AI 时代,OceanBase 为什么要开源一款 AI 原生数据库 seekdb?
编者按:
11 月 18 日,2025 OceanBase 年度发布会在北京举行,现场发布并开源了 OceanBase 首款 AI 原生混合搜索数据库 seekdb(简称 seekdb)。
OceanBase 开源生态总经理封仲淹(花名:纪君祥,就是公众号 “老纪的技术唠嗑局” 里的话事人——老纪)会在这篇文章中,为大家介绍 OceanBase 开源 seekdb 的初衷。
如果你对文中提到的 seekdb(AI Native Database)感兴趣,欢迎大家到 https://github.com/oceanbase/seekdb 进行体验,相信会给你的 AI 应用开发带来新的启发!
在 2025 OceanBase 年度发布会上,我们正式发布并开源了 OceanBase 首款 AI 原生混合搜索数据库 OceanBase seekdb(简称 seekdb)。
发布之后,社区里很多朋友都在问三个问题:
1. seekdb 为什么要开源?
2. 它和 OceanBase 的定位有什么区别?
3. 这个开源是否具有长期性?
我想借这篇文章系统性地回答这三个问题。但在此之前,有必要先回顾一个更根本的问题:OceanBase 为什么要走开源这条路?

回望:OceanBase 的开源之旅
开源是战略选择,而非战术动作
2021 年 6 月 OceanBase 宣布开源时,外界最普遍的疑问是:一个商业上已经取得成功的数据库产品,为什么要选择开源?
我们当时的判断是:数据库是基础设施,基础设施的发展必须与用户和生态共同演进。这不是一句空话。基础设施软件的特殊性在于,它的价值不仅取决于技术本身的先进性,更取决于生态的完整性和用户的信任度。而开源,是构建这种信任最直接、最有效的方式。
所以从开源的第一天,就把 OceanBase 开源作为一个公司级战略。从资源投入来看,OceanBase 的开源项目投入是非常大的,从研发到运营,都是给到最好的资源配置。
从内核到完整解决方案
开源初期,我们只开放了内核和安装器。用户很快给出了反馈:他们需要的是完整的解决方案,而非单一的技术组件。
这个反馈促使我们在开源后的半年内,相继开放了 OMS、OCP、ODC 等核心工具。这些努力的目标只有一个:降低用户的使用门槛,让更多人能够真正用起来。
易用性的提升是一个持续性的工程。与数据库内核的优化一样,它没有终点,只有不断逼近用户期望的过程。
开源战略的关键演进:代码分支的统一
开源大约一年后,我们遇到了一个严峻的工程问题:社区版与企业版的代码同步。
在 OceanBase 3.X 时代,两个版本分属不同的代码分支,由不同的团队维护。这种架构导致了大量的同步成本和潜在的功能差异。用户时常会遇到社区版已修复的问题在企业版中依然存在的情况。
到了 4.X 时代,我们做出了一个重要的技术决策:将社区版与企业版合并到同一个代码分支,通过编译宏来区分不同的发行版本。为了达到这个目标,我们投入了大量的研发资源对代码进行模块化改造,虽然投入的资源比较大,但它向社区传递了一个明确的信号——我们对开源的承诺是真实的、长期的。
四年成绩:规模化验证
截至目前,OceanBase 开源已经四年,部署量突破 10 万套,企业用户超过 2000 家。从增长曲线来看,前年 6000 套,去年 3 万套,今年突破 10 万套——这是一个指数级的增长态势。
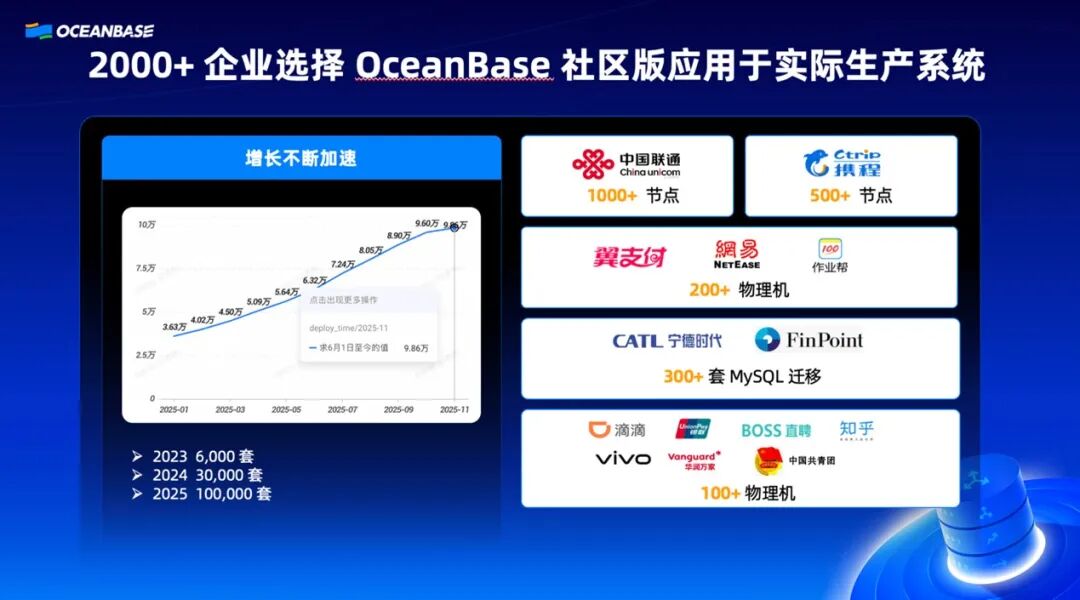
