工作流 Skill 怎么写?从 7 个顶级项目中提炼的模式与最佳实践
楔子
今天分享的这篇文章,在阿里巴巴和蚂蚁集团内部的技术分享平台 ATA 上,热度远超想象。可见大家在工作中,想把自己的复杂工作流/SOP写成 Skill 时,总会遇到不知道怎么写,以及写完之后 Skill 运行不符合预期的情况。

在这篇文章中,青斧大佬分析了 7 个最顶尖的 Skill 案例,并根据分析结果总结了 5 种工作流 Skill 的设计模式。经过了作者青斧的授权,在这里把文章分享给大家。
本文基于对 7 个来自 OpenAI、Google Labs、obra、Trail of Bits、Dean Peters 等团队的生产级 Skill 的逐行分析,提炼出的可复用的五种 Skill 设计模式、写作技巧和反面教训。
一、Skill 是什么
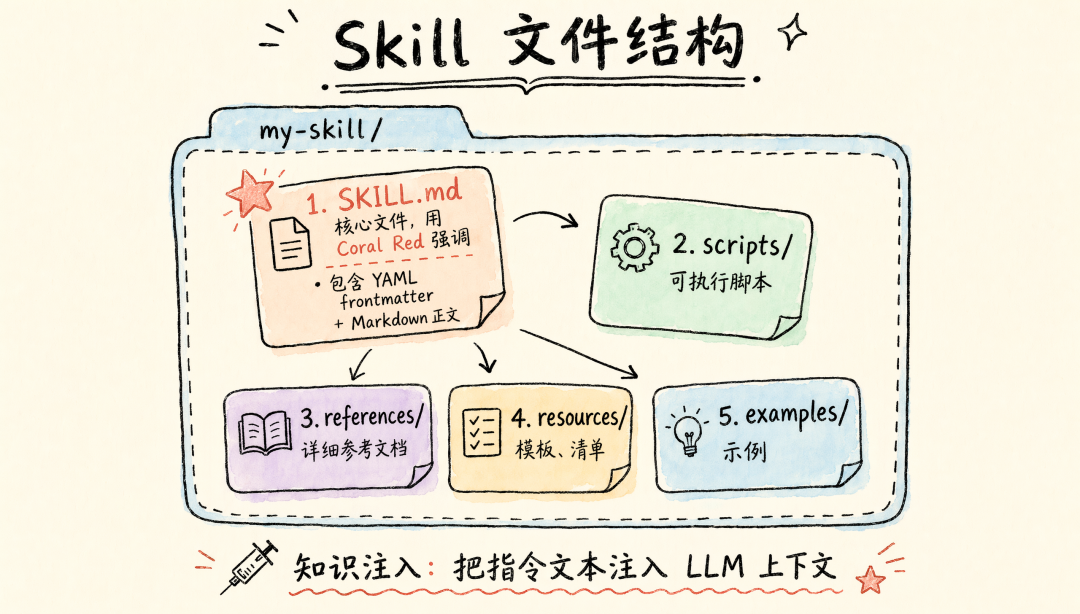
Skill 是一个文件夹,核心是 SKILL.md 文件,使用 YAML frontmatter + Markdown 正文 的格式。当 LLM 判断需要某个 Skill 时,会调用 skill 工具加载它。
关键机制:Skill 本质是”知识注入”——它不会动态生成新工具,而是把指令文本注入到 LLM 的上下文中,LLM 用已有的工具(bash、read、edit 等)来执行这些指令。
二、Frontmatter:决定 Skill 是否被加载的”门面”
| 字段 | 作用 | 示例 |
