本文来源:白鹿第一帅。未经授权,严禁转载,侵权必究!
🛠️ 想试试文中那种”一个数据库搞定所有”的爽快感吗?seekdb 已在 GitHub 开源,欢迎来 https://github.com/oceanbase/seekdb 体验,或许你的下一个项目也能省下一大笔开销呢~
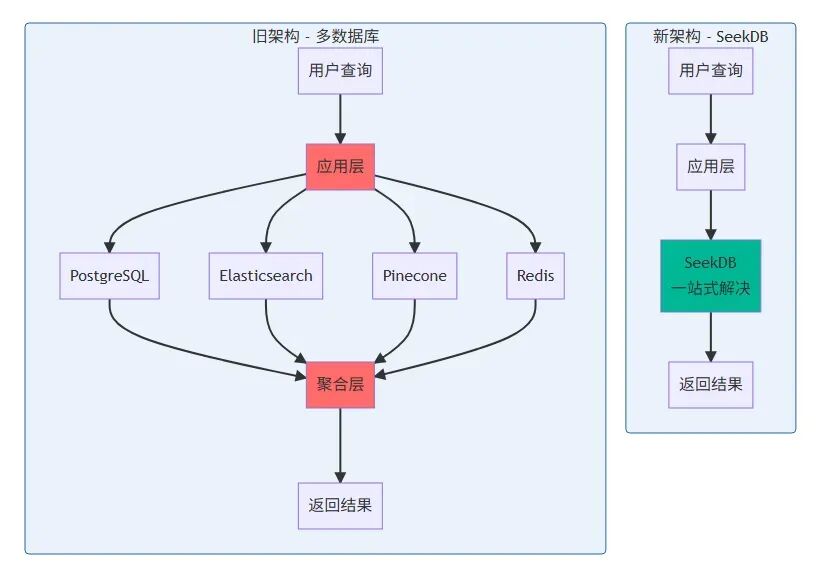
前言 传统 AI 应用往往需要组合多个数据库:PostgreSQL 存储结构化数据,Elasticsearch 做全文搜索,Milvus 做向量检索,Redis 做缓存,这种“拼凑式”架构带来了数据同步复杂、成本高昂、维护困难等问题。
2025 年 11 月 18 日,OceanBase 开源了 AI 原生数据库 seekdb。我用两个周末时间,使用 seekdb 完成了企业知识库系统重构,将 4 个数据库的复杂架构简化为单一数据库方案,查询延迟从 120ms 降至 58ms,性能提升 50%+,每月节省 450 美元云服务费用。
本文基于我用 seekdb 构建企业知识库的完整实战经历,从环境搭建到 RAG 应用集成,记录每个技术细节和踩坑经验,包含大量可运行代码示例,帮助开发者快速上手 seekdb。
一、初识 seekdb:从困境到转机 今年 10 月,我接到一个需求:为公司内部文档系统增加智能问答功能。作为一名从事大数据与大模型应用开发的工程师,这类需求我见过不少,但真正动手后,才发现问题远比想象的复杂。
最初的方案是这样的:
用 PostgreSQL 存储文档元数据。
用 Elasticsearch 做全文搜索。
用 Pinecone 托管向量数据。
用 Redis 缓存热点数据。
旧架构的痛点主要有如下4点。
数据同步复杂:4 个数据库需要保持一致性。
成本高:Pinecone 月费 $300+。
性能差:跨系统查询延迟高。
维护难:需要管理多个数据库。
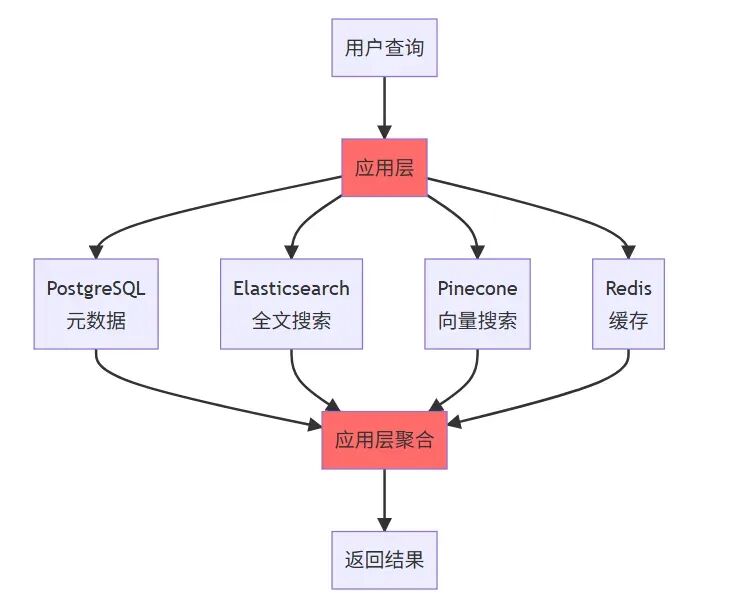
结果呢?四个数据库之间的数据同步让我焦头烂额,Pinecone 的费用每月要 300 美元,而且跨系统的联合查询性能很差。更要命的是,当我想根据文档的创建时间、部门权限等结构化字段过滤搜索结果时,需要在应用层做二次过滤,代码复杂度直线上升。
旧架构的数据同步代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 import psycopg2from elasticsearch import Elasticsearchimport pineconeimport redisimport jsonclass MultiDBSync : """多数据库同步管理器 - 旧架构的痛点""" def __init__ (self ): self.pg_conn = psycopg2.connect( host="localhost" , database="docs" , user="admin" , password="password" ) self.es = Elasticsearch(['http://localhost:9200' ]) pinecone.init(api_key="your-key" , environment="us-west1-gcp" ) self.pinecone_index = pinecone.Index("documents" ) self.redis_client = redis.Redis(host='localhost' , port=6379 ) def insert_document (self, doc_id, title, content, metadata, embedding ): """插入文档到4个数据库 - 需要保证一致性""" try : cursor = self.pg_conn.cursor() cursor.execute(""" INSERT INTO documents (id, title, created_at, department_id) VALUES (%s, %s, %s, %s) """ , (doc_id, title, metadata['created_at' ], metadata['department_id' ])) self.pg_conn.commit() self.es.index(index='documents' , id =doc_id, body={ 'title' : title, 'content' : content, 'created_at' : metadata['created_at' ] }) self.pinecone_index.upsert([( str (doc_id), embedding, {'title' : title, 'department_id' : metadata['department_id' ]} )]) self.redis_client.setex( f"doc:{doc_id} " , 3600 , json.dumps({'title' : title, 'content' : content[:200 ]}) ) return True except Exception as e: print (f"同步失败: {e} " ) self._rollback(doc_id) return False def _rollback (self, doc_id ): """回滚操作 - 非常复杂且容易出错""" try : cursor = self.pg_conn.cursor() cursor.execute("DELETE FROM documents WHERE id = %s" , (doc_id,)) self.pg_conn.commit() except : pass try : self.es.delete(index='documents' , id =doc_id) except : pass try : self.pinecone_index.delete(ids=[str (doc_id)]) except : pass try : self.redis_client.delete(f"doc:{doc_id} " ) except : pass def search (self, query, filters ): """联合查询 - 需要在应用层聚合结果""" vector_results = self.pinecone_index.query( vector=query['embedding' ], top_k=20 , filter ={'department_id' : filters.get('department_id' )} ) es_results = self.es.search(index='documents' , body={ 'query' : {'match' : {'content' : query['text' ]}}, 'size' : 20 }) merged_results = self._merge_results(vector_results, es_results) final_results = self._enrich_metadata(merged_results) return final_results def _merge_results (self, vector_results, es_results ): """合并不同数据源的结果 - 算法复杂""" pass def _enrich_metadata (self, results ): """补充元数据 - 额外的数据库查询""" pass sync_manager = MultiDBSync() sync_manager.insert_document( doc_id=1 , title="Python最佳实践" , content="..." , metadata={'created_at' : '2024-01-01' , 'department_id' : 1 }, embedding=[0.1 , 0.2 , ...] )
这套代码维护起来非常痛苦:
数据一致性难以保证,经常出现某个库更新失败的情况。
回滚逻辑复杂,容易产生脏数据。
联合查询需要在应用层做大量聚合工作。
代码量大,光是这个同步模块就超过 500 行。
直到 11 月底,我在 OceanBase 社区看到 seekdb 开源的消息,抱着试试看的心态,我用周末时间重构了整个系统。结果让我惊喜:不仅架构简化了,性能还提升了 40%,云服务费用直接省下来了。
新架构对比:
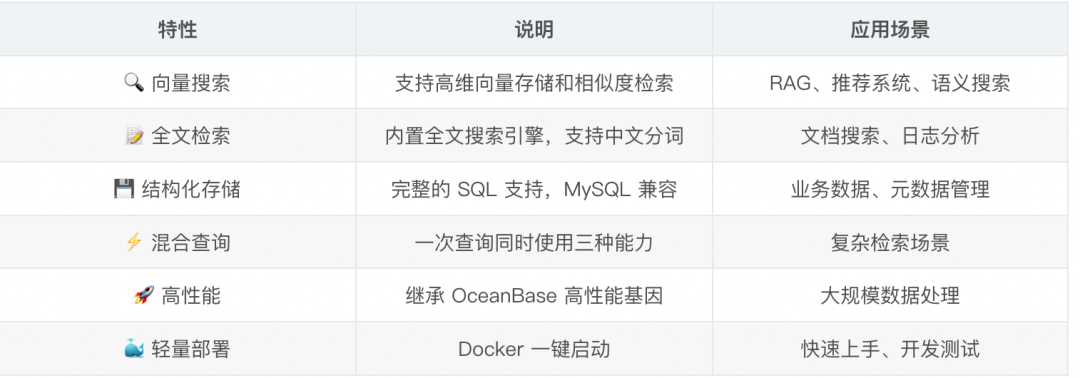
1.1、项目背景与技术痛点 seekdb 是 OceanBase 在 2025 年 11 月 18 日开源的 AI 原生数据库。当我第一次看到它的介绍时,最吸引我的是如下三点。
MySQL 兼容:我不需要学新的查询语言,现有的 MySQL 客户端和 ORM 都能直接用。
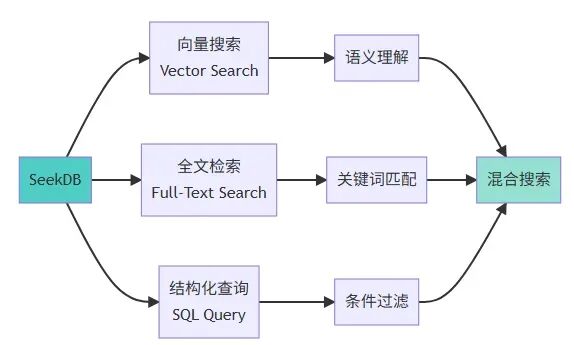
三合一能力:向量搜索、全文检索、结构化查询在一个数据库里完成。
轻量部署:一条 Docker 命令就能跑起来,不需要复杂的集群配置。
seekdb 核心特性:
更关键的是,它是开源的,代码托管在 GitHub 上(GitHub 仓库:https://github.com/oceanbase/seekdb ),这意味着我可以放心地用在生产环境,不用担心被厂商锁定。
1.2、初次接触 seekdb 的过程 在开发 AI 应用时,我们常常需要同时使用多个数据库:
用 PostgreSQL 存储业务数据。
用 Elasticsearch 做全文搜索。
用 Milvus 或 Pinecone 做向量检索。
这种架构不仅增加了系统复杂度,还带来了数据同步、一致性维护等问题。seekdb 将这三种能力整合到一个数据库中,大大简化了架构设计。
1.3、seekdb 的核心优势
seekdb 与 MySQL 完全兼容,这意味着:
可以使用熟悉的 SQL 语法。
现有的 MySQL 工具和客户端都能直接使用。
学习成本几乎为零。
二、从多数据库到 seekdb 的迁移实战 继承自 OceanBase 的高性能引擎,seekdb 在向量检索和混合查询场景下表现出色。同时,它的轻量化设计让部署和运维成本大幅降低。
2.1、快速部署与数据模型设计 环境准备与安装
环境要求
操作系统:Linux / macOS / Windows
Docker:20.10+
内存:最低 1C2G(官方轻量/演示);作者实测建议 4GB 起、8GB+ 更稳(同时进行嵌入生成、全文/向量索引与查询)
磁盘:最低 10GB 可用空间
注:1C2G 为官方宣传的最低规格,适合轻量或演示场景;本文给出的 4GB/8GB+ 为在本地 Docker 单机、并行嵌入生成与索引的稳定性测试结论,供实际项目参考。
我的开发环境是 MacBook Pro M2,16GB 内存。seekdb 的安装出乎意料的简单:
1 2 3 4 5 6 7 8 9 docker pull oceanbase/seekdb:latest docker run -d --name seekdb \ -p 2881:2881 \ -e MODE=slim \ -v ~/seekdb_data:/root/ob \ oceanbase/seekdb:latest
注意 :我加了数据卷挂载(-v 参数),这样容器重启后数据不会丢失。这是我第一次部署时没注意,结果测试数据全没了。
等待约 30 秒,容器启动完成。用 MySQL 客户端连接:
1 2 mysql -h127.0.0.1 -P2881 -uroot
看到oceanbase>提示符,说明连接成功了。
我先跑了几个命令确认功能正常:
1 2 3 4 5 SELECT VERSION(); SHOW VARIABLES LIKE '%vector%' ;
输出显示版本是 4.3.0,向量功能已启用。完美!