在国产数据库领域,除 PostgreSQL 和 MySQL 生态外,OceanBase 社区的规模是最大的。这组数据说明,开源策略得到了市场的验证。
但规模的增长并不意味着挑战的消失。恰恰相反,最大的挑战正在到来。

AI 重构基础设施的底层逻辑
GenAI:不是工具升级,而是基础设施的代际更替
观察一组数据:ChatGPT 发布 17 个月后,月活用户突破 8 亿,年搜索量达到谷歌的 5.5 倍。
这组数据的意义不在于某个产品的成功,而在于它揭示了一个趋势:GenAI 正在成为新一代基础设施的核心。这不是工具层面的迭代升级,而是整个技术栈的代际更替。
对于数据库而言,这意味着什么?意味着我们必须重新思考数据库的核心价值主张。
AI 应用:从概念验证到规模落地
AI 的大规模落地,最终要通过应用来实现。只有应用才能将 AI 的能力转化为端到端的生产力提升。
以 AI Coding 为例。使用过这类工具的开发者会有一个共同的感受:这是两个完全不同的世界。这种体验上的断层,正是 AI 应用价值的直观体现。
AI 时代对数据库的三重挑战
纵观全球 AI 数据库领域的技术领先者,会发现他们都在回应三个共同的挑战:数据的融合、模型的融合、对开发者的快速响应。
这三个方向,构成了 AI 时代数据库演进的核心命题。OceanBase 的回应,就是 seekdb。

OceanBase 应对 AI 时代数据挑战的解法:seekdb
seekdb 的定位是 AI 原生混合搜索数据库。理解这个定位,需要从三个维度展开。

数据融合:多模态存储与混合搜索
需求的真实来源
数据融合的需求,源于业务场景的真实演变,而非技术团队的自我想象。
我们与内部多个大规模业务团队进行过深入交流——钉钉、飞猪等日活过亿、数据量达 PB 级别的业务。这些业务处于技术应用的最前沿,他们遇到的问题往往预示着整个行业即将面临的挑战。
以飞猪为例,他们在向量搜索场景中遇到了一个典型问题:单纯的向量相似度检索无法满足业务需求。他们需要对标量数据的每一行设置权重,需要实现复杂的 Trigger 逻辑来动态调整搜索策略。换言之,向量检索必须与结构化数据的精确过滤深度结合,才能产出真正有业务价值的结果。
这不是个案。当 RAG 和搜索场景进入深水区,几乎所有团队都会遇到类似的问题。
从单一索引到混合检索
传统数据库的设计假设是:不同类型的数据使用不同的索引,彼此相对独立。全文索引处理文本,B+ 树索引处理结构化数据,它们各司其职。
但 AI 时代的数据使用方式打破了这个假设。一个典型的 AI 应用查询可能同时涉及:向量相似度匹配(语义理解)、全文检索(关键词匹配)、结构化过滤(时间、地点、类别等约束)、JSON 字段的嵌套查询、GIS 空间计算。这些不同类型的检索需要在一个查询中协同工作,并且需要统一的相关性排序。
这就是混合搜索的本质:不是简单地把多种索引堆叠在一起,而是让它们在查询层面实现真正的融合,产出统一的、业务可用的结果。
深水区的技术挑战
混合搜索带来的技术挑战是多维度的。
首先是数据理解的深度。当底层数据的使用方式发生变化,编程接口也必须随之演进。开发者需要新的表达方式来描述复杂的混合查询意图,这对 API 设计提出了很高的要求。
其次是性能优化的复杂度。不同类型的索引有不同的性能特征,如何在混合查询中找到最优的执行路径,是一个复杂的优化问题。
最后是一致性保障。多模态数据的事务一致性如何保证?当向量索引和结构化索引需要同时更新时,如何确保数据的完整性?
