📖 想拥有自己的智能搜书应用吗?来 https://github.com/oceanbase/seekdb 试试吧!语义搜索、混合检索、RRF 排名……跟着文章一步步来,你会发现 AI 应用开发其实很有趣~
seekdb 是什么样的数据库? 最近体验了一下 seekdb,先说几点感受。
第一,是单节点轻量化设计,在我的 macbook 上通过 docker 桌面端部署可以轻松跑起来,在 Linux 环境下直接用 pip 安装,据说不久就会支持 macOS/windows 系统,连 docker 都省了,直接通过命令安装。
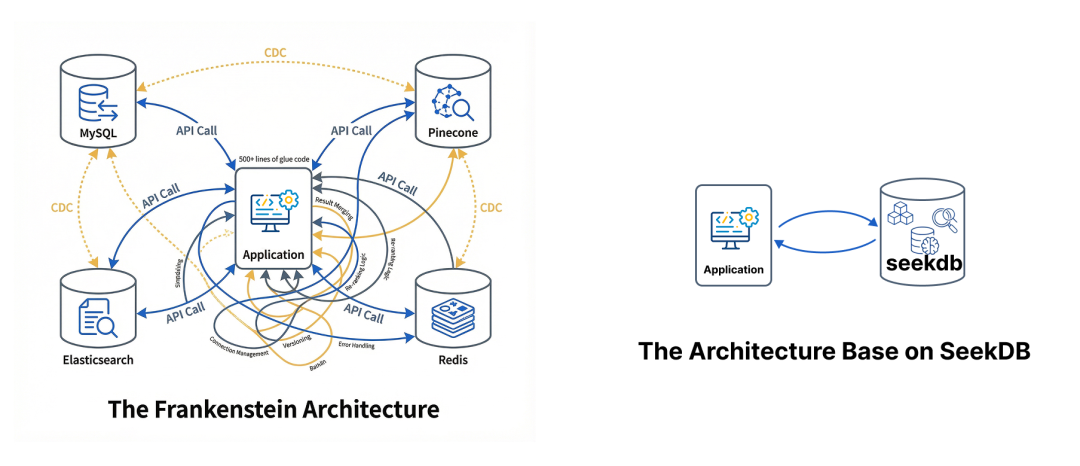
第二,它是一体化设计,原生融合关系型、向量、全文、JSON、GIS 五种类型的数据,所有索引在同一事务内原子更新,这意味着 Zero Data Lag 和严格的 ACID,彻底规避传统 CDC 同步导致的延迟与不一致问题。
第三,它是一个 AI-Native 数据库,体现在它内置有 embedding 模型和 AI Function,单条 SQL 实现向量 + 全文 + 标量过滤的联合查询,不需要再写大量的复杂的胶水层逻辑拼合各种技术栈,直接驱动 RAG 流程(如图)。
第四,它的 API 是 Schema-free 的设计,也就是直接写入,不要求预先定义严格的表结构。
第五,它完全兼容 MySQL,意味着传统数据库可以轻松进行 AI 化升级。
第六点同样很重要,它是在 Apache 2.0 协议许可下开源,同时它有 OceanBase 的基因。长期发展有保障,只会越来越成熟。
教程:基于 seekdb 实现智能搜书应用 本教程将带你从零开始,基于 seekdb 实现一个「智能搜书」的程序,演示如何实现语义搜索和混合搜索等 seekdb 的主要能力。
教程具体做的事情包括:
数据导入
从 csv 文件导入 seekdb
支持数据分批导入
自动将书籍的文本信息转换为 384 维向量嵌入
用到三种搜索能力
语义搜索:基于向量相似度,用自然语言查询找到语义相关的书籍。
元数据过滤:按评分、类型、年份、价格等字段精确过滤。
混合搜索:结合语义搜索 + 元数据过滤,使用 RRF 算法融合排序。
索引优化
创建 HNSW 向量索引提升语义搜索性能。
元数据生成列索引(从 JSON 提取字段创建索引)
技术栈
数据库: seekdb,pyseekdb(seekdb 的 Python SDK),pymysql
数据处理工具:pandas
准备工作 1. 安装 OrbStack OrbStack 是一个轻量级的 Docker 替代品,专为 Mac 优化,启动速度快且资源占用低。用它本地部署 seekdb。
第一步,使用 Homebrew 安装(推荐):
或从官网下载:访问 https://orbstack.dev 下载安装包。
第二步,启动 OrbStack:
1 2 3 4 5 open -a OrbStack orb version
2. 部署 seekdb 镜像 如果卡住,先去 orbstack 配置 docker 国内镜像源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 docker pull oceanbase/seekdb:latest docker run -d \ --name seekdb \ -p 2881:2881 \ -e MODE=slim \ oceanbase/seekdb:latest docker ps | grep seekdb docker logs seekdb