|---|---|---|
name |
唯一标识符,小写连字符 | test-driven-development |
description |
最关键——LLM 通过它决定是否加载 | 见下方对比 |
核心原则:列举触发短语、定义时序位置、包含产品关键词。
三、5 种核心设计模式
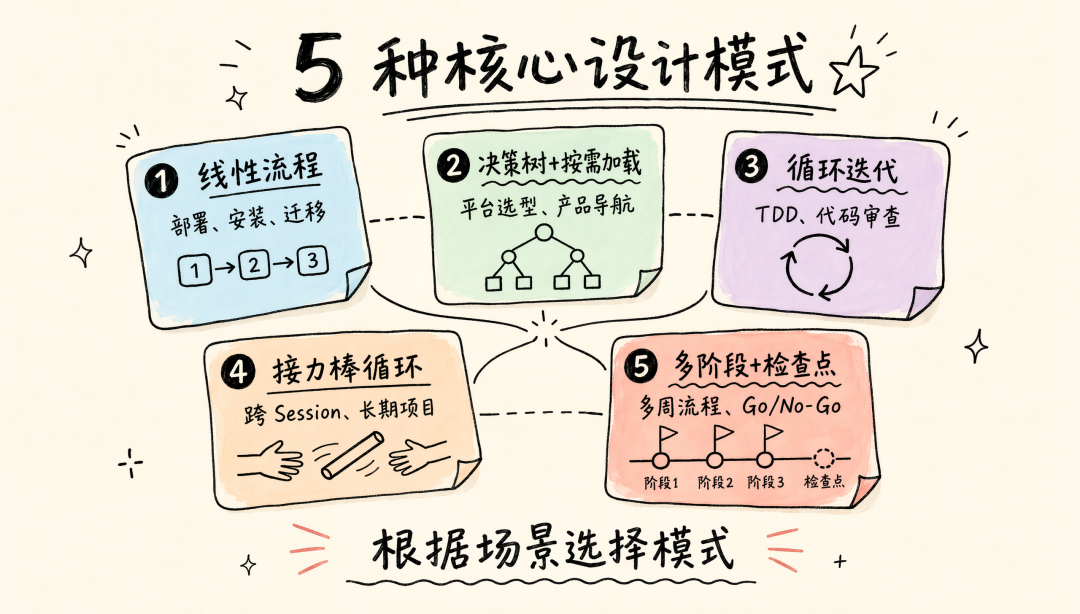
模式 1:线性流程
适用场景:部署、安装、迁移等有明确步骤的操作。代表:openai/skills — vercel-deploy(77 行)。
结构:Prerequisites → Quick Start → Fallback → Troubleshooting。
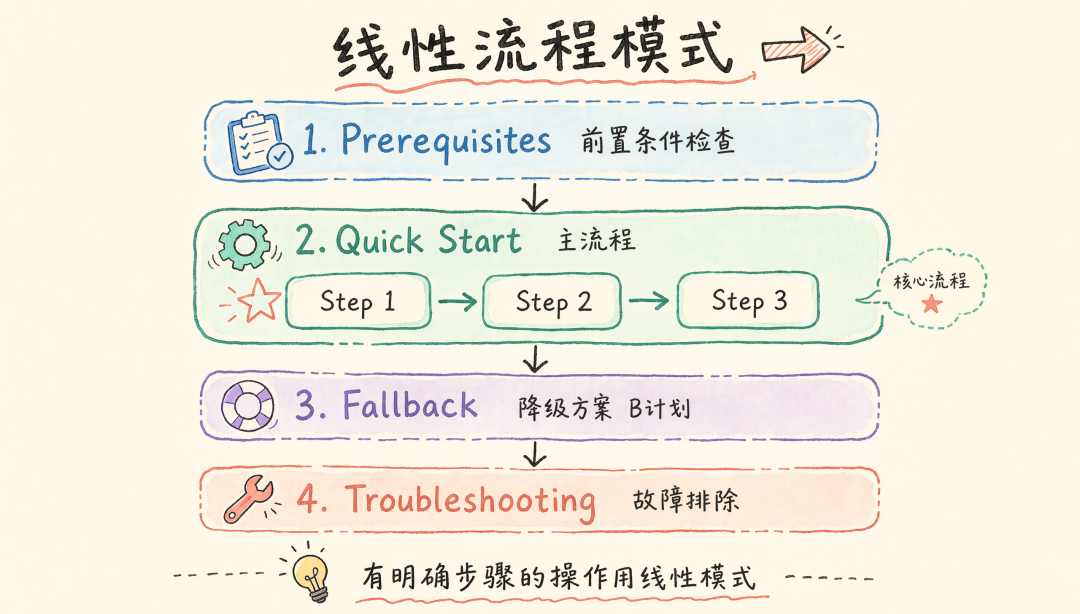
关键技巧:安全默认值、具体命令、超时提示、降级方案、负面指令。
模式 2:决策树 + 按需加载
适用场景:大型平台选型、产品导航、问题诊断。代表:openai/skills — cloudflare-deploy(224 行)。
结构:Authentication → Quick Decision Trees(按用户意图分类)→ Product Index。
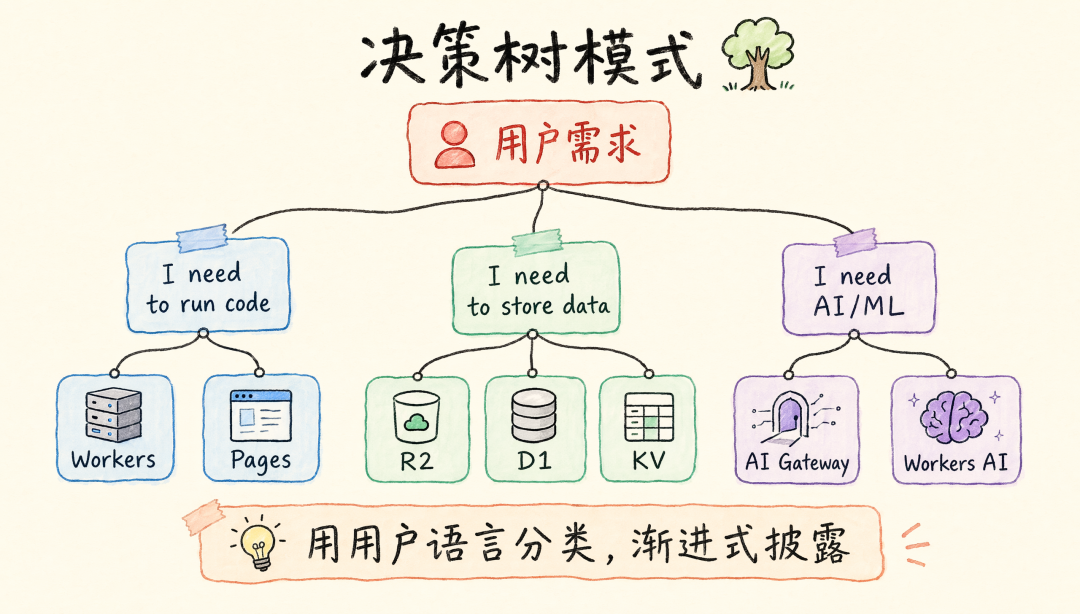
关键技巧:用户意图分类(用用户语言而非技术术语)、树形导航、渐进式披露(主文件 7KB,references/ 按需展开)。
模式 3:循环迭代