这只是起点
今天我们看到的全文索引、向量索引、JSON、GIS 的混合检索,只是这个演进过程的起点。
未来的数据融合会更深度、更灵活。我们可以预见的方向包括:更多模态数据的支持(音频、视频的原生理解)、更智能的查询理解(自然语言到混合查询的自动转换)、更动态的索引策略(根据查询模式自动优化)。
这是 AI 时代对数据库的内在要求,也是 seekdb 持续演进的方向。
模型融合:AI Inside 的技术路径
行业趋势的观察
观察 Oracle、Snowflake、Databricks 等企业的技术路线图,会发现 AI Inside 正在成为数据库基础设施的重要方向。
所谓 AI Inside,核心理念是将 AI 能力内置到数据库引擎中,而非作为外部服务调用。这意味着数据库不再仅仅是数据的存储和检索系统,而是具备了理解数据、生成数据、推理数据的能力。
坦率地说,这个领域目前还处于早期探索阶段。包括上述巨头在内,都还在寻找最优的技术路径。OceanBase 也是如此,seekdb 的 AI Inside 能力刚刚起步。
但方向的确定性是清晰的。这不是”要不要做”的问题,而是”如何做好”的问题。
用户视角的终极体验
理解 AI Inside 的价值,最好的方式是从用户视角出发。
用户真正需要的体验是什么?是 “Document in, Data out”——输入自然语言描述的需求,直接获得可用的数据结果。用户不应该需要理解底层的数据模型,不应该需要编写复杂的查询语句,不应该需要手动组合多个 API 调用。
举一个具体的例子。假设用户想要查询”过去一个月销售额增长最快的产品类别,排除季节性因素的影响”。在传统模式下,这个查询需要:编写 SQL 聚合查询、实现季节性调整的统计算法、可能还需要调用外部的时间序列分析服务。
在 AI Inside 的理想状态下,用户只需要用自然语言描述这个需求,数据库内置的 AI 能力会自动完成:理解查询意图、生成执行计划、调用内置的统计分析能力、返回最终结果。
这是三句话完成数据查询的愿景背后的技术含义。
AI Inside 的技术内涵
实现 AI Inside 需要在多个技术层面进行深度整合。
第一是自然语言理解与查询生成。数据库需要理解用户的自然语言输入,并将其转换为可执行的查询计划。这不是简单的 Text-to-SQL,而是需要理解业务语境、处理模糊表达、支持多轮交互。
第二是内置的向量计算能力。向量是 AI 时代数据的核心表示形式。数据库需要原生支持向量的存储、索引、计算,而非依赖外部的向量数据库。
第三是模型推理的本地化。将模型推理能力集成到数据库引擎中,可以避免数据在数据库和 AI 服务之间的频繁传输,大幅降低延迟并提高安全性。
第四是智能化的查询优化。利用 AI 能力来优化查询执行计划,根据数据分布和查询模式动态调整策略。
第五是数据增强与生成。数据库具备对数据进行自动标注、增强、甚至生成的能力,为下游 AI 应用提供更高质量的数据。
seekdb 的技术布局
与模型的深度融合,是我们做 seekdb 的核心技术方向之一。
在当前版本中,seekdb 已经具备了基础的 AI Inside 能力:原生的向量数据类型和索引、内置的 Embedding 生成、简化的自然语言查询接口。