等待约 30 秒让 seekdb 完全启动。你可以通过 docker logs -f seekdb 查看启动日志,看到 “boot success” 表示启动完成。
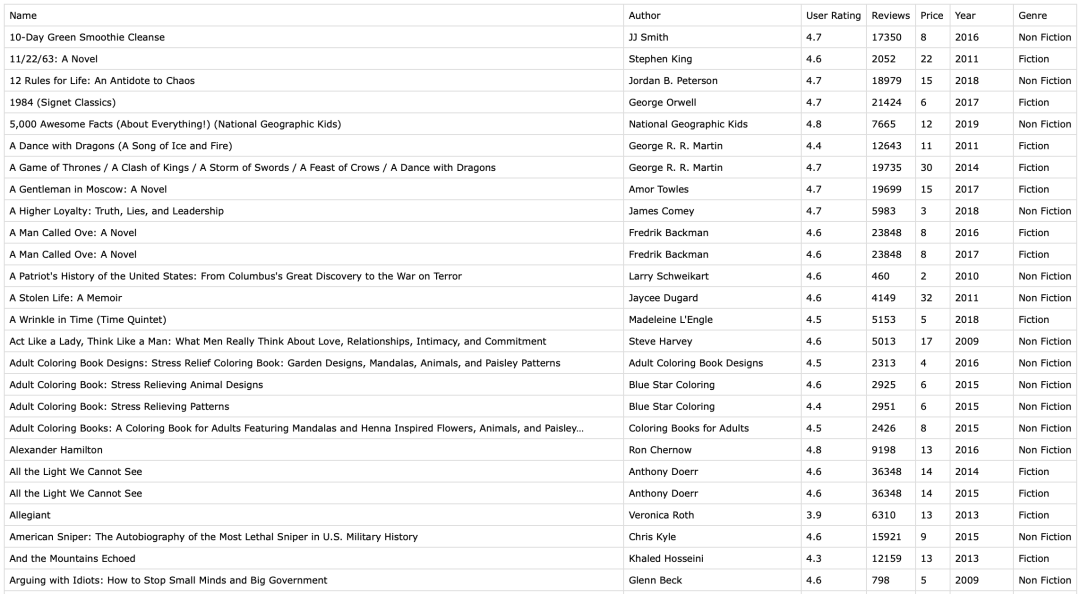
3. 下载数据集 下载数据集:https://www.kaggle.com/datasets/sootersaalu/amazon-top-50-bestselling-books-2009-2019
将数据集命名为:bestsellers_with_categories.csv,有 550 条 amazon 历史畅销书的记录,内容如图:
4. 下载教程代码 1 git clone https://github.com/kejun/demo-seekdb-hybridsearch.git
项目结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 demo-seekdb-books-hybrid-search/ ├── database/ │ ├── db_client.py # 数据库客户端封装 │ └── index_manager.py # 索引管理器 ├── data/ │ └── processor.py # 数据处理器 ├── models/ │ └── book_metadata.py # 书籍元数据模型 ├── utils/ │ └── text_utils.py # 文本处理工具 ├── import_data.py # 数据导入脚本 ├── hybrid_search.py # 混合搜索演示 └── bestsellers_with_categories.csv # 数据文件
创建 Python 虚拟环境:
1 2 3 4 5 6 7 python3 -m venv venv source venv/bin/activate .\venv\Scripts\activate
安装依赖:
1 pip install -r requirements.txt
执行效果 执行 python import_data.py 导入数据。可以看到整个过程:加载数据文件 → 连接数据库 → 创建数据库 → 创建集合 → 分批导入数据 → 创建元数据索引(注:seekdb 目前只支持对 embedding 列创建 HNSW 索引,对 document 列创建全文索引,对元数据字段创建暂不支持,据介绍在计划中)。
seekdb 采用的是 schema-free 的接口设计,比如在 data/processor.py 中,调用 collection.add() 时直接传入任意字典:
1 2 3 4 5 collection.add( ids=valid_ids, documents=valid_documents, metadatas=valid_metadatas )
