LangChain "不务正业",居然从零造了个数据库?
LangChain 作为世界上最懂 Agent 的公司,突然从零写了一个分布式数据库。是顺势而为,还是迫不得已?
最主流的 Agent 框架公司,居然开始做数据库了?
先交代下背景:LangChain 是全球最主流的 AI Agent 开发框架之一,数以万计的开发者用它来构建各种智能体应用。2026 年 5 月 13 日,LangChain 发了一篇官方博客,标题显得十分平静:《We built SmithDB, the data layer for agent observability》[1]。
一个做 Agent 框架的公司,从零开始,顺手写了个分布式数据库。听起来就像:一家面馆,突然开始卖起了面粉(大概率是被现实撞了满头包之后的选择)。

这里再多补充一个背景:LangChain 生态里有一个叫 LangSmith 的重要工具,专门用来观测 Agent 的每一次推理、每一次工具调用、每一次对话。LangSmith 原本用的是 ClickHouse——业内顶级的分析型数据库。
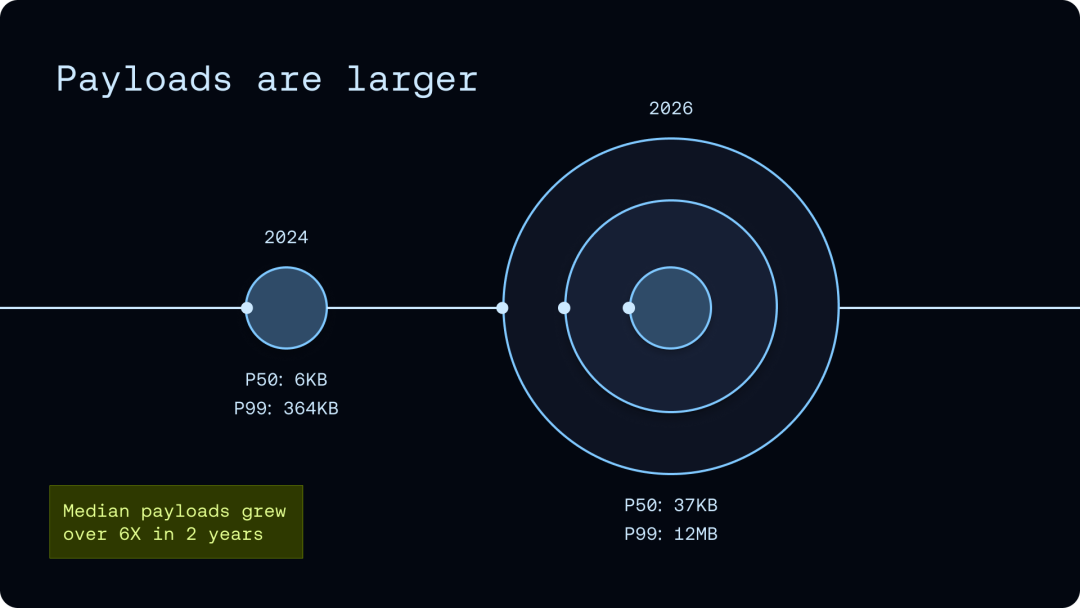
他们遇到的问题是现在的 AI Agent 发展速度太快,一次 task 或者 trace 里都能套出几百个嵌套 span。LangSmith 用户每天往里灌的数据太多,在 ClickHouse 的架构中行不通,数据量和 payload 都爆了。
“only supports multi-replica clusters (read scaling), not multi-shard clusters (write scaling)”。ClickHouse 支持读扩展,但写扩展支持得不好。读可以堆机器,但写只能硬扛。