在未来的路线图中,我们会持续强化这个方向:更强大的自然语言理解、更多预置的 AI 函数、更深度的模型集成、更智能的自动优化。
这是一个需要长期投入的方向,但也是数据库在 AI 时代必须具备的核心能力。竞争的焦点在于谁能更早、更好地实现它。
轻量化:重新定义开发者体验
应用开发者决定数据库的未来
回顾历史,20 年前 LAMP 架构的出现,让 MySQL 占据了中国互联网几乎全部的数据库市场份额。这个现象的本质是:应用开发者决定了数据库的选型走向。
传统场景下,DBA 选择数据库的核心标准是成熟稳定。但在 AI 时代,如果要赢得开发者,就必须满足他们的核心诉求:更快的迭代速度、更低的使用门槛、更轻的资源占用。
架构层面的彻底重构
OceanBase 长期以来的一个目标是实现 1C 几 G 资源下的运行。过去 2 年,我们投入了大量努力,不断给 OceanBase 瘦身,但这个目标始终没有彻底实现。
seekdb 选择了一条更彻底的路径:完全抛开历史包袱,大刀阔斧进行设计,我们裁掉了分布式架构、多租户、RS 部分模块(集群管理)、分布式事务等复杂组件,大幅精简了代码量。
最终的结果是:OceanBase 最小需要 2C6G 资源,seekdb 最小只需要 1C2G(实际可以把资源占用配置成更小,大家不妨一试),支持秒级启动和嵌入式部署。嵌入式能力将打开端云一体的场景空间,这在 IoT 等领域有广阔的应用前景。
开发体验的重新设计
我们为 seekdb 设计了全新的 SDK,相比原有的 Python SDK 更加简洁——三行代码即可完成一个基础应用。安装流程也进行了全面简化。
迭代速度的根本性提升
上述所有改进,最终指向一个核心目标:更快地响应开发者需求。
OceanBase 的分布式版本承载了金融级的高可用、强一致性等要求。这些要求决定了它的架构复杂度。数据库中最复杂的模块是事务管理,分布式事务更是复杂性的顶峰——它涉及 RPC、大事务恢复等一系列技术难题。
seekdb 裁掉这些模块后,可以实现真正的轻装迭代,快速响应开发者的反馈和需求。
开放协议与生态战略
seekdb 采用 Apache 2.0 协议。相比其他开源协议,Apache 2.0 对所有用户更加友好,尤其有利于海外市场的拓展。生态建设是 seekdb 的核心战略方向。
seekdb 与 OceanBase 的定位区分
seekdb 的定位可以用两个关键词概括:更 AI Native、更轻量。
具体的选型建议是:数据量大、需要分布式能力的场景,推荐 OceanBase;数据量轻量或者更偏 AI 类需求的场景,推荐 seekdb。seekdb 会在 AI 方向上保持更快的迭代节奏,更快地满足这一领域的用户需求。

seekdb 之外:构建完整的 AI 开发者支持体系
AI 应用的三大热点方向
当前 AI 领域最活跃的三个方向是 Agent、RAG 和 Memory。几乎所有主要厂商都在这三个方向上进行布局。对于 OceanBase 而言,除了 seekdb 本身,我们也在这些领域进行了系统性的投入。
PowerRAG:站在巨人肩膀上的创新
PowerRAG 是基于 RAGFlow 的二次开发项目。PowerRAG 的价值在于在此基础上进行企业级的增强。