完整结果(有所精简)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 正在加载数据文件: bestsellers_with_categories.csv 数据加载完成! - 总行数: 550 - 总列数: 7 - 列名: Name, Author, User Rating, Reviews, Price, Year, Genre - 加载耗时: 0.01 秒 正在连接数据库... 主机: 127.0.0.1:2881 数据库: demo_books 集合: book_info 数据库已就绪 数据库连接成功 正在创建/重建集合... 集合名称: book_info 向量维度: 384 距离度量: cosine 集合创建成功 正在处理数据... 数据预处理完成! - 总记录数: 550 - 验证错误数: 0 - 处理耗时: 0.05 秒 正在导入数据到集合... - 批次大小: 100 - 总批次数: 6 - 开始导入... 导入进度: 100%|█████████████████████████████████████| 6/6 [00:53<00:00, 8.97s/批次] 数据导入完成! - 导入耗时: 53.83 秒 - 平均速度: 10 条/秒 正在创建元数据索引... - 索引字段: genre, year, user_rating, author, reviews, price 索引创建完成! - 创建耗时: 3.81 秒 数据导入流程完成! 总耗时: 59.64 秒 导入记录数: 550 数据库: demo_books 集合: book_info
导完数据,可以直接用 mysql client 或安装 obclient 在终端上查询数据库。
1 2 3 4 5 docker exec -it seekdb bash mysql -h127.0.0.1 -P2881 -uroot
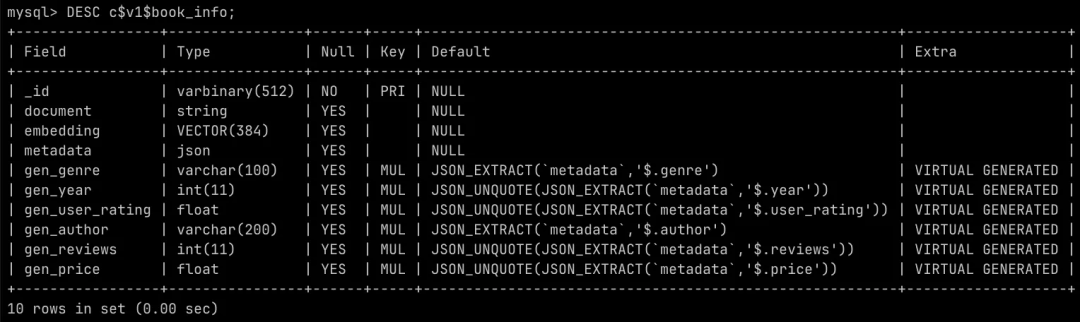
book_info 是 seekdb 的 collection,对应底层的表名是 c$v1$book_info:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 SHOW DATABASES;USE demo; SHOW TABLES;DESC c$v1$articles;SELECT * FROM c$v1$articles LIMIT 10 ;SELECT COUNT (* ) FROM c$v1$articles;EXIT;
看一下表结构 DESC c$v1$book_info:
看一下创建的索引:
(注意:pyseekdb 目前不直接支持对元数据列创建索引,所以项目通过 pymysql + SQL DDL 来实现元数据索引功能。据说在下个 pyseekdb 版本中将会支持自动对元数据字段进行索引)
接下来,执行搜索 python hybrid_search.py。seekdb 内置的 embedding 模型是 sentence-transformers/all-MiniLM-L6-v2,向量维度最大 384,要想获得更好的效果还是要配置外部的模型服务。
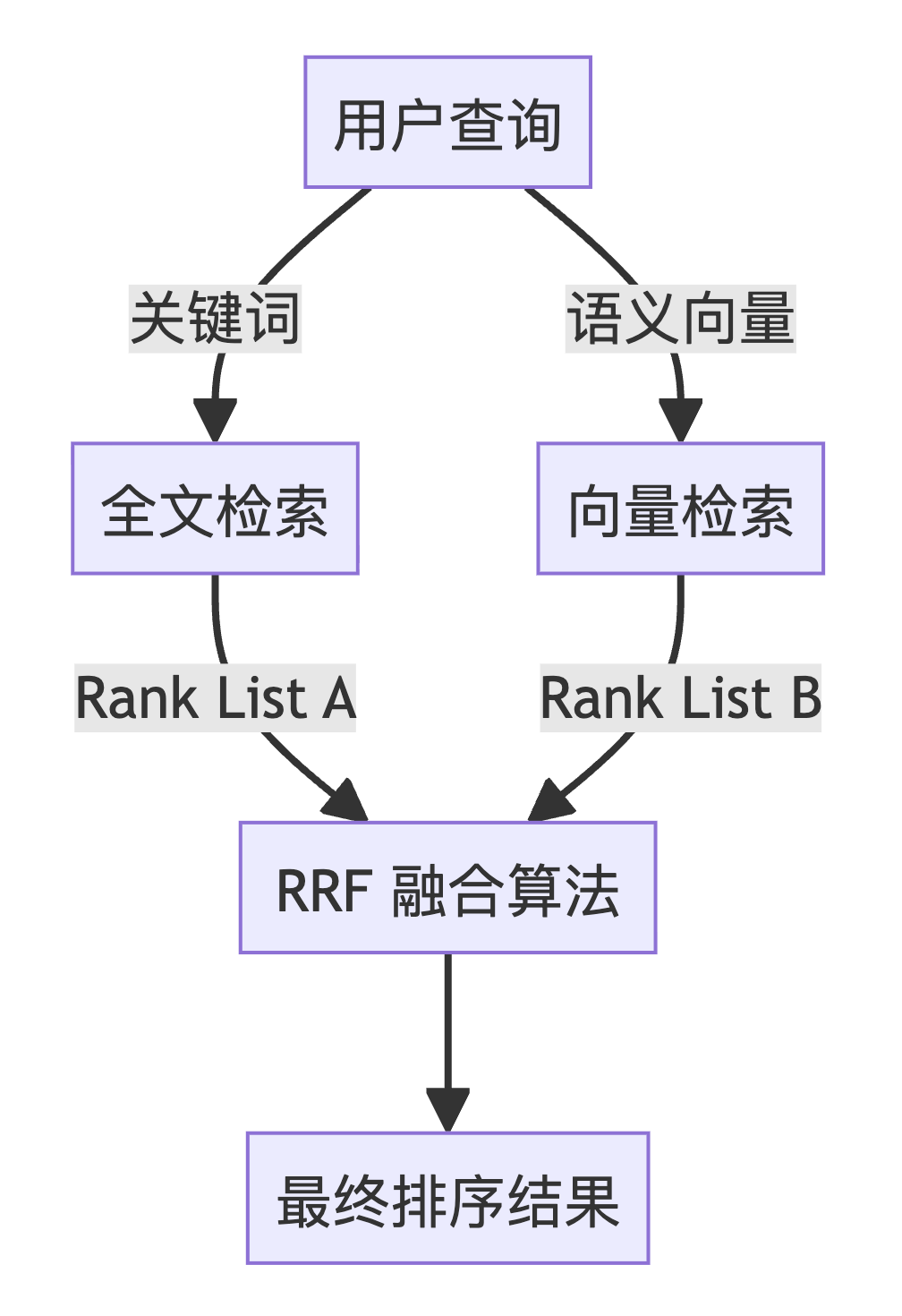
混合搜索是 seekdb 的 killer feature。它同时执行全文检索和向量检索,然后使用 RRF (倒数排名融合) 算法合并。
看具体代码示例,query_params 定义的是全文搜索”励志”(”inspirational”),同时用元数据中的用户评分(user_rating)过滤(评分大于等于 4.5)。knn_params 是语义搜索,query_texts 是句鸡汤”励志人生忠告”(”inspirational life advice”),用同样的用户评分做过滤。
