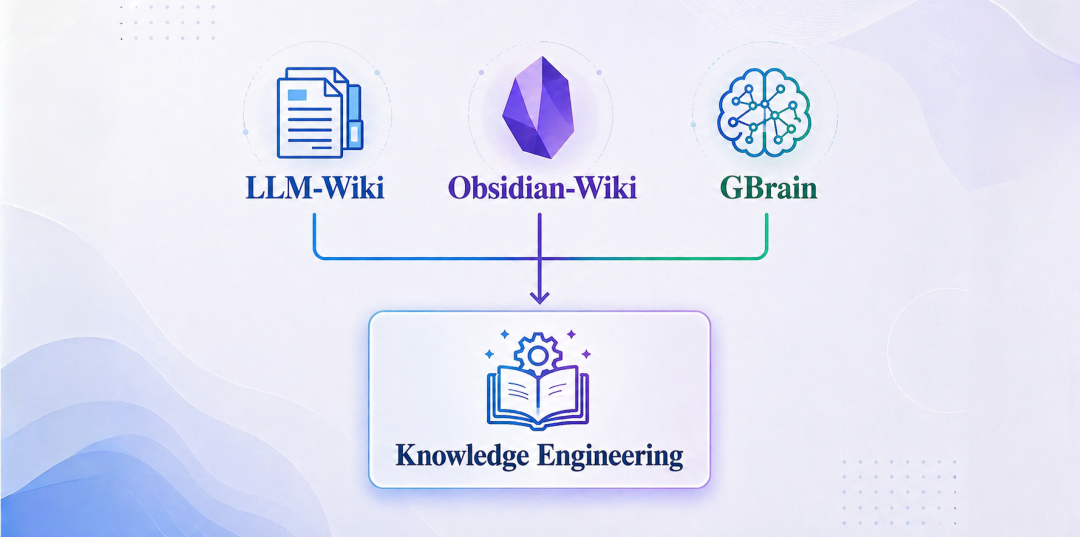
深度解析 LLM Wiki / Obsidian-Wiki / GBrain:Agent 时代知识的“自组织”与“自进化”
今天这篇文章,会从 Knowledge Engineering(知识工程)的角度,由 LLM Wiki、Obsidian-Wiki 和 GBrain 的设计切入,为大家拆解在 Agent 时代,知识工程为何比单纯优化 RAG 更关键。以及“Skillify”是如何把零散资料,沉淀为可持续进化的结构化记忆的。
背景
近期大家对 AI 关注的焦点非常集中,主要围绕在“自进化”这个概念,包括“Skill 的自动沉淀”以及“RL(强化学习)训练”这两个核心维度上。对于大多数工程落地场景而言,通过 Skill 机制来实现 Agent 的自进化是更轻量、更具普适性的方式。
仅通过 Skill 自动更新还不足够——通过人给予 Agent 更多的“知识”,甚至存放知识的这个“知识库”如果能“自动梳理”、“自动组织”、“自动更新”甚至“自动进化”,就能推动 Agent 的不断“自进化”。

从“知识堆积”到“结构化记忆”
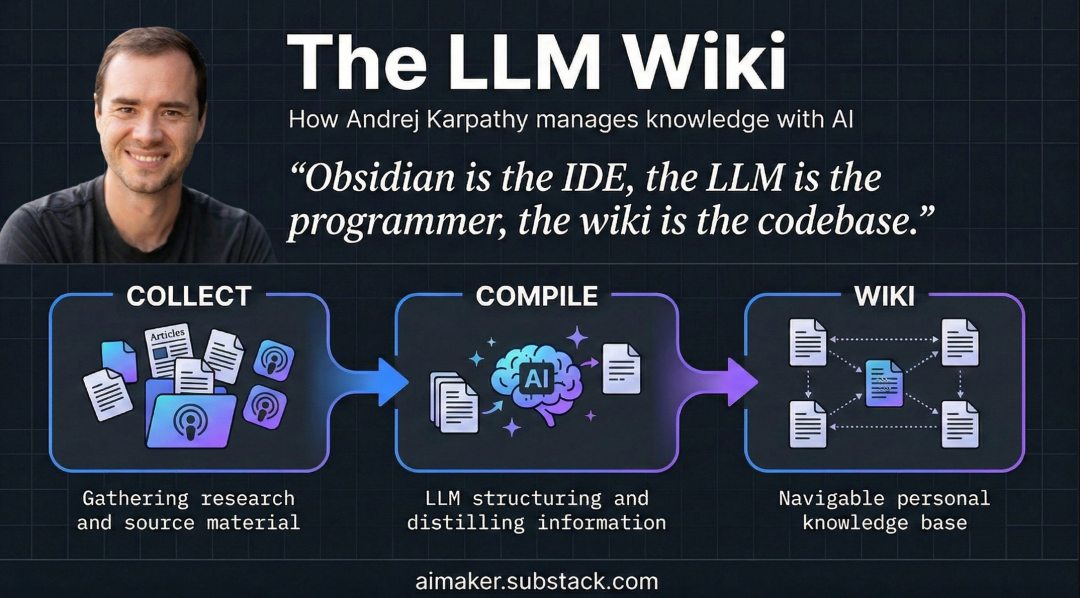
Andrej Karpathy 开源了“LLM-Wiki”项目,核心是一个 Markdown 文件,目标是指导大模型 Agent 进行知识的更新与结构化。GBrain 由 Y Combinator 总裁兼 CEO Garry Tan 构建,思想和 LLM-Wiki 类似但更工程化。