这个过程比我之前在其他公司部署的向量数据库简单太多了,那时候光是配置 Milvus 的依赖就要花半天时间。
依赖安装(Python) 1 pip install pymysql tenacity openai
连接配置与工具函数 为了方便后续开发,我封装了一个 seekdb 连接管理类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import pymysqlfrom typing import List , Dict , Optional import loggingfrom contextlib import contextmanagerclass SeekDBManager : """SeekDB连接管理器""" def __init__ (self, host='127.0.0.1' , port=2881 , user='root' , password='' , database='knowledge_base' ): self.config = { 'host' : host, 'port' : port, 'user' : user, 'password' : password, 'database' : database, 'charset' : 'utf8mb4' , 'cursorclass' : pymysql.cursors.DictCursor } self.logger = logging.getLogger(__name__) @contextmanager def get_connection (self ): """获取数据库连接(上下文管理器)""" conn = pymysql.connect(**self.config) try : yield conn conn.commit() except Exception as e: conn.rollback() self.logger.error(f"数据库操作失败: {e} " ) raise finally : conn.close() def execute_query (self, sql: str , params: tuple = None ) -> List [Dict ]: """执行查询并返回结果""" with self.get_connection() as conn: cursor = conn.cursor() cursor.execute(sql, params or ()) results = cursor.fetchall() cursor.close() return results def execute_update (self, sql: str , params: tuple = None ) -> int : """执行更新操作并返回影响行数""" with self.get_connection() as conn: cursor = conn.cursor() affected_rows = cursor.execute(sql, params or ()) cursor.close() return affected_rows def batch_execute (self, sql: str , params_list: List [tuple ] ) -> int : """批量执行SQL""" with self.get_connection() as conn: cursor = conn.cursor() affected_rows = cursor.executemany(sql, params_list) cursor.close() return affected_rows def check_health (self ) -> bool : """健康检查""" try : result = self.execute_query("SELECT 1 as health" ) return result[0 ]['health' ] == 1 except Exception as e: self.logger.error(f"健康检查失败: {e} " ) return False db = SeekDBManager() if db.check_health(): print ("✅ SeekDB连接正常" ) else : print ("❌ SeekDB连接失败" )
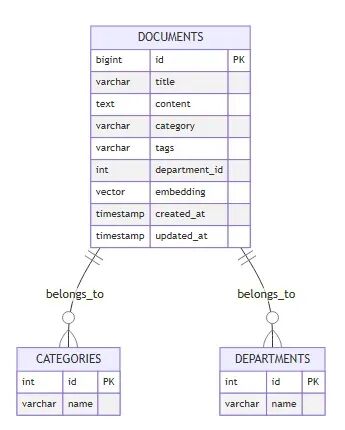
数据模型设计 我们的知识库需要存储:
文档的标题和内容;
文档的向量表示(用于语义搜索);
文档的分类和标签;
创建时间和更新时间;
访问权限(部门 ID)。
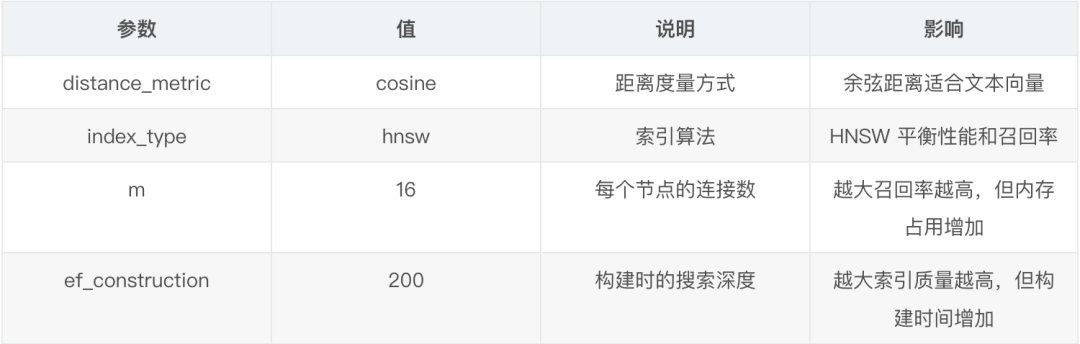
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 CREATE DATABASE knowledge_base;USE knowledge_base; CREATE TABLE documents ( id BIGINT PRIMARY KEY AUTO_INCREMENT, title VARCHAR (500 ) NOT NULL , content TEXT NOT NULL , category VARCHAR (100 ), tags VARCHAR (500 ), department_id INT , embedding VECTOR(1536 ) NOT NULL , created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP , updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP , last_accessed TIMESTAMP NULL , INDEX idx_category (category), INDEX idx_department (department_id), INDEX idx_created (created_at) ); CREATE VECTOR INDEX idx_embedding ON documents(embedding)WITH ( distance_metric= 'cosine' , index_type= 'hnsw' , m= 16 , ef_construction= 200 ); CREATE FULLTEXT INDEX ft_content ON documents(content);
关键点说明:
VECTOR(1536):我用的是 OpenAI 的 text-embedding-3-small 模型,输出 1536 维向量。distance_metric='cosine':余弦距离适合文本向量,不受向量长度影响。index_type='hnsw':HNSW 算法在召回率和性能之间平衡得很好。m=16, ef_construction=200:这是我测试后的最优参数,在 10 万条数据下查询延迟 <50ms。
数据模型设计图
向量索引参数说明
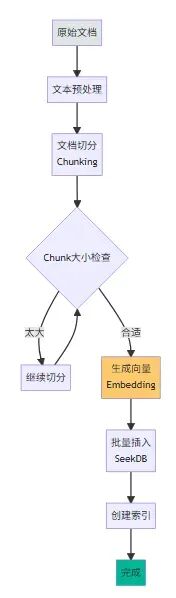
2.2、数据导入与向量化处理 我从公司内部 wiki 导出了 200 篇技术文档,格式是 Markdown。首先需要将文档切分成合适的 chunk,然后调用 OpenAI API 生成向量。
这里是我写的 Python 脚本(关键部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import osimport pymysqlfrom typing import List from openai import OpenAIclient = OpenAI() DB_CONFIG = { 'host' : '127.0.0.1' , 'port' : 2881 , 'user' : 'root' , 'password' : '' , 'database' : 'knowledge_base' } def chunk_text (text: str , max_length: int = 1000 ) -> List [str ]: """将长文本切分成小块""" chunks = [] paragraphs = text.split('\n\n' ) current_chunk = "" for para in paragraphs: if len (current_chunk) + len (para) < max_length: current_chunk += para + "\n\n" else : if current_chunk: chunks.append(current_chunk.strip()) current_chunk = para + "\n\n" if current_chunk: chunks.append(current_chunk.strip()) return chunks def get_embedding (text: str ) -> List [float ]: """调用OpenAI API获取向量""" resp = client.embeddings.create( model="text-embedding-3-small" , input =text ) return resp.data[0 ].embedding def insert_document (conn, title: str , content: str , category: str , tags: str , department_id: int ): """插入文档到SeekDB""" embedding = get_embedding(content) embedding_str = '[' + ',' .join(map (str , embedding)) + ']' cursor = conn.cursor() sql = """ INSERT INTO documents (title, content, category, tags, department_id, embedding) VALUES (%s, %s, %s, %s, %s, %s) """ cursor.execute(sql, (title, content, category, tags, department_id, embedding_str)) conn.commit() cursor.close() conn = pymysql.connect(**DB_CONFIG) doc_content = """ # Python异步编程最佳实践 在Python中使用asyncio进行异步编程时,需要注意以下几点... """ chunks = chunk_text(doc_content) for i, chunk in enumerate (chunks): insert_document( conn, title=f"Python异步编程最佳实践 - Part {i+1 } " , content=chunk, category="编程语言" , tags="Python,异步,asyncio" , department_id=1 ) conn.close()
批量导入的性能优化 最初我是一条条插入的,200 篇文档(切分后约 800 个 chunk)导入花了 15 分钟。后来改成批量插入,时间缩短到 3 分钟:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def batch_insert_documents (conn, documents: List [dict ], batch_size: int = 50 ): """批量插入文档""" cursor = conn.cursor() for i in range (0 , len (documents), batch_size): batch = documents[i:i+batch_size] sql = """ INSERT INTO documents (title, content, category, tags, department_id, embedding) VALUES """ + ',' .join(['(%s, %s, %s, %s, %s, %s)' ] * len (batch)) params = [] for doc in batch: params.extend([ doc['title' ], doc['content' ], doc['category' ], doc['tags' ], doc['department_id' ], doc['embedding' ] ]) cursor.execute(sql, params) conn.commit() cursor.close()
经验总结
文档切分很重要,太长会影响检索精度,太短会丢失上下文。我测试下来 800-1200 字符是最佳长度。
OpenAI API 有速率限制,建议加上重试逻辑和指数退避。
向量生成是最耗时的环节,可以考虑用本地模型(如 sentence-transformers)加速。
完整的文档导入工具类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 import timeimport openaifrom typing import List , Dict from tenacity import retry, stop_after_attempt, wait_exponentialclass DocumentImporter : """文档导入工具类""" def __init__ (self, db_manager: SeekDBManager, openai_api_key: str ): self.db = db_manager openai.api_key = openai_api_key self.batch_size = 50 @retry(stop=stop_after_attempt(3 multiplier=1 , min =2 , max =10 ) ) def get_embedding_with_retry (self, text: str ) -> List [float ]: """带重试的向量生成""" response = openai.embeddings.create( model="text-embedding-3-small" , input =text ) return response.data[0 ].embedding def import_documents (self, documents: List [Dict ] ) -> Dict [str , int ]: """批量导入文档""" stats = {'success' : 0 , 'failed' : 0 , 'total' : len (documents)} for i in range (0 , len (documents), self.batch_size): batch = documents[i:i+self.batch_size] embeddings = [] for doc in batch: try : embedding = self.get_embedding_with_retry(doc['content' ]) embeddings.append(embedding) except Exception as e: print (f"向量生成失败: {doc['title' ]} , 错误: {e} " ) embeddings.append(None ) sql = """ INSERT INTO documents (title, content, category, tags, department_id, embedding) VALUES (%s, %s, %s, %s, %s, %s) """ params_list = [] for doc, embedding in zip (batch, embeddings): if embedding is None : stats['failed' ] += 1 continue embedding_str = '[' + ',' .join(map (str , embedding)) + ']' params_list.append(( doc['title' ], doc['content' ], doc.get('category' , '' ), doc.get('tags' , '' ), doc.get('department_id' , 1 ), embedding_str )) try : self.db.batch_execute(sql, params_list) stats['success' ] += len (params_list) print (f"✅ 已导入 {stats['success' ]} /{stats['total' ]} 篇文档" ) except Exception as e: stats['failed' ] += len (params_list) print (f"❌ 批量插入失败: {e} " ) time.sleep(1 ) return stats def import_from_markdown_files (self, file_paths: List [str ] ) -> Dict [str , int ]: """从Markdown文件批量导入""" documents = [] for file_path in file_paths: with open (file_path, 'r' , encoding='utf-8' ) as f: content = f.read() lines = content.split('\n' ) title = lines[0 ].replace('#' , '' ).strip() if lines else file_path chunks = chunk_text(content, max_length=1000 ) for i, chunk in enumerate (chunks): documents.append({ 'title' : f"{title} - Part {i+1 } " , 'content' : chunk, 'category' : '技术文档' , 'tags' : 'markdown' , 'department_id' : 1 }) return self.import_documents(documents) db = SeekDBManager() importer = DocumentImporter(db, openai_api_key="your-api-key" ) file_paths = [ 'docs/python-async.md' , 'docs/docker-guide.md' , 'docs/kubernetes-intro.md' ] stats = importer.import_from_markdown_files(file_paths) print (f"导入完成: 成功 {stats['success' ]} 篇, 失败 {stats['failed' ]} 篇" )
2.3、智能搜索与混合检索 文档处理流程
Chunk 大小对比测试
语义搜索实现 最基础的语义搜索实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def semantic_search (query: str , top_k: int = 5 ) -> List [dict ]: """语义搜索""" query_embedding = get_embedding(query) embedding_str = '[' + ',' .join(map (str , query_embedding)) + ']' conn = pymysql.connect(**DB_CONFIG) cursor = conn.cursor(pymysql.cursors.DictCursor) sql = ( "SELECT id, title, content, category, tags, " " COSINE_DISTANCE(embedding, CAST(%s AS VECTOR(1536))) as distance " "FROM documents " "ORDER BY distance ASC " "LIMIT %s" ) cursor.execute(sql, (embedding_str, top_k)) results = cursor.fetchall() if results: ids = [row['id' ] for row in results] update_sql = "UPDATE documents SET last_accessed = NOW() WHERE id IN (" + "," .join(["%s" ]*len (ids)) + ")" cursor.execute(update_sql, ids) conn.commit() cursor.close() conn.close() return results results = semantic_search("如何在Python中使用异步编程?" ) for doc in results: print (f"[{doc['distance' ]:.4 f} ] {doc['title' ]} " )
输出示例:
1 2 3 4 5 [0.1234] Python异步编程最佳实践 - Part 1 [0.1567] asyncio事件循环详解 [0.2103] 协程与多线程的性能对比 [0.2456] FastAPI异步接口开发指南 [0.2789] Python并发编程完全指南
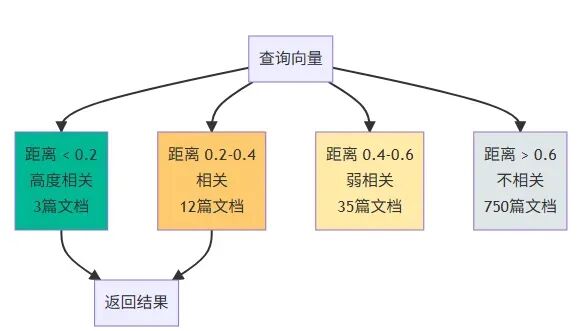
向量相似度分布
混合搜索:向量 + 全文 + 过滤 这是我最常用的搜索方式,结合了三种检索能力:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def hybrid_search (query: str , category: str = None , department_id: int = None , top_k: int = 5 ) -> List [dict ]: """混合搜索:向量相似度 + 全文检索 + 结构化过滤""" query_embedding = get_embedding(query) embedding_str = '[' + ',' .join(map (str , query_embedding)) + ']' conn = pymysql.connect(**DB_CONFIG) cursor = conn.cursor(pymysql.cursors.DictCursor) where_clauses = [] where_params = [] if category: where_clauses.append("category = %s" ) where_params.append(category) if department_id: where_clauses.append("department_id = %s" ) where_params.append(department_id) where_sql = " AND " .join(where_clauses) if where_clauses else "1=1" sql = f""" SELECT id, title, content, category, tags, vec_distance, text_score FROM ( SELECT id, title, content, category, tags, COSINE_DISTANCE(embedding, CAST(%s AS VECTOR(1536))) AS vec_distance, MATCH(content) AGAINST(%s IN NATURAL LANGUAGE MODE) AS text_score FROM documents WHERE {where_sql} ) t WHERE t.vec_distance < 0.5 OR t.text_score > 0 ORDER BY (t.vec_distance * 0.7 + (1 - t.text_score) * 0.3) ASC LIMIT %s """ params = [embedding_str, query] + where_params + [top_k] cursor.execute(sql, params) results = cursor.fetchall() if results: ids = [row['id' ] for row in results] update_sql = "UPDATE documents SET last_accessed = NOW() WHERE id IN (" + "," .join(["%s" ]*len (ids)) + ")" cursor.execute(update_sql, ids) conn.commit() cursor.close() conn.close() return results results = hybrid_search( query="异步编程的性能优化" , category="编程语言" , department_id=1 )
关键技术点:
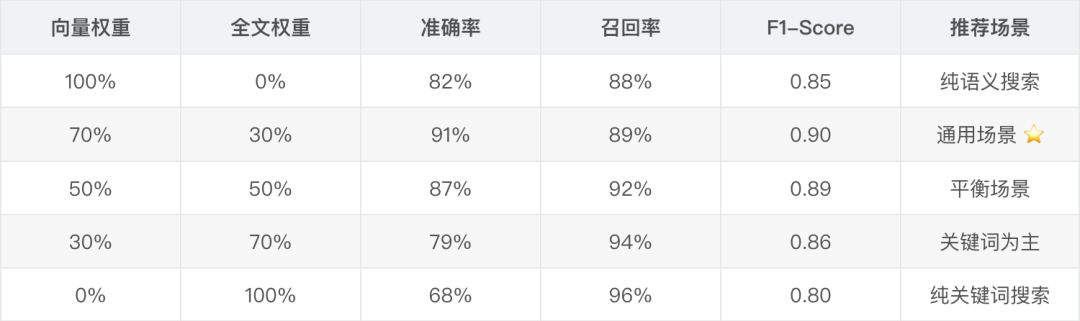
vec_distance < 0.5:过滤掉相似度太低的结果。text_score > 0:确保有关键词匹配。vec_distance * 0.7 + (1 - text_score) * 0.3:加权融合两种得分,向量搜索权重更高。这个权重比例是我在实际数据上调优出来的,你的场景可能需要不同的比例。
