从神经元到代码工程:PowerMem 记忆系统的遗忘设计
大自然为生物设计了记忆和遗忘系统。我们希望将其翻译成可以配置和调优的代码。
🧠 如果你也想让自己的 AI Agent 拥有”省token、更聪明”的记忆能力,不妨来 https://github.com/oceanbase/powermem 逛逛~ PowerMem 已经帮你把遗忘的学问变成了可调参的代码,开箱即用!
为什么需要遗忘
如果 AI Agent 将所有我说过的话都记住,会是一个什么样的场景?乍一听很合理。但事实是,真正真实可靠的 memory 并不是将所有内容都记住就万事大吉。在记住的同时,遗忘是很重要的事情。在 Agent 的记忆系统中也一样,遗忘不是缺陷,而是能力。
欢迎大家关注 OceanBase 社区公众号 “老纪的技术唠嗑局”。认知科学和工程实践都有一个结论:没有遗忘的记忆系统不是更强大,而是更低效。原因很简单:
- 检索质量衰减:新旧记忆在语义空间中相互干扰,高频无关结果稀释了精准匹配。随着记忆体量增长,检索信噪比持续下降。
- 存储成本不可控:无限累积的记忆需要无限存储,且大部分低价值信息永远不会被检索,造成资源浪费。
PowerMem 对于遗忘机制有很精妙的设计,它决定了记忆何时消亡和记忆在检索时的排序权重。
1. 大自然的遗忘设计,从神经元到认知系统
1.1 突触可塑性
在神经科学层面,记忆的物质基础是神经元之间的突触连接。
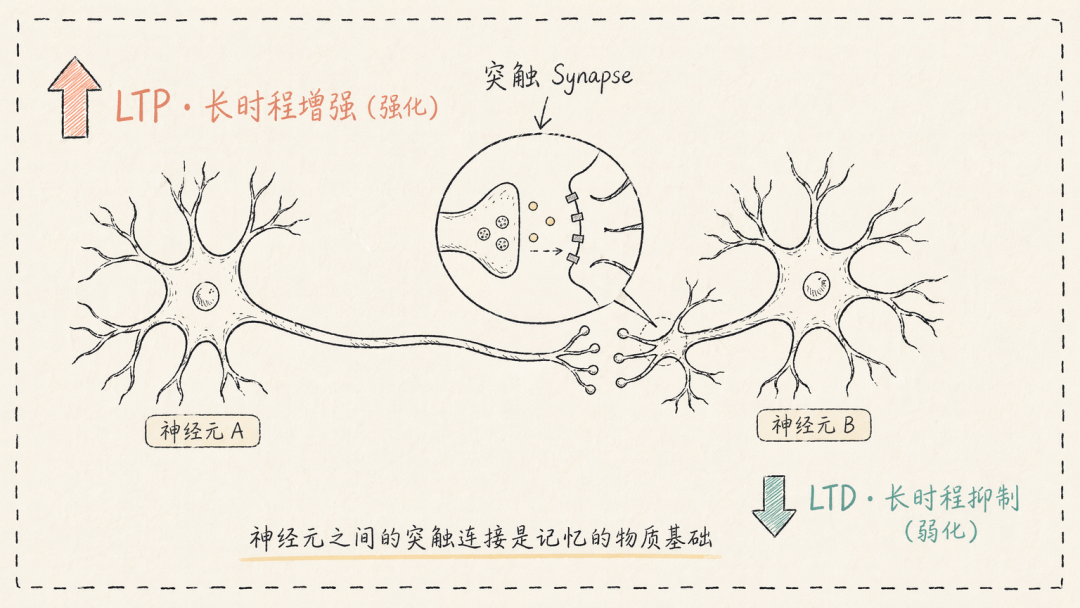
连接不是静态的,它受两种对立机制的持续调控:
- 长时程增强(LTP):高频使用某个神经通路时,对应突触连接被强化,这是记忆的生物学基础。
- 长时程抑制(LTD):低频使用某个神经通路时,对应突触连接被削弱,这是遗忘的生物学基础。
如果所有突触都被同等强化,神经网络将彻底失去区分信号与噪音的能力。LTD 通过选择性削弱不活跃连接,将有限的突触资源集中于活跃通路。遗忘是记忆系统获得分辨力的代价。
1.2 海马体到新皮层的筛选
再进一步的机制是记忆巩固(Memory Consolidation)。新形成的记忆首先暂存在海马体中;接着在睡眠阶段,大脑通过**记忆重放(Memory Replay)**将海马体中的记忆逐步转移至新皮层进行长期存储。