人类非常擅长“无脑堆积”知识,但很不擅长“组织”知识。知识管理的难点体现在时效性与动态维护、组织结构的复杂性两个维度。在 AI 时代,知识的质量直接决定了效果的上限。
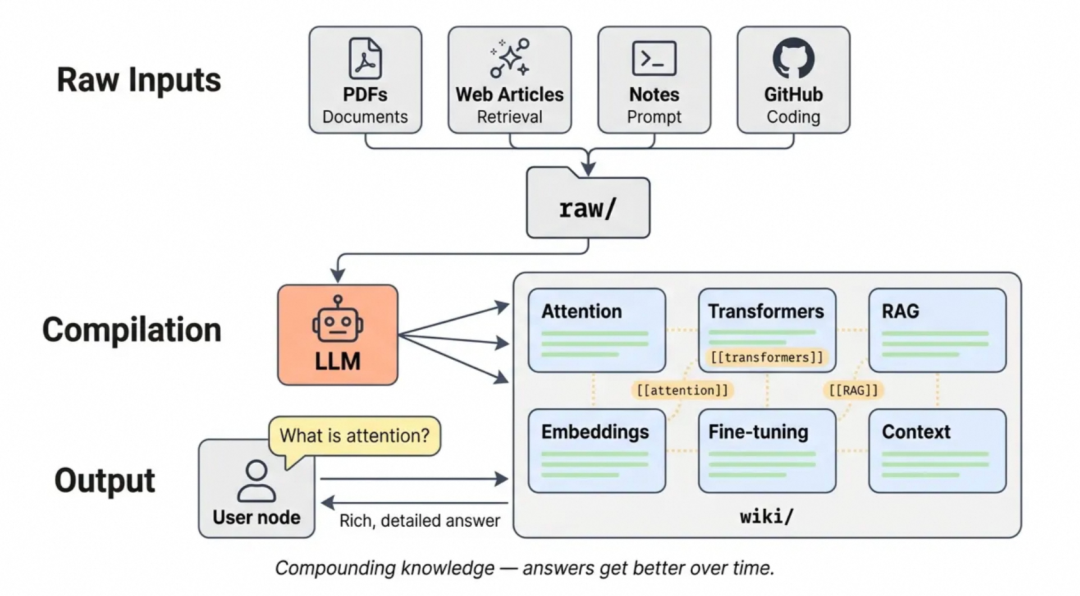
如果说 Prompt Engineering 是在教模型“完成什么样的任务”,那么 Knowledge Engineering 就是在教模型“应该知道什么”以及“如何运用已知信息”。Karpathy 的 LLM-Wiki 突破了传统 RAG“每次查询从头检索”的局限,通过 Schema 文件指导 LLM 主动维护结构化的 Markdown Wiki,将原始资料“编译”为带有交叉引用、矛盾标注的持久化知识体。
Skillify:渐进式披露式的“知识形态”
LLM Wiki 和 GBrain 的核心创新在于:将 Skill 泛化为一种知识组织形态。GBrain 创始人使用了一个词叫“Skillify”——去写 Skill 或者像 Skill 一样去组织和加载知识。这种机制允许各类 Agent 接收各类文件、文本、链接,然后自动将其“编译”并归档到一个统一的个人知识库中。
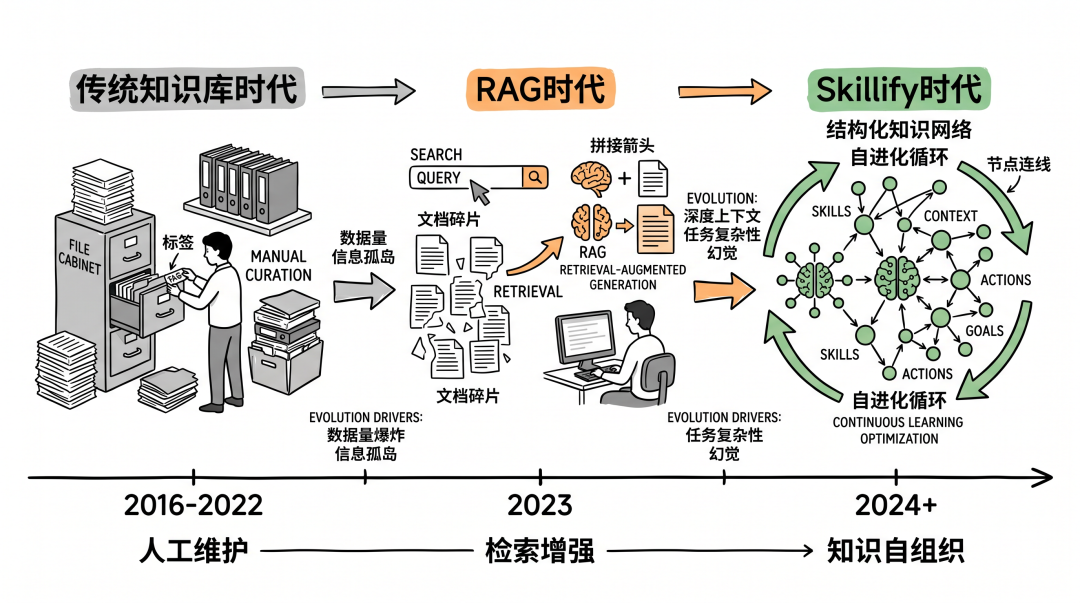
回顾阿里云智能客服发展三阶段:传统智能知识库时代(2016~2022)→ RAG 时代(2023起,存在模型能力断层和知识未沉淀问题)→ Agent 时代(大模型主导的持久化知识库,“一次学习,永久可用”)。