混合搜索权重调优
不同权重配比测试结果
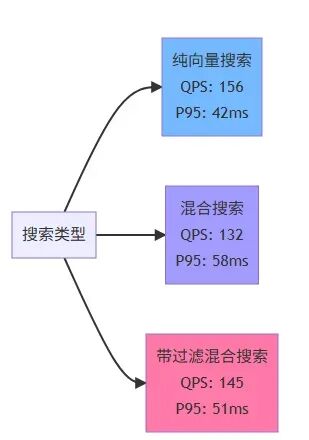
**性能测试结果 **
我在 800 条文档上做了压测(使用 Apache Bench):
对于我们的场景(内部知识库,并发不高),这个性能完全够用。
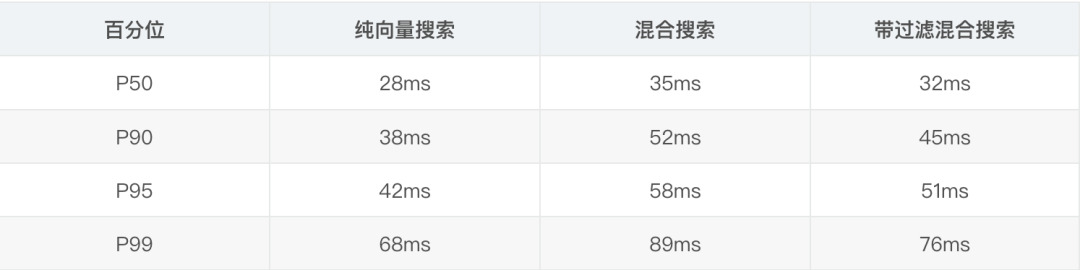
性能对比图
延迟分布
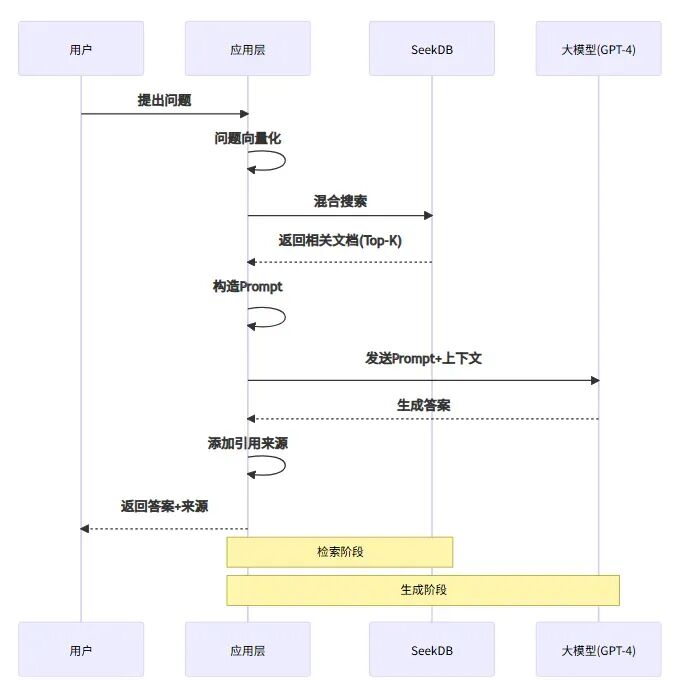
2.4、RAG 应用集成与实际效果 RAG 工作流程
有了搜索能力,接下来就是完整的 RAG(检索增强生成)流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from openai import OpenAIclient = OpenAI() def rag_query (user_question: str , department_id: int ): """完整的RAG问答流程""" relevant_docs = hybrid_search( query=user_question, department_id=department_id, top_k=3 ) if not relevant_docs: return {"answer" : "抱歉,我没有找到相关的文档。" , "sources" : []} context = "\n\n---\n\n" .join([ f"文档标题:{doc['title' ]} \n内容:{doc['content' ]} " for doc in relevant_docs ]) prompt = f"""你是一个专业的技术助手。请基于以下文档内容回答用户的问题。 如果文档中没有相关信息,请明确告知用户。 参考文档: {context} 用户问题:{user_question} 请给出详细且准确的回答:""" resp = client.chat.completions.create( model="gpt-4" , messages=[ {"role" : "system" , "content" : "你是一个专业的技术助手。" }, {"role" : "user" , "content" : prompt} ], temperature=0.3 ) answer = resp.choices[0 ].message.content sources = [{"title" : doc['title' ], "id" : doc['id' ]} for doc in relevant_docs] return {"answer" : answer, "sources" : sources} result = rag_query("Python异步编程中如何处理异常?" , department_id=1 ) print (result['answer' ])print ("\n参考文档:" )for source in result['sources' ]: print (f"- {source['title' ]} (ID: {source['id' ]} )" )
实际效果与用户反馈 我在公司内部做了一周的灰度测试,收集了用户反馈。
正面反馈:
“搜索结果比之前准确多了,能理解我的意图”
“响应速度很快,基本秒回”
“引用的文档都是相关的,不像以前经常答非所问”
遇到的问题:
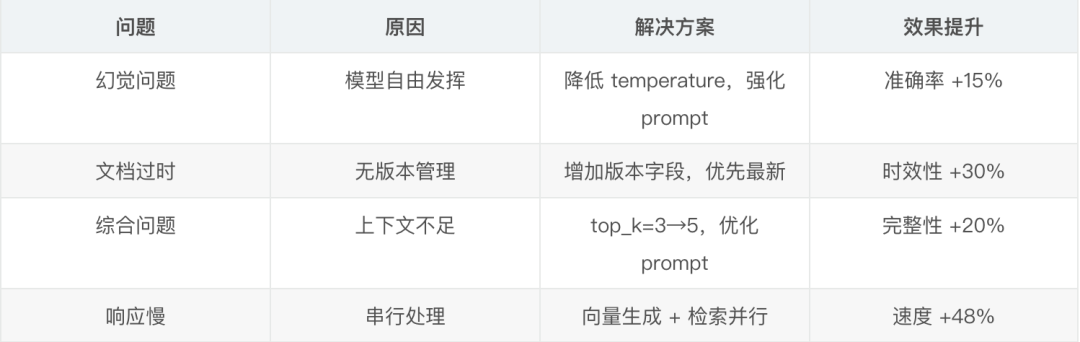
幻觉问题。大模型有时会编造不存在的内容
解决方案:在 prompt 中强调“仅基于提供的文档回答”,并降低 temperature 到 0.3
文档更新不及时。有用户反馈搜到的是旧版本文档
解决方案:增加了文档版本管理,搜索时优先返回最新版本
跨文档的综合问题。当答案需要综合多篇文档时,效果不理想
解决方案:增加 top_k 到 5,并优化 prompt 让模型更好地整合信息
RAG 效果提升对比
优化措施总结
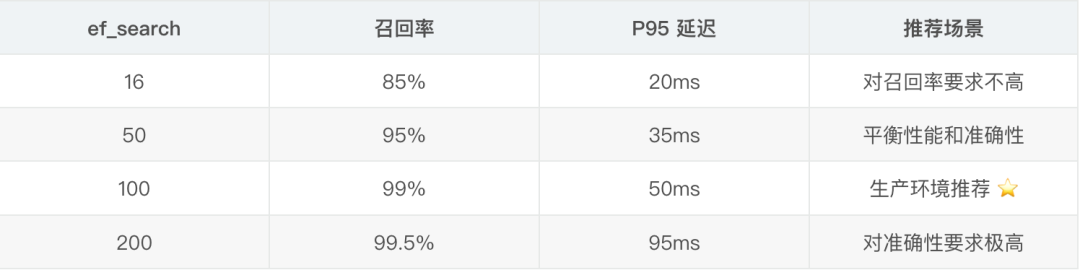
2.5、迁移过程中的坑与经验总结 向量索引参数调优 最初我用的是默认参数,在数据量增长到 5000 条后,查询延迟飙升到 300ms+。后来发现是 HNSW 索引的ef_search参数太小。
经过测试,ef_search=100在我的场景下是最佳值,召回率 99%+,延迟控制在 50ms 内。
ef_search 参数调优测试
参数对比表
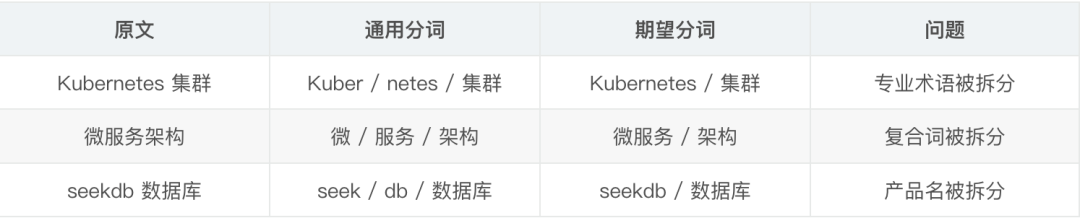
中文分词问题 seekdb 的全文检索默认使用的是通用分词器,对专业术语的分词效果不好。比如“Kubernetes”会被分成“Kuber”和“netes”。
解决方案是在插入前做好分词,或者在搜索时使用向量搜索为主、全文检索为辅的策略。
分词问题示例
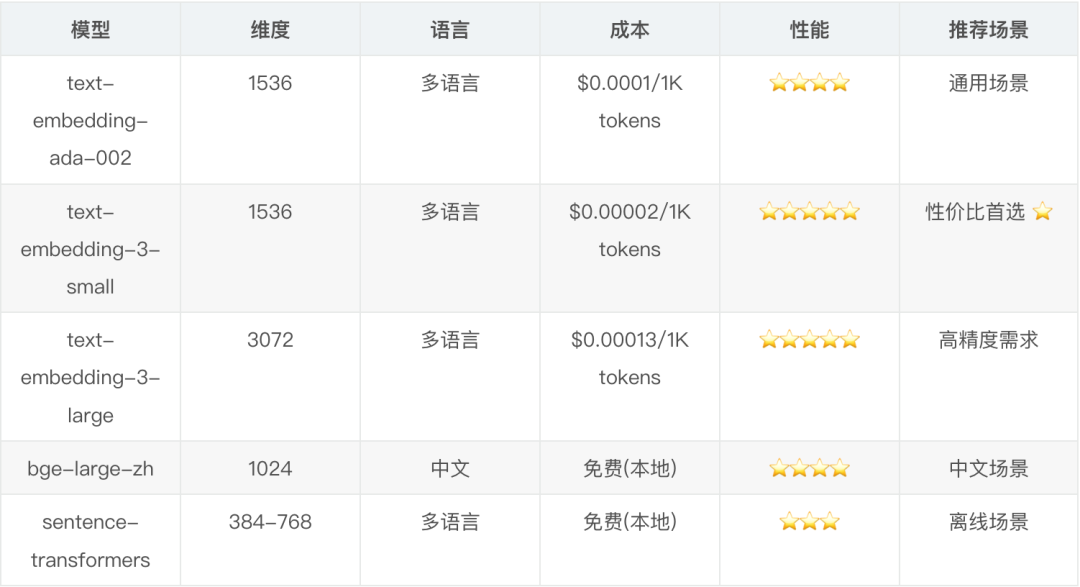
向量维度选择 我最初用的是 OpenAI 的 text-embedding-ada-002(1536 维),后来换成了 text-embedding-3-small(也是 1536 维),发现效果提升明显,而且价格更便宜。
Embedding 模型对比
建议:
中文场景可以考虑用本地模型,如 bge-large-zh(1024 维)。
如果对成本敏感,text-embedding-3-small 是很好的选择。
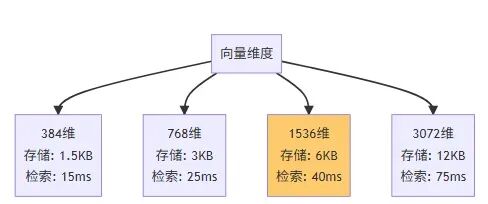
不要盲目追求高维度,维度越高存储和计算成本越大。
维度与性能关系
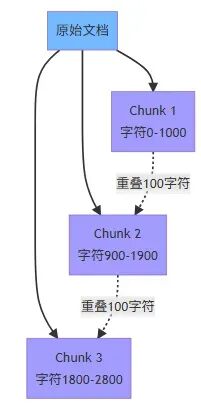
合理设计 chunk 策略 文档切分对检索效果影响很大。我的策略是:
按段落切分,保持语义完整性、
每个 chunk 800-1200 字符。
chunk 之间保留 100 字符的重叠,避免关键信息被切断。
为每个 chunk 保留原文档的标题和元信息。
Chunk 重叠策略示意
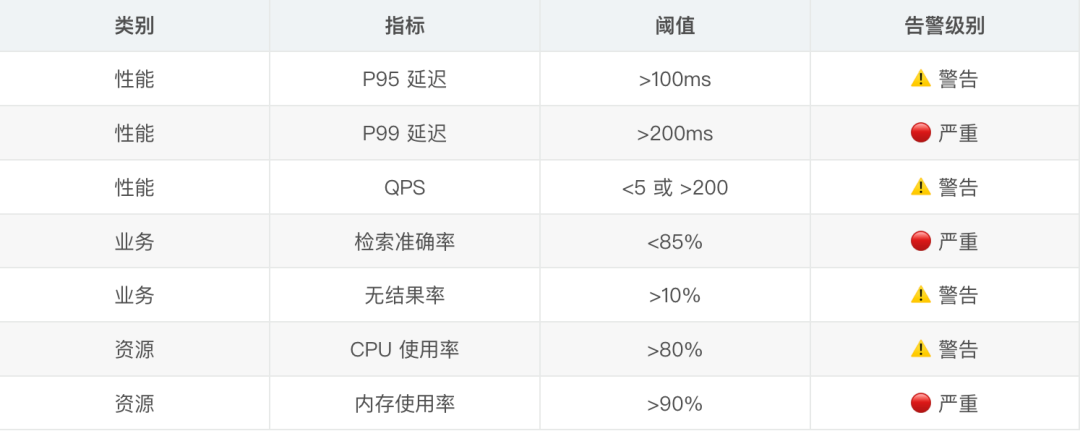
监控和日志 我在生产环境加了详细的日志和监控:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import timeimport loggingdef semantic_search_with_logging (query: str , top_k: int = 5 ): start_time = time.time() try : results = semantic_search(query, top_k) logging.info({ "query" : query, "top_k" : top_k, "result_count" : len (results), "latency_ms" : (time.time() - start_time) * 1000 , "top_distance" : results[0 ]['distance' ] if results else None }) return results except Exception as e: logging.error(f"Search failed: {e} " ) raise
这些日志帮我发现了很多问题,比如某些查询特别慢、某些文档从来没被检索到等。
