Abstract
Microsoft SQL Server PDW, 是一个基于SQL-Server基础上构建的MPP 分布式数据库, 旨在提供数据仓库解决方案。 复用了很多SQL-Server的技术, 如query 简化, 空间探索, cardinality 评估。
整个架构share nothing,有一点类似DRDS 的架构,优化器叫PDW QO
架构

pwd 是一套软硬一体的硬件, 可以进行水平扩张(增加节点),或垂直扩展(升级cpu/memory/存储)
控制节点和计算节点都包含一个sql-server 节点, DMS – data movement service。
优化搜索空间(optimization search space) 称为memo。 搜索空间会配置数据分布的参数信息从而找一个并行执行计划。
控制节点
- 一个engine service, 这个engine serice 是中央控制核心节点。
- 用户接口
- 使用sql-server 栈,负责parsing, 权限验证,生成分布式执行计划(DSQL Plan), 分发plan到计算节点, 跟踪执行进度, merge 计算节点的结果,返回结果给用户
- 元数据/configuration data存在控制节点的sql-server, 也存储global statics(local statics 存在计算节点的sql-server), aggregated statics of user, 用户数据的分区信息,用户的权限信息,但不存任何用户的数据
- 遍历搜索空间, 触发data movement, 并基于最小代价选择最终执行计划。
- 负责管理dms
计算节点
- 提供数据存储, 数据以分片形式或者复制形式分布在sql-server的table 上。
- 计算的主力节点
DMS
- 经常需要将中间结果从一个节点传到另外一个节点。有的时候,会把计算节点的数据传到控制节点做aggregation或者传给用户前的sorting。
- 用临时表来移动数据或存中间结果, 不过也可以, 用户sql 写成无临时表方式,这样计算节点的结果数据会以流式方式发给客户端,中间不涉及dms
DSQL
- sql 操作, 在计算节点上执行的sql 语句
- DMS 操作, 在计算节点之间进行搬迁数据
- 临时表操作, setup staging table 用于后续操作
- return 操作, push result to client。
一个步骤一个时间(应该是一种操作一个stage, 按照stage 进行流水线)。 单独一个步骤可以并行。
example
以tpch 为例:
1 | select c_custkey, o_orderdate from orders, customer where o_custkey = c_custkey and o_totalprice > 100; |
customer表按照c_custkey 分区, 但oder 表不是按照o_custkey分区, 因此,可能2个步骤
dms 操作: 对order 表按照o_custkey 进行repartition。
sql 操作, 计算节点选择tuple, 并最终返回结果给客户端
dms 操作,
- 用sql 语句提取原始数据
- tuple 路由策略
- 目标临时表
控制节点广播dms 操作到每个计算节点, 计算节点执行sql 语句
1 | select o_custkey, o_orderdate from orders where o_totalprice > 100 |
每个dms 读取本地的数据, 路由对应的数据到对应的dms上, 对o_custkey 进行hash, 并且接受从其他dms接受或扫描出来的数据插入到目标临时表。
- sql 操作
engine service 执行第二步,它会建立一个链接到每个计算节点的sql Server, 然后发送一个sql 语句,最后从每个计算节点中拉出计算结果数据
1 | select c_custkey, tmp.o_orderdate from orders, tmp where tmp.o_custkey = c_custkey ; |
cost-based 查询优化
优化过程, 参考下图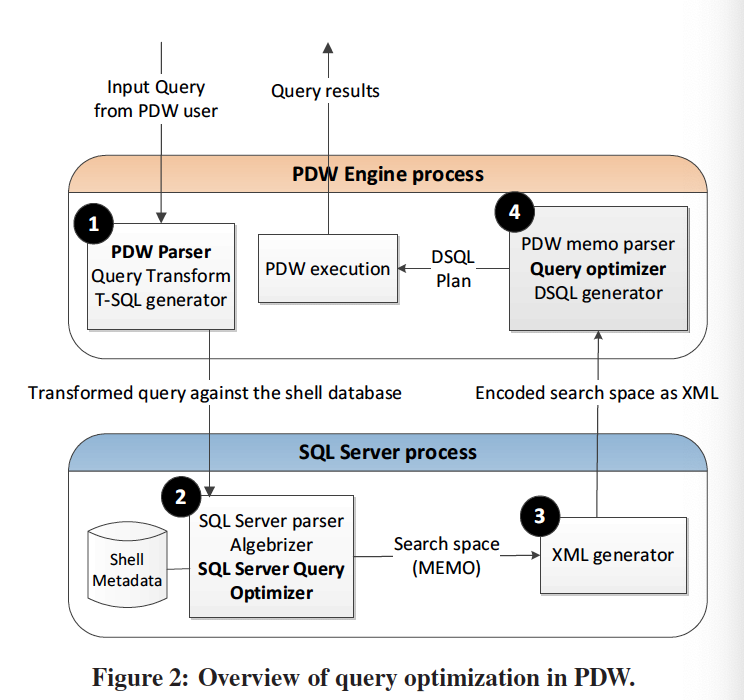
生成算子树
执行完算子树上logic exploration, 并且这个过程和单sql到sql-server过程一样。
pdw parser: 生成ast 语法树, 会做一些语法验证。 有一些query 会做一些基本的transformation。
sql server 优化: 转换后的query(这个地方有疑问是query还是ast?) 转发到shell database,sql-Server 输出的是一个相对优化的plan, 最优的串性计划不一定是最优的分布式计划,pwd 并不是用sql-server 来获得最优计划, 是自己来计算出来的。
- 简化输入算子树为一个格式化的form, 这个作为初始计划插入到memo data structure(memo hold 所有可选计划的搜索空间)
