第四章 查询执行
每个系统在具体执行上有一些细微的出入, 不过大致的操作差不多
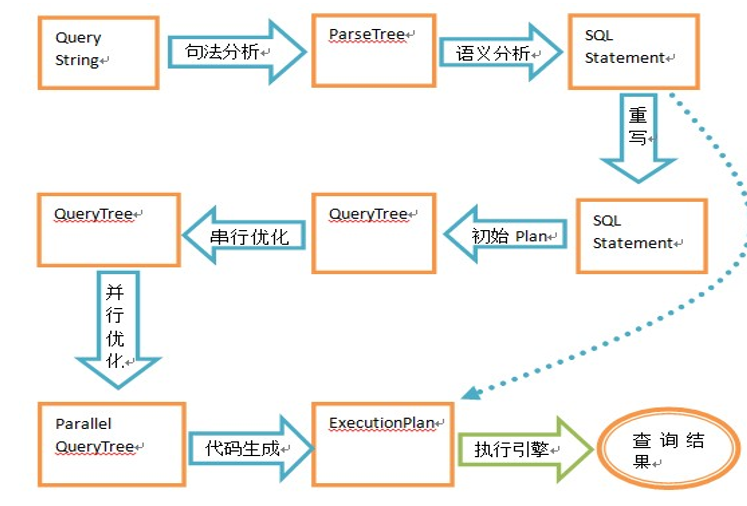
操作符介绍
操作符
| 符号 | 使用例子 | 解释 |
|---|---|---|
| select: σ | 选择,类似于SQL中的where。注意,和SQL中的select不一样。 | |
| project: Π | 投影,类似于SQL中的select | |
| rename: ρ | 重命名,类似于SQL中的as | |
| assignment:← | 赋值。 | |
| union: ∪ | 集合并,类似于SQL中的union | |
| set difference: – | 集合差,sql中except | |
| intersection: ∩ | 集合交,SQL 中intersect/intersect all | |
| Cartesian product: x | 笛卡尔积,类似于SQL中不带on条件的inner join | |
| natural join: ⋈ | 自然连接,类似于SQL中的inner join, join… on.., join … using…, natural join | |
| distinct: δ | ||
| group by 分组γ | ||
| sort Γ |
扫描
- 全表扫描
- 索引扫描
衡量代价的参数
- 需要一个参数来表达操作符使用内存的大小。
- 磁盘io代价
- 用B/T/V 来参数化一次io, B 表示读取块的数目(顺序扫描), T表示记录数(随机扫描), V 表示cardinality
迭代器
迭代器
- open
- getnext
- close
举例: tablescan的迭代器
举例 r U s 
操作符算法
算法目的是 将逻辑计划转变维物理计划。
算法难度
- 1次性全部load 到内存
- 2次读取磁盘, 第一次读取出来,做某种操作,写回磁盘, 下一次可以一部分一部分的读取到内存
- 多次读取
操作对象
- 一元操作, 一次一个record
- 整个关系, 但是一元操作
- 整个关系, 2元操作, 比如并/交/差/连接/积
操作代价
- 对于像select/project 这种都是一元操作, 只要满足cache 能完整容纳一行即可, 操作的代价,如果数据是聚集的就是B, 如果是离散的,就是T。
- 对于像distinct、group by 操作,都是在一个关系上的一元操作。
- 可以使用hash table或b 树来存储key, 当数据量超过内存时, 会出现overload, 容易颠簸
- 分组, 分组常常伴随聚集计算。 可以每个组用一个record来计算, 但必须扫描全部分组后,才能完整输出。
- 二元操作,比如像并、交、差、积和连接。 常常将较小的放到内存中, 较大的逐行扫描。
嵌套循环连接
2个关系中, 一个关系只需读取一次, 而另外一个关系需要循环读取多次。
关系r 自然连接 关系s时, 有2种改进
- 查找r上匹配的record时,可以使用r上索引, 前提是连接键含有索引
- 执行内层循环时, 可以用缓存减少io。 (memory hash join和 grace hash join和hybrid hash join)
nestloop join的算法
r 通常是大表, 带索引, s是小表, s是驱动表, 又称外表。 r是被驱动表又称内表。
做缓存改进, 一次将一个block 读进内存, 然后再对这个block数据进行遍历
排序
两阶段多路归并排序
假设现在是1千万个record, 一个record 100个字节, 可进行merge sort 的内存为10MB
第一阶段, 从文件中一次读取10MB, 然后在内存中,对他进行排序, 将这次排序结果存到文件中, 依次完成遍历1千万个record, 这样大概100个文件。
第二阶段,
- 从每个文件读取 [(10MB)/((100+1)* 100)] (真正在操作中是10M = 100 * 100 * x + 100 * y, x 为预读记录数, y为输出记录数, x不一定等于y, 不过100 * x 和100 * y 都应该是页大小的整数倍), 大概每个文件读取90个record, 其中100个为input block, 1个为output block
- 从这100个cache block 中挑选最小的90 个record 存到 一个output block中
- 当output block 满了, 刷到磁盘,然后清空output
- 当某个排序子文件的input block 的记录被使用完, 读取下一个block, 直到本文件全部读取结束。
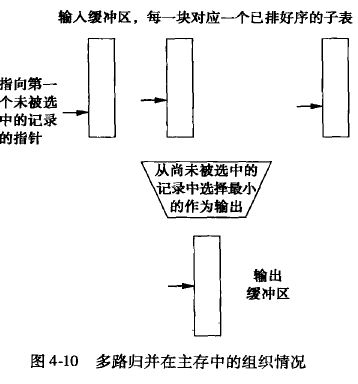
磁盘io 代价,基本为3次文将读写
归并排序算法上,还可以进行
- distinct
- aggregate, 排序算法可以被用到group by的操作中。
- 表的二元操作, 并
- 表的二元操作, 交、 差
基于排序的简单merge-sort join
R(X, Y) 和S(Y, Z)
- 用y作为关键字, 进行R 排序
- 用y做关键字, 对s 进行排序
- 各用一个block, 给r或s 做当前块
- 做join操作, 如果join
- 输出结果
整个io次数差不多5 * (r + s)
基于排序的merge-sort join 增强版本。 可以做一些优化, 排序-归并-连接
- 以y 为关键字,分别对r和s 进行一个block 一个block的排序, 则会有很多排序的子表
- 将每一个子表的第一块调入缓冲区,
- 直接进行join
- 将join结果输出
整个io次数差不多 3 * (r +s)
基于hash的2趟算法
- 在内存中分了M块, 其中M-1 块用于 hash table的桶, 剩下一块为读取的cache。

基于hash的distinct算法
将每个数据hash到每个桶中, 差不多每个桶的大小为B(R)/M-1, 如果 这个桶的大小可以被load到内存, 可以用2次hash 进行去重。
磁盘io 大概是3B(R)
基于hash的group by或aggregate
hash 分桶后,还是需要依次处理
缓冲区管理
LRU 算法
FIFO 算法
时钟算法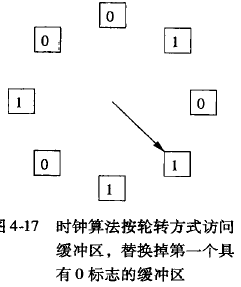
- 每个block 都有一个标志0或1
- 当一个块被load到缓冲时,标志改为1, 当一个块被访问过,也被设为1
- 当指针旋转一圈后, 会把没有改变的缓冲设为0
- 当块要load到缓冲时,选择为0的缓冲区