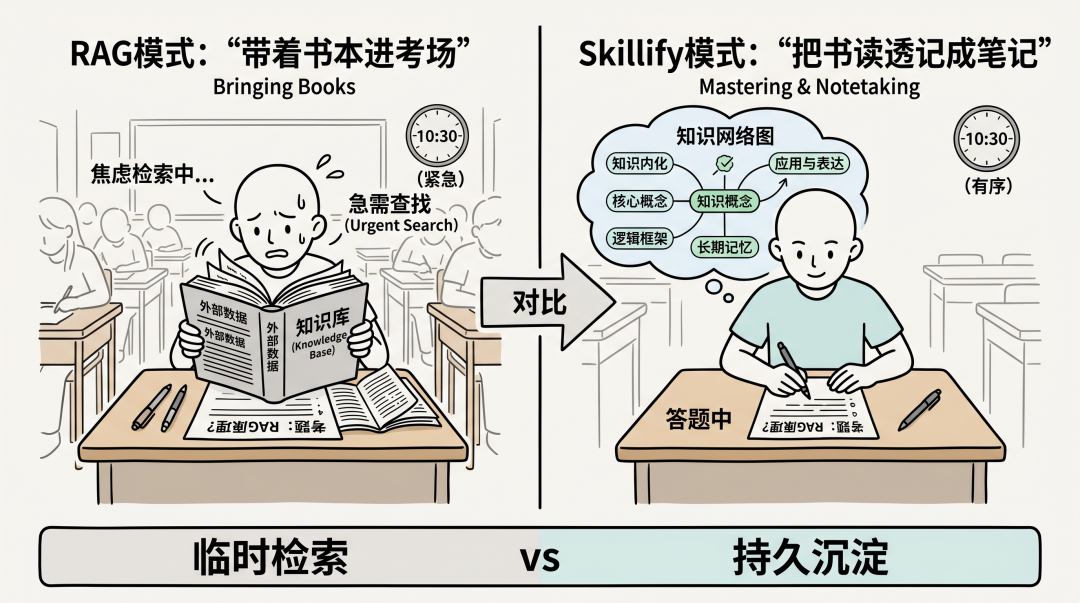
如果说 RAG 是让大模型“带着书本进考场”,那么 Skillify 则是让大模型“把书读透并记成整理后的笔记”。
LLM Wiki:三层架构的知识闭环
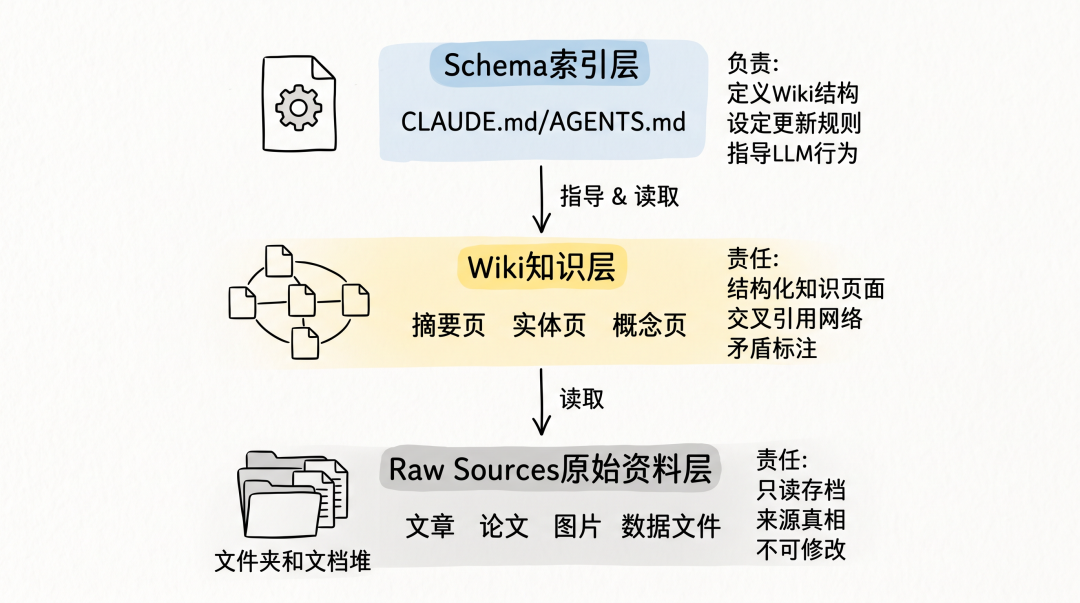
LLM Wiki 核心理念:不是在查询时从原始文档中检索,而是让 LLM 渐进式地构建和维护一个持久的 Wiki。三层架构:Raw Sources(只读存档区)→ The Wiki(结构化知识页面)→ The Schema(元指令)。
三种核心操作:
- 摄入(Ingest):LLM 阅读原始资料,提取关键要点,自动更新全局索引,一个来源能联动更新 10-15 个相关 Wiki 页面
- 查询(Query):LLM 先定位相关 Wiki 页面,综合出带引用的答案。高质量答案可归档为新页面
- 维护(Lint):类似代码静态检查,识别事实矛盾、清理过时声明、发现孤立页面
Obsidian-Wiki:从想法到系统的工程化实现

Obsidian-Wiki 是一个基于 Skill 的多 Agent 框架,核心增强包括:
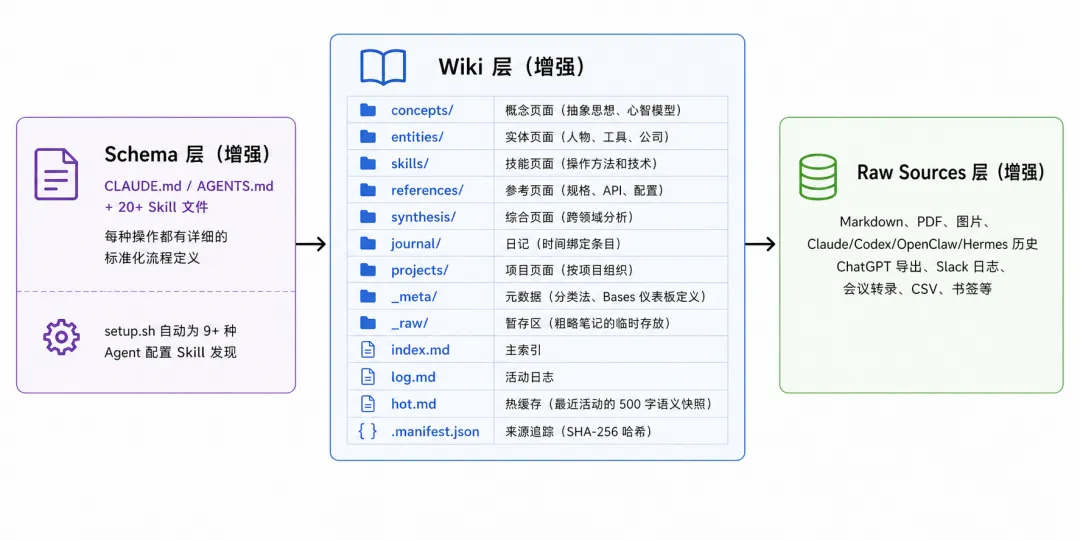
- Delta 追踪:用 SHA-256 哈希追踪所有来源,知道哪些需要重新处理
- 来源可信度边界:来源文档视为不可信,防止 prompt injection