- logical transformation based on relational algebra rules.
- 评估每个执行计划的中间结果的大小, 根据base table 大小和列上statics
- implementation 阶段, 增加物理算子/物理算法 到search space 中。 计算cost 并做一些搜索空间的裁减
- 提取优化plan
xml generator, 将sql server 用memo 表达的搜索空间 用xml 来表示
pdw 优化: 消费xml generator的输出。
- 有个parser 解析xml ,生成memo数据结构
- bottom-up 优化, 基于cost base, 会在搜索空间增加data movement 策略和cost
还是以tpch 为例:
1 | select * from orders, customer where o_custkey = c_custkey and o_totalprice > 100; |

mem 由2个组成, 一个叫groups, 另外一个叫groupExpressions, group 表示一组等价的算子树,他们产生相同的输出。 为了减少内存使用量, 并不会对group 内所有的算子树进行评估。 groupExpress 是一个算子, 这个算子包含其他groups 作为孩子。如上图c 部分,逻辑算子是灰色, 物理算子是白色。 group 1, 有物理的table scan (可以通过pk或heap),sorted index scan (通过2级索引)。 group 4 包含所有的c 自然连接o 的等价表达式。 groupExpression 4.1 (join(1.3)) 表示所有的算子树, 树根是join, 第一个child 是group1, 第二个child是group3. 物理groupExpressions的孩子指向最高效的groupExpression. groupExpression 4.6 表示一个hash 算子, 他的左子树 是第3个groupExpression 在group 1 中, 右子树是第三个groupExpression 在group 2. memo 提供算子树的去重, cost 管理和其他的底层支持。
sql server 生成串性的memo后, 它会并行化参数, pdw 优化器会加入data movment group和操作到memo 基于数据的分布。 例如group 5 表示group 1 的输出 data movement, 假设c 表和o 表是不兼容的, 优化器会考虑这个算子来使c表和o 表 分区兼容 来执行 C 自然连接 o. group 6 表示group 2 这边的输出。 类似关系算子, logical data movment 操作有许多物理实现, 如shuffle, replication 等。 由物理算子组成的最终执行plan 从memo中提取出来。 这个eplan 转化为可执行的dsql plan。
为什么最佳的串性计划不是最好的? sql-server 优化器不清楚数据的分布, pdw 有额外的插入task 和data movement costing 来得到一个正确和高效的并行计划。 logical search space 基本上大家共同。 因此, 从sql server 导出logical search space 到pdw 基于pdw 的 目标。例如,在单机tpch中, join order 可能就是customer, order, lineitem 根据table size 来判断, 但pdw 中却是 order, lineitem, customer。 主要原因是order 和lineitem的co-location, 然后再对结果进行shuffle on custkey。
pdw qo 优化器实现
基于sql-server的修改
- 导出优化器search space。 加了个功能 类似“showplan xml”(已经在sql-server)。 这个入口点会trigger 任何pdw特定逻辑的使用, 它会输出xml,表示memo 结构。
- 扩展查询surface 以支持pdw。 pdw 是完全和sql-server 兼容。 这个扩展限制为 方便的query hint 以支持特定的分布式执行策略。
- 扩展优化器搜索空间, 包括一些选择,例如尤其是join/union的搭配的分布式执行。 transformation based 的架构让sql-server 不需要大的改动就可以支持这些扩展。
- 对于超大规模的搜索空间, 有超时限制,不会生成所有的计划。 会用一些执行计划seed memo, 这些执行计划含有分布式信息的table和操作配置
plan enumeration
最原始的enumeration 可能不成功但对query 很简单。 一个bottom-up 搜索策略, 一个top-down enumeration 技术
- 从最小的expression 开始优化, 不断迭代到整个query