代码片断:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 query_params = { "where_document" : {"$contains" : "inspirational" }, "where" : {"user_rating" : {"$gte" : 4.5 }}, "n_results" : 5 } knn_params = { "query_texts" : ["inspirational life advice" ], "where" : {"user_rating" : {"$gte" : 4.5 }}, "n_results" : 5 } results = collection.hybrid_search( query=query_params, knn=knn_params, rank={"rrf" : {}}, n_results=5 , include=["metadatas" , "documents" , "distances" ] )
可以 vibe-eval 一下结果,感觉是挺准的。完整执行结果(有所精简)如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 === 语义搜索 === Query: ['self improvement motivation success'] 语义搜索 - 找到 5 条结果: [1] The 7 Habits of Highly Effective People: Powerful Lessons in Personal Change 作者: Stephen R. Covey 评分: 4.6 评论数: 9325 价格: $24.0 年份: 2011 类型: Non Fiction 相似度距离: 0.5358 相似度: 0.4642 (省略其它......) === 混合搜索 (评分≥4.5) === Query: {'where_document': {'$contains': 'inspirational'}, 'where': {'user_rating': {'$gte': 4.5}}, 'n_results': 5} KNN Query Texts: ['inspirational life advice'] 混合搜索 (评分≥4.5) - 找到 5 条结果: [1] Mindset: The New Psychology of Success 作者: Carol S. Dweck 评分: 4.6 评论数: 5542 价格: $10.0 年份: 2014 类型: Non Fiction 相似度距离: 0.0159 相似度: 0.9841 (省略其它......) === 混合搜索 (Non Fiction) === Query: {'where_document': {'$contains': 'business'}, 'where': {'genre': 'Non Fiction'}, 'n_results': 5} KNN Query Texts: ['business entrepreneurship leadership'] 混合搜索 (Non Fiction) - 找到 5 条结果: [1] The Five Dysfunctions of a Team: A Leadership Fable 作者: Patrick Lencioni 评分: 4.6 评论数: 3207 价格: $6.0 年份: 2009 类型: Non Fiction 相似度距离: 0.0164 相似度: 