海马体类似于计算机的 RAM,容量有限、读写快速,但保持时间短。
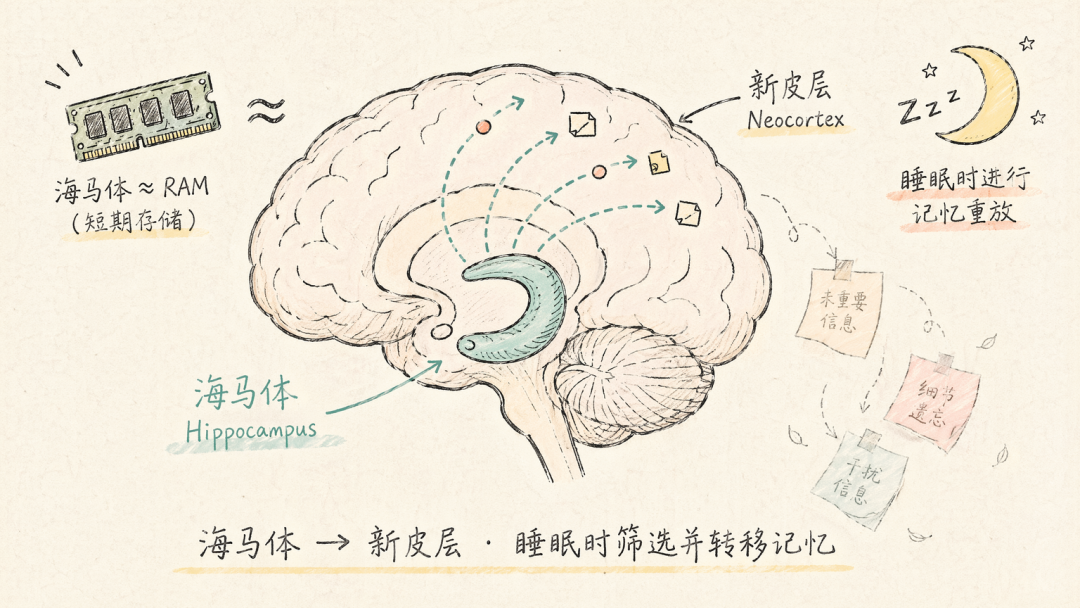
但这个转移不是全量的。只有那些在清醒时被反复激活的、与已有知识建立了丰富关联的、或伴随强烈情绪体验的信息,才能获得优先转移权。孤立、单次、缺乏情绪标记的信息,则在转移过程中自然脱落。
这个机制是 PowerMem 三层记忆模型(working → short_term → long_term)的生物学蓝本。
1.3 遗忘不是因为存不进去,而是取不出来
干扰理论揭示的核心事实是,记忆的困难不在于存不进去,而在于取不出来。且随着存储信息越来越多,记忆之间的交叉干扰呈指数级增长。遗忘机制的作用就是通过衰减低价值记忆,降低检索空间中的干扰密度。
2. 香农的信息论视角:遗忘是一台信息过滤器
2.1 信息量的数学定义
1 | I(x) = -log₂(p(x)) |
一个事件的信息量与其发生概率成反比,越是罕见、出人意料的事件,携带的信息量越大。
2.2 映射到记忆系统
- 昨天吃的什么早餐 → 每天都在发生,概率 p≈1 → 不值得长期存储
- 公司数据库的主密码 → 极少被问及,p 极小 → 必须持久化保留
所以一套完善的遗忘机制实质上是一台信息过滤器。
3. 艾宾浩斯遗忘曲线
3.1 把记忆变成可测量的数据
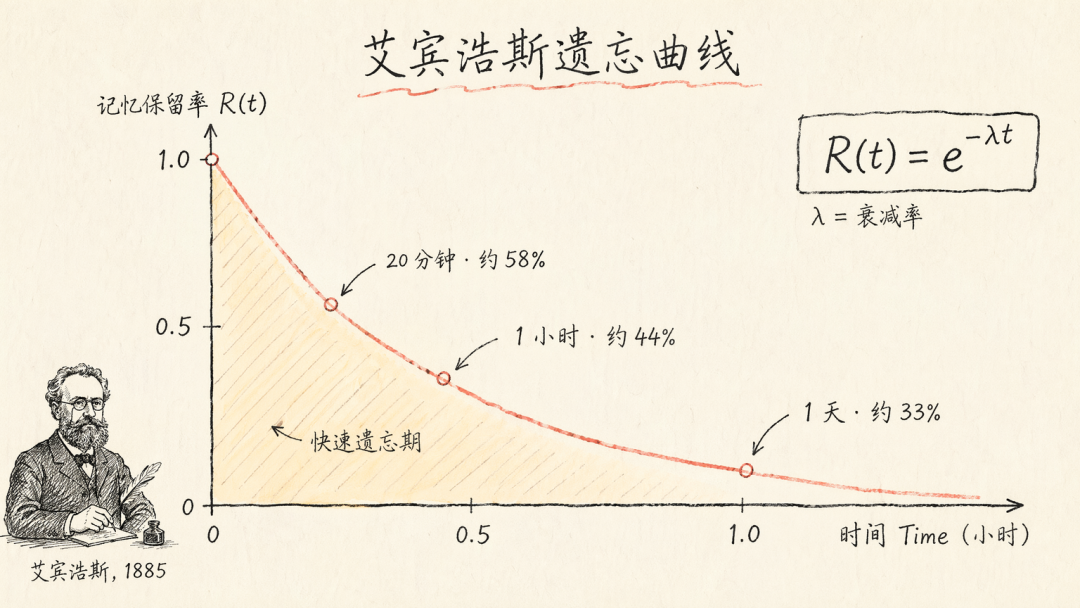
1885 年艾宾浩斯以自己为被试,发明了约 2300 个无意义音节进行实验:
| 时间间隔 | 记忆保留率 |
|---|---|
| 刚学完 | 100% |
| 20 分钟 | ~58% |
| 1 小时 | ~44% |
| 9 小时 | ~36% |
| 1 天 | ~33% |
| 2 天 | ~28% |
| 6 天 | ~25% |
| 31 天 | ~21% |
两个至今未被推翻的结论:遗忘是先快后慢的指数曲线;复习可以改写曲线。
3.2 现代指数衰减模型
1 | R(t) = e^(-λt) |
遗忘的核心特征是,遗忘的速度与当前还保留的记忆量成正比。
3.4 间隔重复与理想的困难
艾宾浩斯还有一个发现:间隔重复可以重置遗忘曲线,而且每次重置后的衰减速度比上一次更慢。Robert Bjork 于 1994 年提出的 “理想的困难”(Desirable Difficulty) 概念精确描述了这一现象:刚好费力到足以刺激适应的提取,才是最高效的学习方式。