主要的增强方向包括:更好的企业级适配(高可用、权限管理等特性)、丰富的组件和插件支持(如 DeepSeek OCR、MinerU),这些能力在企业级 RAG 场景中非常关键。
PowerMem:让 AI 应用更省 Token
PowerMem 是我们同期开源的 Memory 项目。它的核心价值是显著降低 AI 应用的 Token 消耗——相比 OpenAI 的 Memory 方案,可以节省 96% 的 Token。
这个效果是如何实现的?主要有以下几个技术手段:智能记忆管理、分层记忆架构、基于 seekdb 内核的混合检索、Prompt 层面的深度优化、多模态支持。此外,我们也在探索 Graph 能力,以支持 AI Inside、千人千面等新型业务场景。
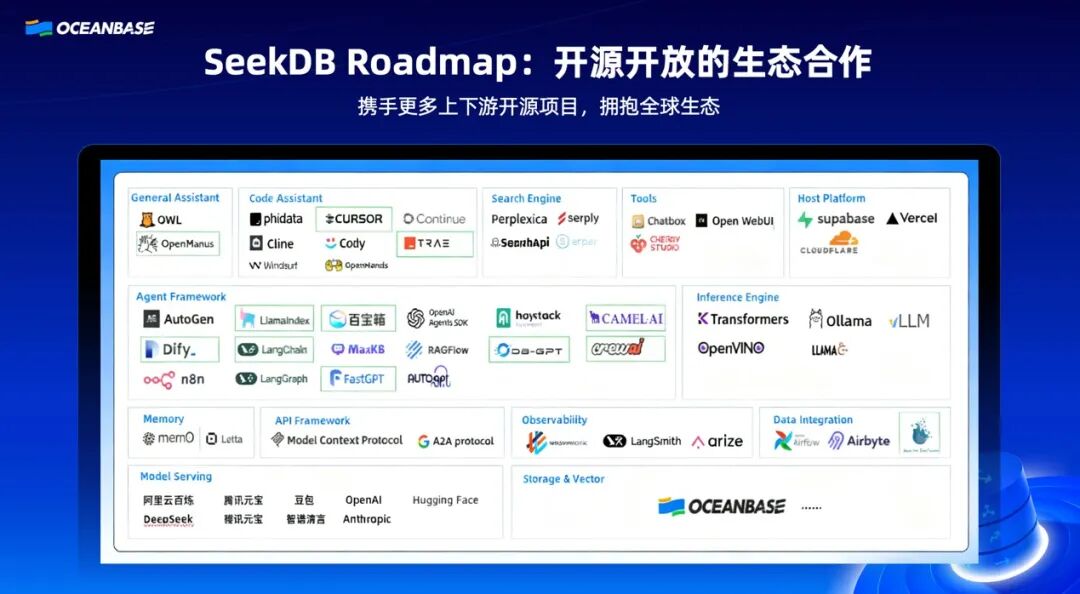
seekdb Roadmap:开发者与生态为核心
相比 OceanBase,seekdb 会更聚焦于开发者和生态。我们将积极与上下游生态伙伴合作,尤其期望能与 AI 开源项目、国内头部开源项目和全球顶级开源项目建立深度合作。
社区很多朋友已经了解,今年我已经在海外工作过一段时间,明年预计会有更多时间在全球化上。这不意味着国内支持的减少——社区团队会一如既往地服务好大家。同时,我们会投入更多资源去拓展和打通全球化开发者生态,让 OceanBase 更开发者友好。
我一直有一个判断:能够走出国门的中国数据库,必然是经过严苛市场考验的优秀产品。在中国这样竞争激烈的市场环境中存活并发展起来的数据库,到全球市场往往更具有显著的竞争优势。

未来:seekdb 的成长空间
今天的 seekdb,可以理解为 OceanBase 生态中的一个新生成员。OceanBase 积累了 15 年,已经具备了相当的规模和影响力。seekdb 则刚刚起步。

但我们对未来的判断是:seekdb 的成长空间将充满想象。
这个判断基于两个基本事实。第一,在数据库市场中,集中数据库市场还是很大的,这将帮助我们拓展一个更大的市场空间的可能性。第二,AI 是下一个时代的分水岭,而 seekdb 继承了 OceanBase 的可靠性、稳定性和强一致的 15 年的基础能力,在 AI 这个方向上具有先天优势。
未来,seekdb 将在 AI 的赛道上不断快速迭代,然后不断把沉淀的 AI 能力反哺给 OceanBase,更好地满足更多企业级客户在关键业务负载、实时分析和 AI 搜索上的多元需求。

结语
回到开篇的三个问题。
seekdb 为什么开源? 因为开源是 OceanBase 的核心战略,数据库作为基础设施必须与用户和生态共同成长。
seekdb 与 OceanBase 的定位有何区别? seekdb 更 AI Native、更轻量,更面向 AI 时代的开发者;OceanBase 则主要通过一体化的能力,全方位满足企业级客户在关键业务负载、数据实时分析和 AI 搜索上的多元需求。
seekdb 的开源是否具有长期性? 是的,它是战略级的投入。正如 OceanBase 开源四年后依然在持续成长,seekdb 也将获得长期、持续的投入。
开源不是终点,而是起点。seekdb 的开源,是 OceanBase 面向 AI 时代的战略选择。我们期待与社区一起,见证 seekdb 从起步走向成熟。