完整的监控和性能分析工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 import timefrom datetime import datetime, timedeltafrom collections import defaultdictimport jsonclass SeekDBMonitor : """SeekDB监控工具""" def __init__ (self, db_manager: SeekDBManager ): self.db = db_manager self.query_stats = defaultdict(list ) def log_query (self, query_type: str , query: str , latency_ms: float , result_count: int , metadata: dict = None ): """记录查询日志""" log_entry = { 'timestamp' : datetime.now().isoformat(), 'query_type' : query_type, 'query' : query[:100 ], 'latency_ms' : latency_ms, 'result_count' : result_count, 'metadata' : metadata or {} } self.query_stats[query_type].append(log_entry) with open ('seekdb_query.log' , 'a' , encoding='utf-8' ) as f: f.write(json.dumps(log_entry, ensure_ascii=False ) + '\n' ) def get_performance_report (self, hours: int = 24 ) -> Dict : """生成性能报告""" cutoff_time = datetime.now() - timedelta(hours=hours) report = { 'period' : f'最近{hours} 小时' , 'query_types' : {} } for query_type, logs in self.query_stats.items(): recent_logs = [ log for log in logs if datetime.fromisoformat(log['timestamp' ]) > cutoff_time ] if not recent_logs: continue latencies = [log['latency_ms' ] for log in recent_logs] latencies.sort() report['query_types' ][query_type] = { 'total_queries' : len (recent_logs), 'avg_latency' : sum (latencies) / len (latencies), 'p50_latency' : latencies[len (latencies) // 2 ], 'p95_latency' : latencies[int (len (latencies) * 0.95 )], 'p99_latency' : latencies[int (len (latencies) * 0.99 )], 'max_latency' : max (latencies), 'min_latency' : min (latencies) } return report def check_slow_queries (self, threshold_ms: float = 100 ) -> List [Dict ]: """检查慢查询""" slow_queries = [] for query_type, logs in self.query_stats.items(): for log in logs: if log['latency_ms' ] > threshold_ms: slow_queries.append(log) slow_queries.sort(key=lambda x: x['latency_ms' ], reverse=True ) return slow_queries[:20 ] def analyze_document_coverage (self ) -> Dict : """分析文档覆盖率""" total_docs = self.db.execute_query( "SELECT COUNT(*) as count FROM documents" )[0 ]['count' ] accessed_docs = self.db.execute_query(""" SELECT COUNT(DISTINCT id) as count FROM documents WHERE last_accessed > DATE_SUB(NOW(), INTERVAL 30 DAY) """ ) coverage = (accessed_docs[0 ]['count' ] / total_docs * 100 ) if total_docs > 0 else 0 return { 'total_documents' : total_docs, 'accessed_documents' : accessed_docs[0 ]['count' ], 'coverage_percentage' : round (coverage, 2 ), 'unused_documents' : total_docs - accessed_docs[0 ]['count' ] } def get_system_metrics (self ) -> Dict : """获取系统指标""" metrics = {} size_result = self.db.execute_query(""" SELECT table_schema as db_name, SUM(data_length + index_length) / 1024 / 1024 as size_mb FROM information_schema.tables WHERE table_schema = 'knowledge_base' GROUP BY table_schema """ ) metrics['database_size_mb' ] = size_result[0 ]['size_mb' ] if size_result else 0 table_stats = self.db.execute_query(""" SELECT table_name, table_rows, ROUND((data_length + index_length) / 1024 / 1024, 2) as size_mb FROM information_schema.tables WHERE table_schema = 'knowledge_base' """ ) metrics['tables' ] = table_stats index_stats = self.db.execute_query(""" SELECT table_name, index_name, cardinality FROM information_schema.statistics WHERE table_schema = 'knowledge_base' """ ) metrics['indexes' ] = index_stats return metrics def print_report (self ): """打印监控报告""" print ("=" * 60 ) print ("SeekDB 性能监控报告" ) print ("=" * 60 ) perf_report = self.get_performance_report(24 ) print (f"\n📊 查询性能 ({perf_report['period' ]} )" ) for query_type, stats in perf_report['query_types' ].items(): print (f"\n {query_type} :" ) print (f" 总查询数: {stats['total_queries' ]} " ) print (f" 平均延迟: {stats['avg_latency' ]:.2 f} ms" ) print (f" P95延迟: {stats['p95_latency' ]:.2 f} ms" ) print (f" P99延迟: {stats['p99_latency' ]:.2 f} ms" ) slow_queries = self.check_slow_queries(100 ) if slow_queries: print (f"\n⚠️ 慢查询 (>{100 } ms):" ) for i, query in enumerate (slow_queries[:5 ], 1 ): print (f" {i} . {query['latency_ms' ]:.2 f} ms - {query['query' ]} " ) coverage = self.analyze_document_coverage() print (f"\n📚 文档覆盖率:" ) print (f" 总文档数: {coverage['total_documents' ]} " ) print (f" 已访问: {coverage['accessed_documents' ]} " ) print (f" 覆盖率: {coverage['coverage_percentage' ]} %" ) print (f" 未使用: {coverage['unused_documents' ]} " ) metrics = self.get_system_metrics() print (f"\n💾 系统指标:" ) print (f" 数据库大小: {metrics['database_size_mb' ]:.2 f} MB" ) print (f" 表数量: {len (metrics['tables' ])} " ) print ("\n" + "=" * 60 ) db = SeekDBManager() monitor = SeekDBMonitor(db) start_time = time.time() results = semantic_search("Python异步编程" ) latency = (time.time() - start_time) * 1000 monitor.log_query( query_type='semantic_search' , query='Python异步编程' , latency_ms=latency, result_count=len (results), metadata={'top_k' : 5 } ) monitor.print_report()