适用场景:TDD、代码审查、设计评审等需要反复执行的流程。代表:obra/superpowers — test-driven-development(371 行)。
结构:Iron Law(铁律)→ Red-Green-Refactor(循环体)→ Common Rationalizations(借口反驳表)→ Verification Checklist。
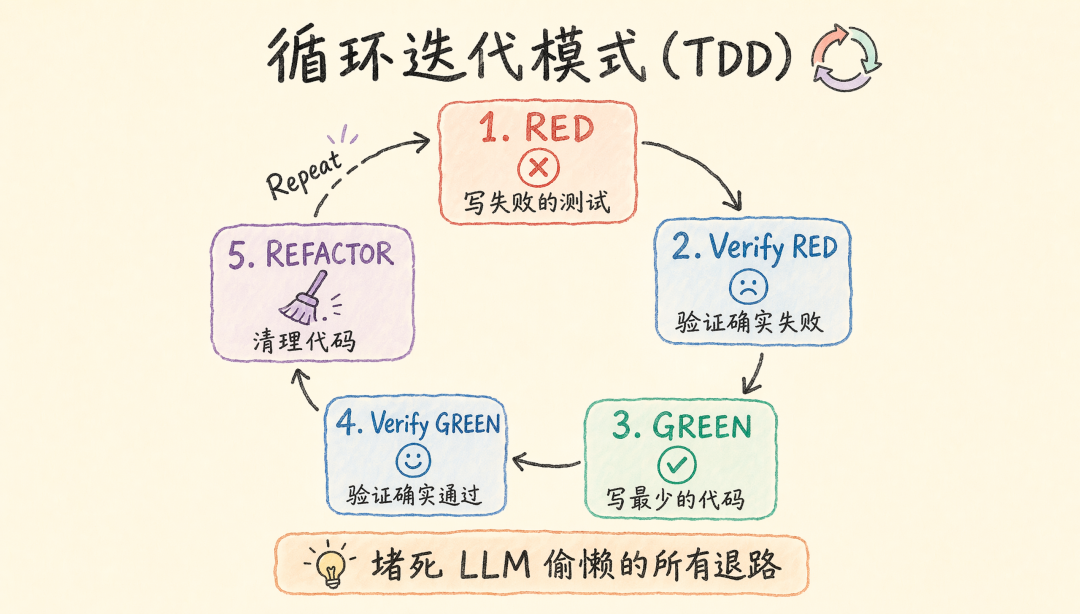
关键技巧:强硬语气、Good/Bad 对比、借口反驳表(预判 LLM 可能的 12 种偷懒借口)、验证清单、人类兜底。
模式 4:接力棒循环(跨 Session 持久化)
适用场景:多次迭代的长期项目。代表:google-labs-code/stitch-skills — stitch-loop(203 行)。
六步执行协议:Read the Baton → Consult Context → Generate → Integrate → Update Documentation → Prepare the Next Baton(关键!)。
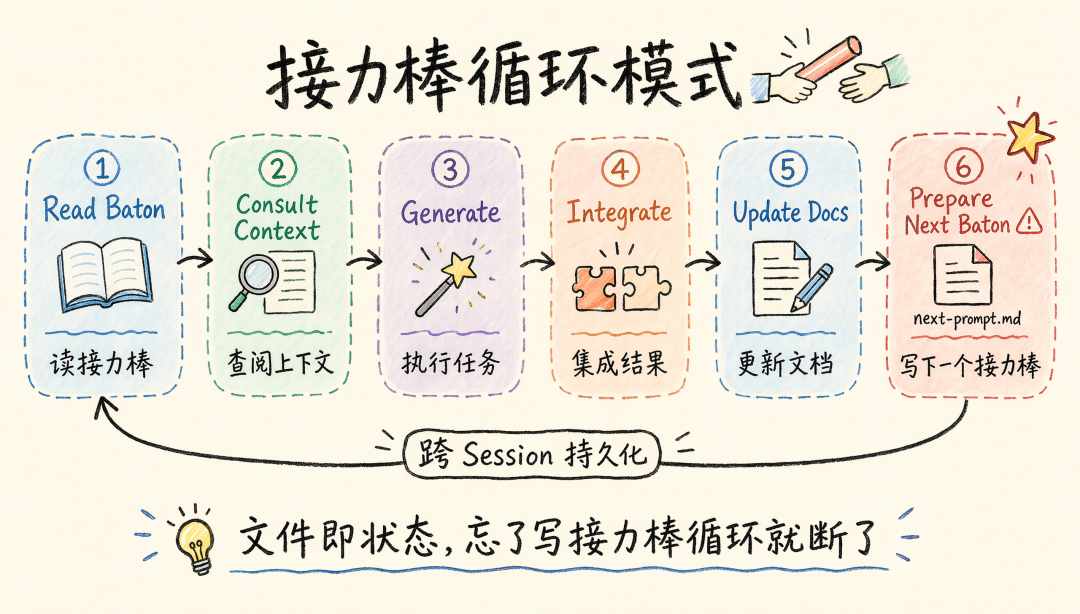
关键:文件即状态(next-prompt.md 作为接力棒),LLM 不需要记住”上次做到哪了”。
模式 5:多阶段 + 检查点 + Skill 编排