0.9836 (省略其它......) === 混合搜索 (Fiction, 2015年后, 评分≥4.0) === Query: {'where_document': {'$contains': 'fiction'}, 'where': {'$and': [{'year': {'$gte': 2015}}, {'user_rating': {'$gte': 4.0}}, {'genre': 'Fiction'}]}, 'n_results': 5} KNN Query Texts: ['fiction story novel'] 混合搜索 (Fiction, 2015年后, 评分≥4.0) - 找到 5 条结果: [1] A Gentleman in Moscow: A Novel 作者: Amor Towles 评分: 4.7 评论数: 19699 价格: $15.0 年份: 2017 类型: Fiction 相似度距离: 0.0154 相似度: 0.9846 (省略其它......) === 混合搜索 (评论数≥10000) === Query: {'where_document': {'$contains': 'popular'}, 'where': {'reviews': {'$gte': 10000}}, 'n_results': 10} KNN Query Texts: ['popular bestseller'] 混合搜索 (评论数≥10000) - 找到 10 条结果: [1] Twilight (The Twilight Saga, Book 1) 作者: Stephenie Meyer 评分: 4.7 评论数: 11676 价格: $9.0 年份: 2009 类型: Fiction 相似度距离: 0.0143 相似度: 0.9857 [2] 1984 (Signet Classics) 作者: George Orwell 评分: 4.7 评论数: 21424 价格: $6.0 年份: 2017 类型: Fiction 相似度距离: 0.0145 相似度: 0.9855 [3] Last Week Tonight with John Oliver Presents A Day in the Life of Marlon Bundo (Better Bundo Book, LGBT Childrens Book) 作者: Jill Twiss 评分: 4.9 评论数: 11881 价格: $13.0 年份: 2018 类型: Fiction 相似度距离: 0.0147 相似度: 0.9853 (省略其它......)
Vibe Coding 友好 如果你用 Cursor 或 Claude Code 开发一定装了 context7-mcp,它会查询最新的 API 文档、代码示例等,是 #Vibecoding 的最佳伴侣。我看到 seekdb 也被添加到 Context7 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 { "mcpServers" : { "context7" : { "command" : "npx" , "args" : [ "-y" , "@upstash/context7-mcp" , "--api-key" , "<你在context7上创建的apiKey>" ] } } }
装完之后,你就可以边学边用了。
希望这篇教程有助于你更顺利的上手 #seekdb。Enjoy!