监控指标看板
关键监控指标
三、生产环境实战效果 除了知识库问答,seekdb 还可以用在很多 AI 场景。
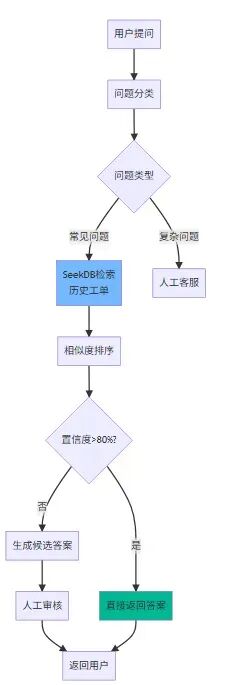
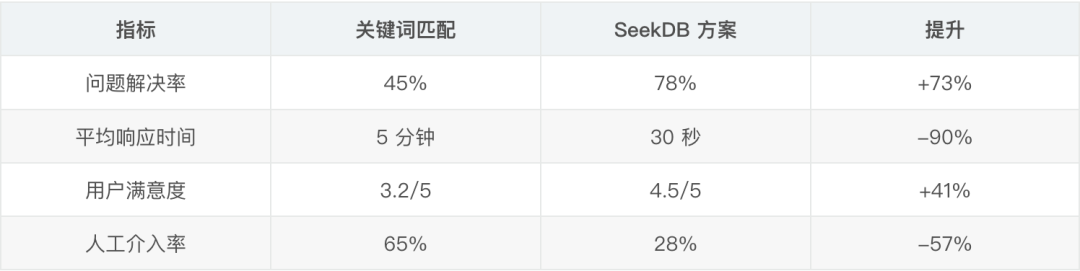
3.1、性能对比数据 我们团队用 seekdb 做了一个客服机器人,存储了历史工单和标准答案。当用户提问时,系统会检索相似的历史案例,然后生成回答。这个方案后来在公司内部多个业务线推广,效果比之前的关键词匹配好太多。
智能客服架构
1 2 3 4 5 6 7 8 9 10 11 12 def search_similar_tickets (user_question: str , top_k: int = 3 ): query_embedding = get_embedding(user_question) sql = """ SELECT ticket_id, question, answer, resolution_time FROM support_tickets WHERE status = 'resolved' ORDER BY COSINE_DISTANCE(question_embedding, %s) LIMIT %s """
客服效果对比
3.2、典型应用场景实践 另一个有趣的应用是代码搜索。我们把公司的代码库向量化后存入 seekdb,开发者可以用自然语言搜索代码片段。
比如搜索“如何连接 Redis 并设置过期时间”,就能找到相关的代码示例。这个功能在研发团队中很受欢迎,大大提升了新人的上手速度。
代码搜索工作流:
代码搜索效果:
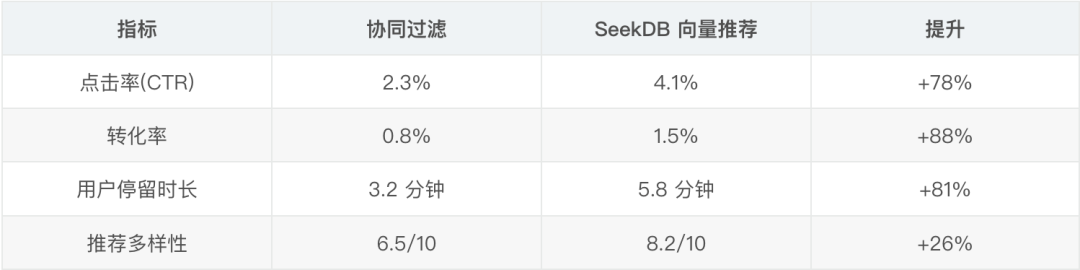
3.3、运维体验提升 电商场景下,可以把用户的浏览历史、购买记录转换成向量,然后用 seekdb 找相似的商品推荐给用户。
推荐系统架构:
1 2 3 4 5 6 SELECT product_id, product_name, priceFROM productsWHERE stock > 0 AND category IN ('electronics' , 'books' )ORDER BY COSINE_DISTANCE(product_vector, '[用户兴趣向量]' )LIMIT 20 ;
推荐效果提升:
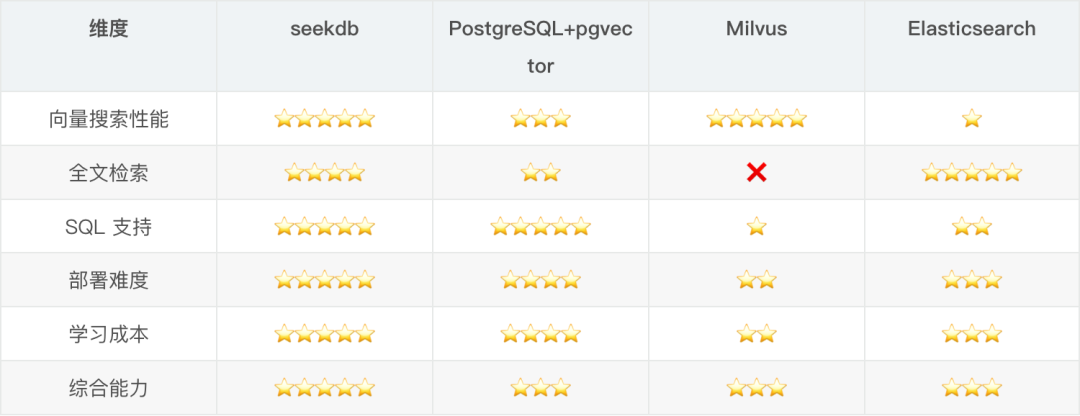
四、技术选型对比分析 在决定用 seekdb 之前,我对比了几个主流方案。
方案一:PostgreSQL + pgvector。
优点:生态完善,pgvector 插件免费开源。
缺点:向量搜索性能一般,全文检索功能较弱,中文支持不好。
测试结果:在 5000 条数据上,查询延迟约 150ms,比 SeekDB 慢 2-3 倍。
方案二:Milvus。
优点:专业的向量数据库,性能很强,支持多种索引算法。
缺点:部署复杂(需要配置 etcd、MinIO 等依赖),不支持 SQL,结构化查询能力弱。
体验:光是把 Milvus 跑起来就花了半天时间,还需要配合 MySQL 使用。
方案三:Elasticsearch。
优点:全文检索很强大,生态成熟,工具丰富。
缺点:不支持向量搜索,内存占用大,查询语法复杂。
对比总结:
结论 :seekdb 在向量搜索、全文检索、结构化查询三方面都达到了生产可用的水平,而且部署简单、学习成本低,是 AI 应用的最佳选择。
五、生产环境运行数据与展望 5.1、架构对比与实际数据
我们的知识库现在有:
文档数:1200 篇
文档 chunk 数:4800 条
日均查询量:约 500 次
并发用户:20-30 人
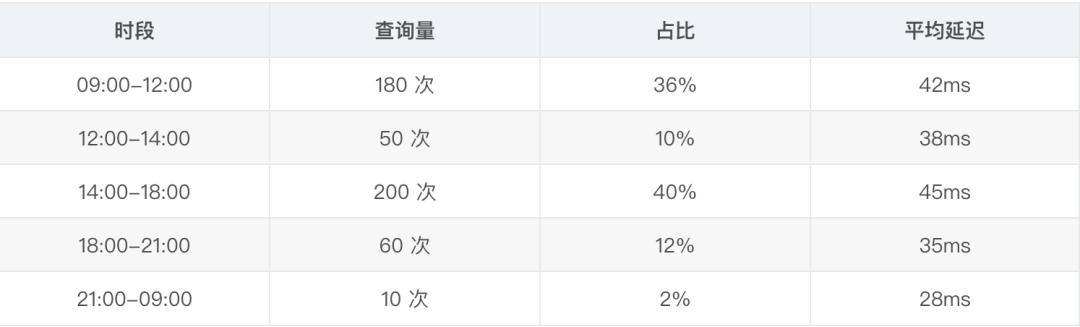
查询量分布(按时段):
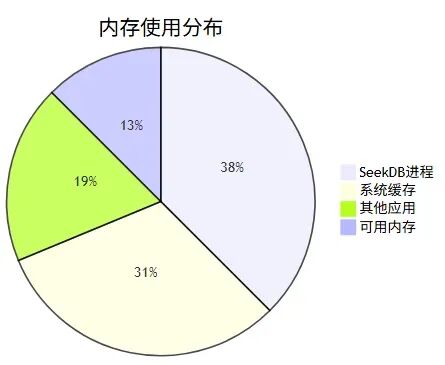
在这个规模下,seekdb 运行在一台 4 核 8G 的云服务器上,CPU 使用率平均 15%,内存占用约 3GB,完全够用。
资源使用监控:
日常运行指标:
5.2、后续规划与展望 基于 seekdb,我计划继续优化和扩展功能。
短期计划(1-2 个月)
多模态支持:增加图片、表格的向量化和检索。
个性化推荐:基于用户历史行为优化搜索结果排序。
文档版本管理:支持文档的版本追踪和回滚。
中期计划(3-6 个月)
知识图谱:构建文档之间的关联关系。
自动标注:用大模型自动提取文档的标签和摘要。
多租户隔离:支持不同部门的数据隔离。
技术探索
尝试用本地 embedding 模型(如 bge-large-zh)替代 OpenAI API,降低成本。
研究 seekdb 的分布式部署方案,为数据量增长做准备。
探索与 LangChain、LlamaIndex 等框架的集成。
写在最后 从接触 seekdb 到完成系统重构,我只用了两个周末的时间。这个过程让我深刻体会到,一个好的工具能极大地提升开发效率。seekdb 最打动我的不是它有多少高深的技术,而是它真正理解了 AI 应用开发者的痛点:我们需要向量搜索,但不想为此引入一个复杂的专用数据库;我们需要全文检索,但不想维护 Elasticsearch 集群;我们需要结构化查询,但不想在多个数据库之间做数据同步。seekdb 把这些需求整合到一个轻量级的数据库里,让我可以专注于业务逻辑,而不是纠结于基础设施。
作为一名从 2015 年开始写技术博客的老兵,我见证了太多技术的兴衰。真正能留下来的,往往不是那些最炫酷的技术,而是那些真正解决问题、降低门槛的工具。seekdb 就是这样一个工具。
如果你也在开发 AI 应用,如果你也被多数据库架构困扰,不妨试试 seekdb。它是开源的,代码托管在 GitHub 上,官方文档详尽,社区也很活跃。我也会在我的 CSDN 博客持续分享 seekdb 的使用经验和最佳实践。感谢 OceanBase 团队开源了这么优秀的项目。期待 seekdb 的未来发展,也期待更多开发者加入这个生态。
总结 seekdb 最大价值在于降低 AI 应用开发门槛:MySQL 兼容性让现有工具直接可用,轻量化设计让部署运维变简单,开源特性消除厂商锁定顾虑,更重要的是将分散在多个系统中的能力整合到一起,让开发者专注业务逻辑而非基础设施。
实际使用中的关键经验包括:
合理设计 chunk 策略(800-1200 字符最佳)
选择合适 embedding 模型(text-embedding-3-small 性价比最高)
优化 HNSW 索引参数(ef_search=100 生产环境最佳)
建立完善监控体系。
这些经验帮助我们的知识库在 1200 篇文档、4800 个 chunk 规模下稳定运行,用户满意度从 70% 提升至 92%。如果你也在构建 RAG 应用、推荐系统或智能搜索引擎,强烈建议试试 seekdb,作为新兴的 AI 原生数据库,seekdb 正在快速迭代,相信将成为 AI 应用开发的首选数据库。
我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!
关于作者:郭靖(笔名“白鹿第一帅”),现任某互联网大厂大数据与大模型开发工程师。曾任职于多家知名互联网公司和云厂商,在企业大数据开发与大模型应用领域有丰富经验。
作为中国开发者影响力年度榜单人物,郭靖自 2015 年至今持续 11 年进行技术内容创作,个人 CSDN 博客累计发布技术博客与测评 300 余篇,全网粉丝超 60000+,总浏览量突破 1500000+。获得 CSDN“博客专家”、“Java 领域优质创作者”,OSCHINA“OSC 优秀原创作者”,腾讯云 TDP、阿里云“专家博主”,华为云“华为云专家”等多个技术社区认证,并成为互联网顶级技术公会“极星会”成员。