适用场景:复杂多周流程,需要在关键节点做 Go/No-Go 决策。代表:deanpeters/discovery-process(502 行)。
结构:Phase Activities → Outputs → Decision Point(YES/NO + 时间影响)。
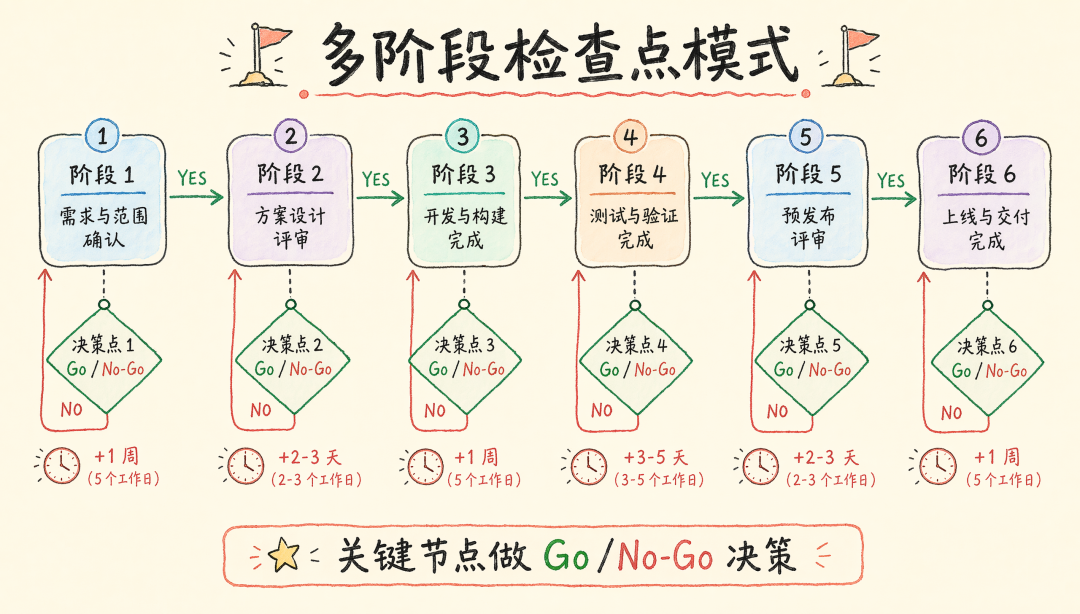
特殊模式:思维框架(控制 LLM “怎么想”)
适用场景:安全审计、代码审查等需要深度思考的场景。代表:trailofbits/skills — audit-context-building(302 行)。
关键技巧:思维工具(第一性原理、5 Why、5 How)、量化阈值(”每个函数最少 3 个不变量”)、反幻觉规则。
四、通用写作技巧
防止 LLM 偷懒的 4 种武器

| 武器 | 原理 |
|---|---|
| 强硬语气 | LLM 对命令式语气的遵从率更高 |
| 借口反驳表 | 预判 LLM 的自我合理化路径并堵死 |
| 量化阈值 | 给出硬性的最低标准 |
| 负面指令 | 明确说”不要做 X” |
知识组织的 3 层架构
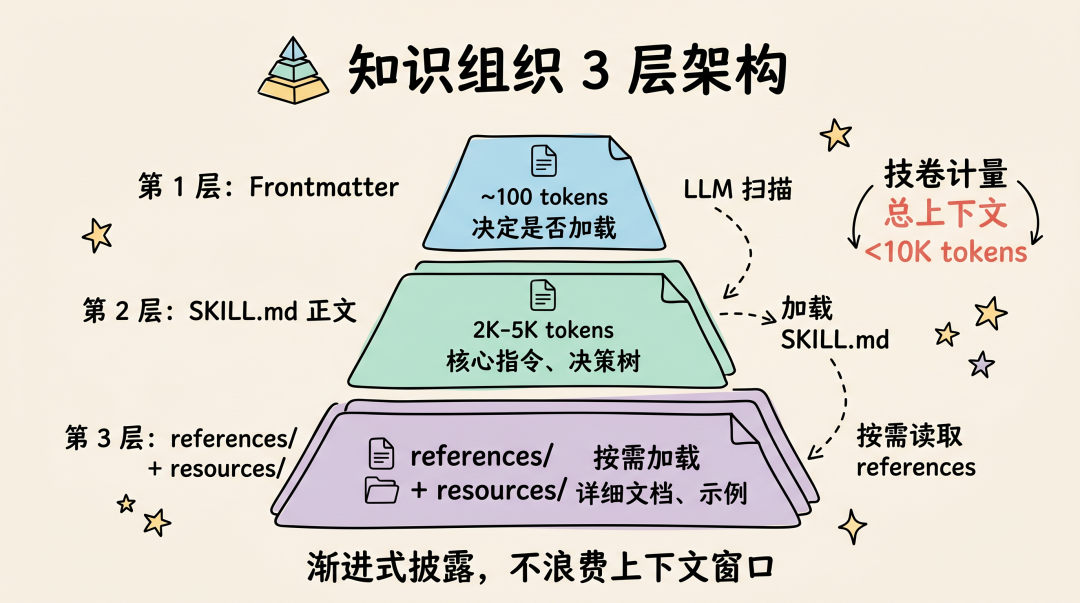
- 第 1 层:Frontmatter(~100 tokens)→ LLM 扫描所有 Skill 的 description
- 第 2 层:SKILL.md 正文(<5K tokens)→ 核心指令
- 第 3 层:references/ 和 resources/(按需加载)→ 详细文档