- 特别留意 影响生成优化plan的物理属性。
- interesting 属性 表示 interdsting oders 的概念扩展, 来自system r。 特别的, pdw 考虑如下的colum 为interesting 在data movement: a。 join 列 ; b, group-by 列。 join 列是因为他们让local 或directed join 变的可能, group by 是因为可以在每个node 上进行本地aggregation并对结果进行union。
cost model
- costing data movement 是一个cost 子集。 相对关系运算, data movement的研发,测试和调试要更简单一些。
- data movement 有可能因为 物化数据到临时表中,从而在查询时间上占大头
- 不能依赖sql server 优化器来做这些事情, 它没有对应的操作。
cost model 假设
从头构建cost model 太挑战了, 当前cost dms 操作根据response 时间。
- 假设 dsql 步骤 的连续执行 (应该是pipeline 执行方式)
- 不是采用生产者-消费者 模式, 而是采用物化表的方式
- query 和query 之间独立
- 机器是同构的
- 跨节点统一的数据分布。
dms 操作类型
- shufle move (many-to-many).
- partition move (many to one).
- control node move (from control to compute node, tale in control node broadcast to all compute node)
- broadcast move.
- trim move. (初始在每个节点的复制table上, 目标是一个分布式table 在他自己的node, 对数据进行hash到目标table)
- replicated broadcast. tale in only one compute node broadcast to serveral nodes.
- remote copy to single node。 a remote copy of a replicated table/distributed table.
cost of dms operator

source component 是发送端, 分成2个cost 子组件。
creater, 从sql server 中读取tuple, 打包到buffer
cnetwork, 将数据从buffer 发送, 这个操作是异步
Csource = max(Creater, Cnetwork).
target component负责接受数据, 也分2个部分
Cwriter: 从buffer 中解压包,并准备插入到临时表
CsqlBlkCpy: bulk 插入, 这个操作是异步
Ctarget = max(Cwriter, CsqlBlkCpy)
Cdms = max(Csource, Ctarget)
costing of 一个单独模块
理论上, 模型越复杂, 评估越准确。 但实际上, 评估模型越复杂, 在data或statics 上轻微改变会越敏感。也导致了,cost model 越来越难debug和维护。 当前版本对每个组件的cost modle 基于处理的原始数据量: Cx = B * x, B 是原始字节数, x是每个字节的cost。
x 是个常量, 是通过目标性能测试计算出来。 称计算过程为cost calibration。 cost calibration 的结果显示 x 依赖row的数量, column 数量和column 类型。 观察的区别不足够明显来提高cost model 的复杂性。 因此x 考虑为常量而不管这些参数。 每个cost component 都有他自己的常量值x。 Creater 有2个常量, 一个是Xhash, 一个是Xdirect, 复杂hash 的overhead,
B 依赖input和output stream的分布式属性。 let Y 指示全局cardinality, w row的宽度 (memo 中的statictis 提供这2个值)。 let n 表示计算的node 数。 (Y * W/N) 对于分布式data stream, (Y * w) 对于复制stream
dsql 生成
一旦pdw 优化器选择了一个查询执行计划, 它会被翻译称dsql format, 这样可以在实际节点中运行。 不像其他mpp, 如greenplum 一样发送算子树到每个计算节点。 pdw 发送一个sql 语句到每个计算节点。 这个语句在每个计算节点的dbms 上运行。 执行dsql 生成 表示将算子树翻译成sql。 我们使用QRel 编程框架, 它封装了mapping 关系树到查询语句。 如下图所示。
先将物理算子树翻译为RelOp 树, 乐死sql server 输出代数算子树。 然后翻译为PIMOD ast 树通过QRel library. 最后为t-sql.