- 溯源标记系统:extracted / inferred / ambiguous 三种置信度
- Agent 历史摄入 Skills:自动扫描 Claude、Codex、OpenClaw、Hermes Agent 的历史记录
- 知识图谱 Skills:cross-linker 技能自动发现页面间联系,引入置信度评分系统
LLM Wiki 能力边界:无数据库依赖(适合数百到低千页面)、规模天花板明显、无自动化调度、弱结构化图谱。随着页面膨胀需要引入向量搜索或图数据库基础设施。
GBrain:混合检索架构与图谱关系演进
GBrain 架构哲学:Thin Harness, Fat Skills。建议把 Harness 做得薄,主要精力放在丰富 Skills 上。
潜在空间 vs 确定性
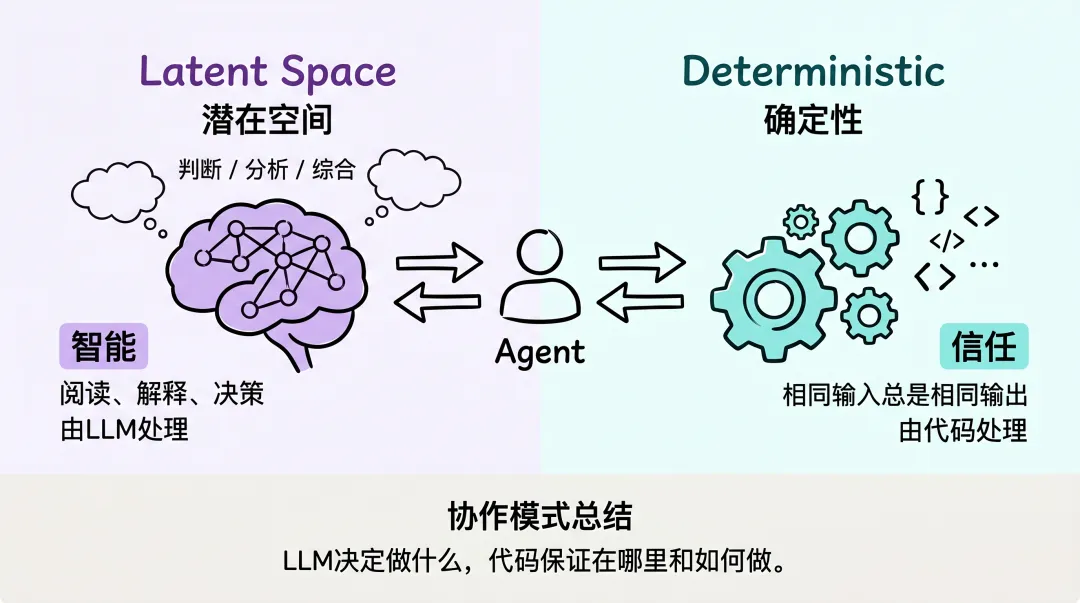
让 LLM 决定“做什么”(潜在空间),让代码保证“在哪里”和“如何做”(确定性)。
混合检索架构:向量过滤 + 文件披露
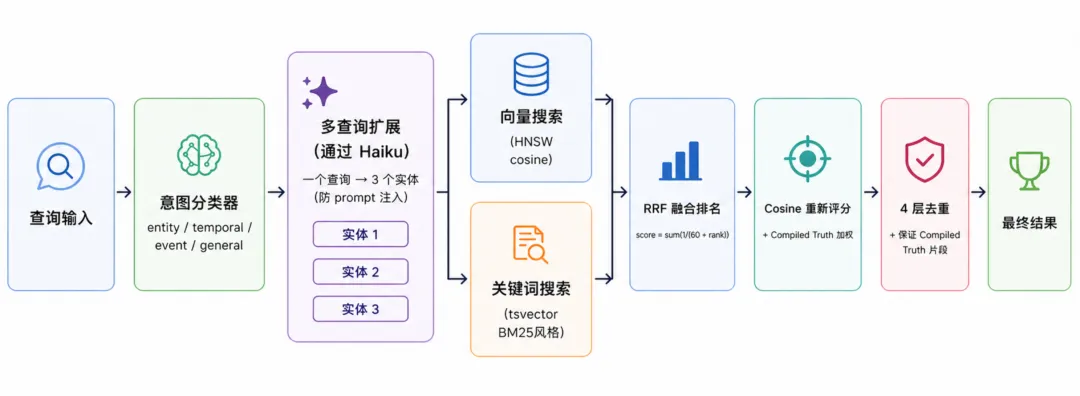
GBrain 的检索过程是“Chunk 确认 → 整页加载 → 分层呈现”。向量检索快速从海量文件中筛选候选集,然后整页加载走渐进式披露。“向量粗筛 + 文件精读”既避免了纯 RAG 的语义丢失,也克服了纯文件遍历的效率低下。
seekdb 将这种模式工程化:一条查询里既可以做全文匹配,也可以做向量近邻检索,还可以叠加标量过滤、权重融合、RRF 或重排序模型。
GBrain 在 240 页 Benchmark 上的实测结果:
| 指标 | GBrain(带图谱) | 仅混合搜索(无图谱) | 差距 |
|---|---|---|---|
| P@5 | 49.1% | 17.7% | +31.4 pp |
| R@5 | 97.9% | — | — |
图谱构建与实体关系抽取
GBrain 图谱构建四步 Pipeline:实体抽取(正则+关键词模式匹配)→ 页面生成 → 关系分类(关键词匹配判断关系类型)→ 反向链接强制化。GBrain 拥有完整的图数据结构:节点、有类型的边、可遍历性。能让 Agent 执行“查找所有由张三投资且李四任职的公司”这样的复杂推理任务。
seekdb:混合搜索能力如何落到真实工程里
当知识规模继续增长,seekdb 这类 AI 原生混合搜索数据库回答的是:底层检索基础设施该怎么接住这些需求。它把向量搜索、全文搜索、标量过滤、重排揉进了同一个引擎里,减少了多套检索组件拼接带来的复杂度和一致性问题。
英伟达工程师已发布基于 seekdb + PowerMem 的多模态智能记忆系统 MemBox,前端接收用户消息与图片,后端向量化后在 seekdb 中检索相关记忆,再把召回的用户画像注入大模型上下文。
LLM Wiki 和 Obsidian-Wiki 探索知识组织范式,GBrain 探索工程化知识系统,seekdb 补上“大规模、可过滤、可混合、可重排”的检索基础设施。未来 Agent 系统必然把“上层的知识组织”和“下层的混合搜索底座”结合起来。
总结
Skill 与知识的动态维护体系,正是决定 Agent 能否从“一次次试错探索”进化为“持久化学习更新”的分水岭。
技术选型并非非此即彼。通常的最佳实践是混合架构:利用 OceanBase seekdb 这类混合搜索能力进行快速初筛,解决“找得快”的问题;同时保留大模型对高价值知识的深度阅读、渐进式披露以及离线自我迭代能力,解决“答得准”和“记得牢”的问题。
参考链接:
- [1] LLM-Wiki: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
- [2] AI Maker 解读: https://aimaker.substack.com/p/llm-wiki-obsidian-knowledge-base-andrej-karphaty
- [3] GBrain: https://github.com/garrytan/gbrain
- [4] Obsidian-Wiki: https://github.com/ar9av/obsidian-wiki
- [5] seekdb: https://www.seekdb.ai/zh-CN
- [6] seekdb SDK/SQL: https://docs.seekdb.ai/seekdb/zh-CN/experince-hybrid-search-with-sdk
- [7] Build RAG with seekdb: https://docs.seekdb.ai/seekdb/zh-CN/build-a-rag-system-with-seekdb