五、模式选择决策树
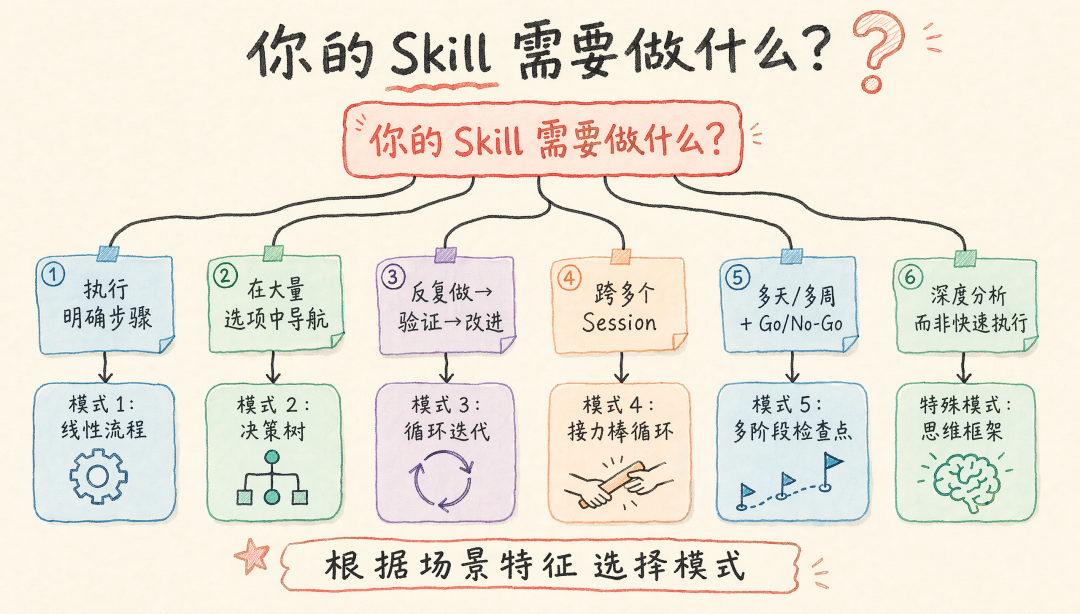
1 | 你的 Skill 需要做什么? |
六、本文分析的 7 个 Skill 速查表
| # | Skill | 来源 | 模式 | 行数 | 一句话精髓 |
|---|---|---|---|---|---|
| 1 | vercel-deploy | OpenAI | 线性 | 77 | 最小但完整的 Skill 模板 |
| 2 | cloudflare-deploy | OpenAI | 线性+决策树 | 224 | 大平台的渐进式披露 |
| 3 | cloudflare | OpenCode | 纯决策树 | 211 | 导航型 vs 操作型 |
| 4 | test-driven-development | obra | 循环迭代 | 371 | 堵死 LLM 偷懒的所有退路 |
| 5 | stitch-loop | Google Labs | 接力棒循环 | 203 | 文件即状态,跨 session |
| 6 | discovery-process | Dean Peters | 多阶段+检查点 | 502 | 编排器模式 |
| 7 | audit-context-building | Trail of Bits | 思维框架 | 302 | 控制 LLM “怎么想” |
参考链接:
[1] openai/skills vercel-deploy: https://github.com/openai/skills/tree/main/skills/.curated/vercel-deploy
[2] openai/skills cloudflare-deploy: https://github.com/openai/skills/tree/main/skills/.curated/cloudflare-deploy
[3] obra/superpowers TDD: https://github.com/obra/superpowers/tree/main/skills/test-driven-development
[4] google-labs stitch-loop: https://github.com/google-labs-code/stitch-skills/tree/main/skills/stitch-loop
[5] deanpeters discovery-process: https://github.com/deanpeters/Product-Manager-Skills
[6] trailofbits audit: https://github.com/trailofbits/skills
[7] Agent Skills 开放标准: https://agentskills.io/
[8] anthropics/skills: https://github.com/anthropics/skills