4. PowerMem 的三层记忆架构
4.1 从生物学到代码的映射
| 层级 | 生物学类比 | 衰减速率倍率 | 典型存活时间 | 晋升条件 |
|---|---|---|---|---|
| working(工作记忆) | 前额叶皮层 | ×2.0 | 数小时~1 天 | access≥3 或 importance≥0.6 |
| short_term(短期记忆) | 海马体 | ×1.5 | 数天~数周 | access≥3 或 importance≥0.6 |
| long_term(长期记忆) | 新皮层 | ×1.0 | 数周~数月 | —(已在顶层) |
分类逻辑:importance≥0.8→long_term, ≥0.6→short_term, <0.6→working。衰减倍率是核心差异化参数。
4.2 遗忘管理全局架构
- ImportanceEvaluator:判断信息重要性,输出 0.0~1.0 分数
- EbbinghausAlgorithm:衰减计算、复习调度、遗忘/晋升/归档决策
- EbbinghausIntelligencePlugin:在记忆创建、访问、搜索关键节点注入管理逻辑
- MemoryOptimizer:精确去重(MD5)+ 语义去重(余弦相似度)+ 记忆压缩(LLM)
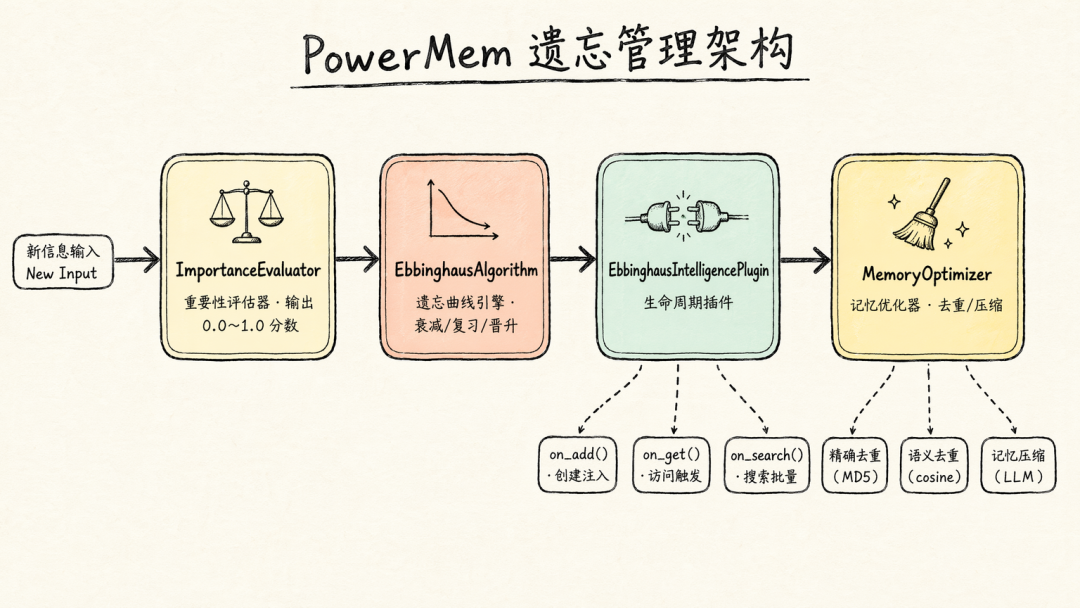
4.3 遗忘不只是删除
搜索结果按以下公式排序:final_score = relevance_score × decay_factor
遗忘不是单纯的删除开关,而是检索质量的调节器。
总结:为什么需要遗忘
遗忘是排序的基础,通过衰减制造差异化。遗忘使记忆进化,频繁访问的记忆被不断巩固。遗忘是连续的,而非二元的——从 1.0 到 0.0 的连续衰减谱系,这是更符合人类记忆的工作方式。
大自然是这么设计的,PowerMem 将其翻译成了可以配置、调优、理解的代码。
PowerMem 的 GitHub 地址:https://github.com/oceanbase/powermem
本文基于 PowerMem v1.1.1 版本进行撰写。
