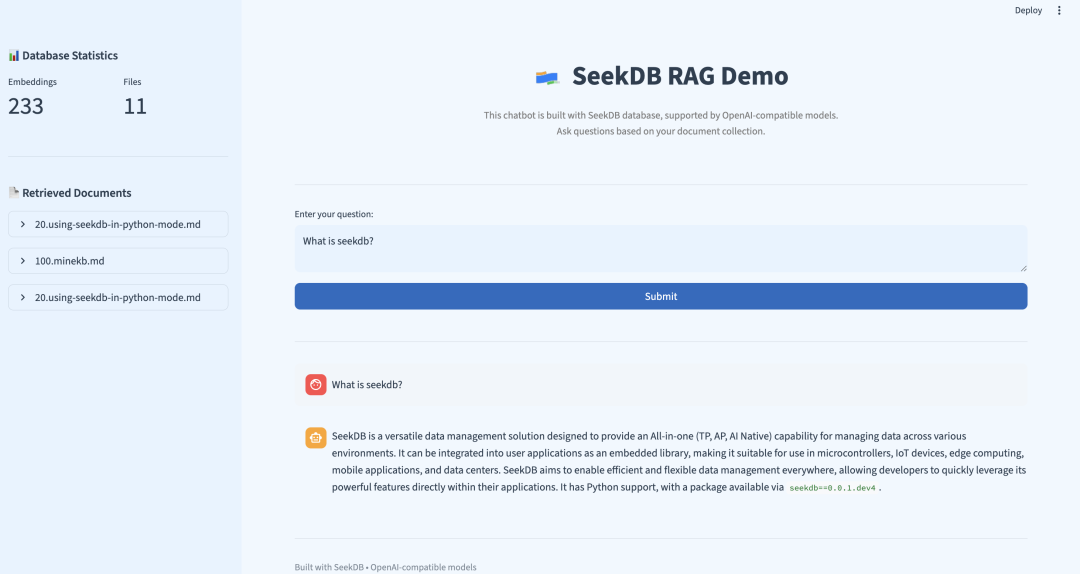
启动应用
在 pyseekdb/demo/rag 路径下执行如下命令,通过 Streamlit 启动应用:
1
uv run streamlit run seekdb_app.py --server.port your_port
使用 IP 和端口号(默认为 8501,可通过 --server.port 选项自定义)即可在浏览器中打开 RAG 界面。
提示:如果使用 uv 作为包管理器,请在命令前加上 uv run 前缀,以确保使用正确的 Python 环境和依赖。
实际运行示例
以下是一个真实的查询示例,展示了 seekdb RAG 系统的实际效果:
用户问题:”What is seekdb’s vector search?”
检索到的相关文档:
1 2 3 4 5 6 7 8
1. 30.experience-vector-retrieval.md Vector search overview In today's era of information explosion, users often need to quickly retrieve the information they need from massive amounts o...
2. 20.using-seekdb-in-python-mode.md Experience vector search SeekDB supports up to 16,000 dimensions of float-type dense vectors, sparse vectors, and various types of vector distance ca...
3. 70.experience-hybrid-vector-index.md Summary Through this tutorial, you have mastered the core features of SeekDB's hybrid vector index: Simplified usage process: Achieve semantic ret...
使用 LLM 生成的答案:
SeekDB’s vector search is a powerful feature that enables efficient and accurate retrieval of data by encoding various types of data—such as text, images, and audio—into mathematical vectors and performing searches in a vector space. This approach captures deep semantic relationships within the data, going beyond traditional keyword-based search methods to deliver more relevant results.
Key capabilities of SeekDB’s vector search include:
High-dimensional vector support: It supports up to 16,000 dimensions for float-type dense vectors and sparse vectors.
Multiple distance metrics: It supports various similarity or distance calculations, including Manhattan distance, Euclidean distance, inner product, and cosine distance.
Advanced indexing methods: Vector indexes can be created using HNSW (Hierarchical Navigable Small World) or IVF (Iterative Virtual File), enabling fast approximate nearest neighbor searches.
Incremental updates: The system allows for real-time insertion and deletion of vectors without compromising search accuracy or recall.
Hybrid search with scalar filtering: Users can combine vector similarity search with traditional attribute-based (scalar) filtering for more precise results.
Flexible access interfaces: SeekDB supports SQL access via MySQL protocol clients in multiple programming languages, as well as a Python SDK.
Automatic embedding and hybrid indexing: With hybrid vector index features, users can store raw text directly—the system automatically converts it into vectors and builds indexes.
In summary, SeekDB’s vector search provides a comprehensive, high-performance solution for semantic search, particularly valuable in AI applications involving large-scale unstructured data.