LangChain 对于解决这个问题的选择是——直接掀桌,自己”原创”了一个分布式数据库 SmithDB。
亮点一:把 Agent trace 当成一种新的数据类型
SmithDB 的第一个亮点,是它不是把 trace 当成普通日志存,而是把 Agent trace 当成一种新的数据类型来处理。
传统日志系统更擅长处理一条条已经结束的记录,但 Agent trace 不是这样:一个 run 可能拆成多个事件,一个 span 可能长时间保持打开状态,输入输出里还可能混着大段 JSON、文本、多模态内容和工具调用结果。
亮点二:架构拆得很轻
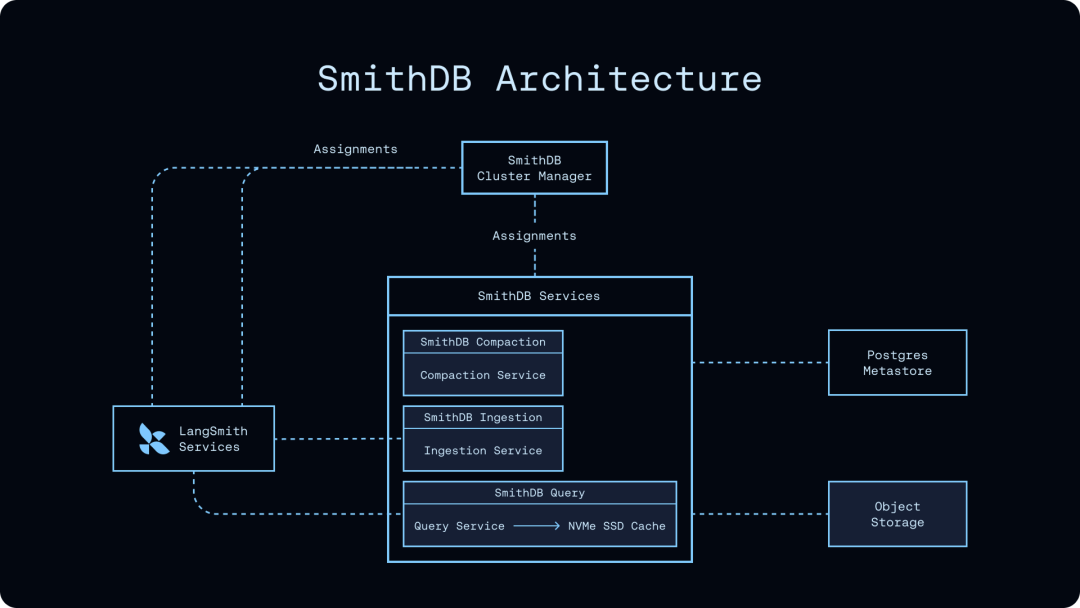
第二个亮点,是它把架构拆得很轻:底层用对象存储放持久数据,用一个小型 Postgres metastore 记录 segment 元数据,查询、写入、compaction 服务都尽量做成无状态。这样扩容的时候,不是去维护一堆带本地盘的复杂数据库节点,而是加计算资源。
亮点三:热数据就近读取
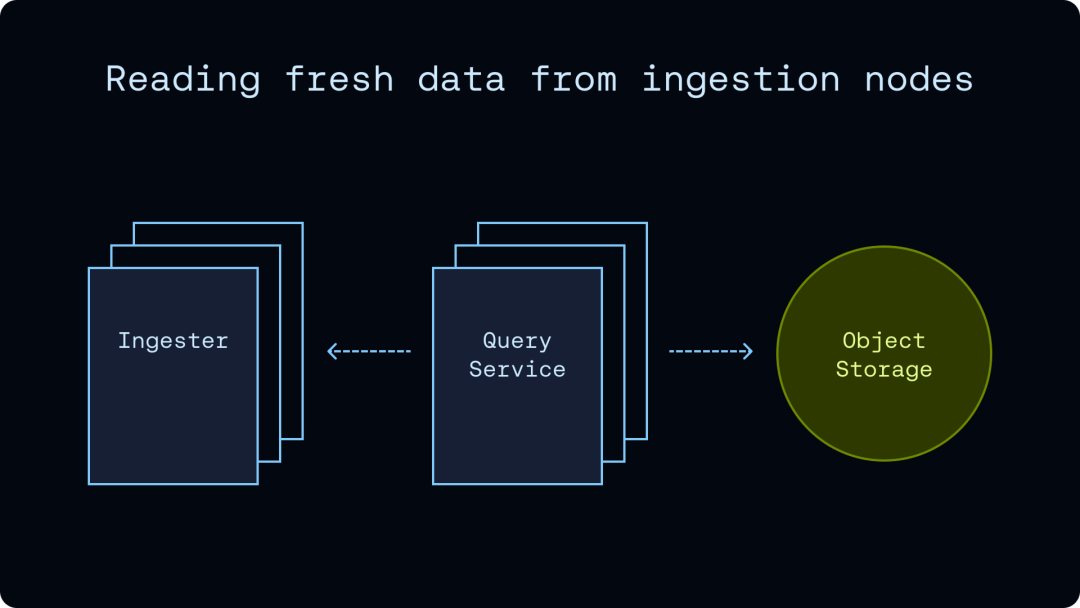
第三个亮点,SmithDB 会记录每个 segment 是哪个写入节点产生的,如果这个节点还在线,查询就可以直接从这个节点读最新数据(这个思路很像传统数据库的 LSM Tree)。
亮点四:run 是”一串事件”,不是”一行记录”
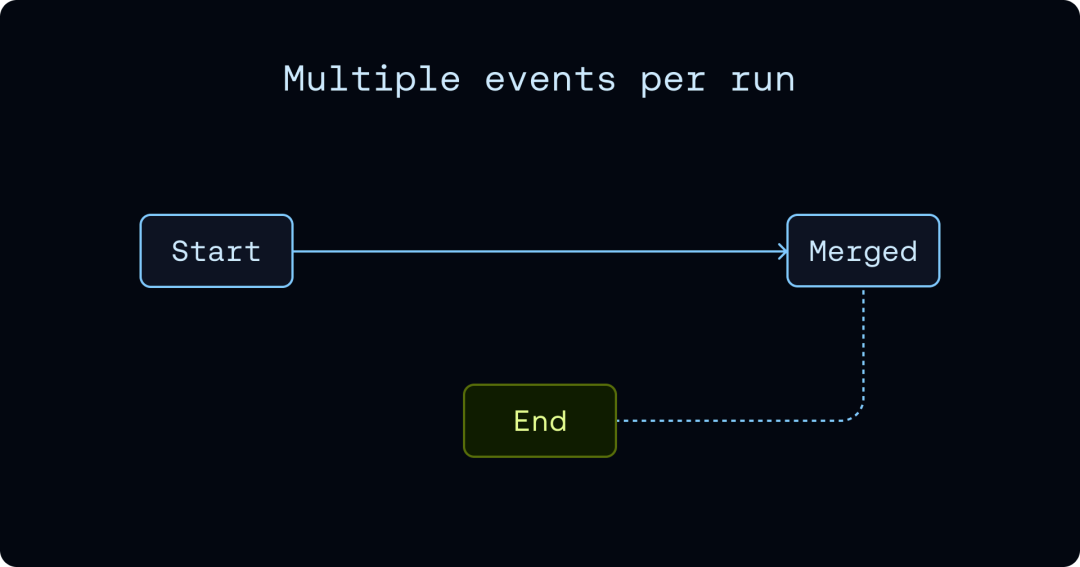
最后一个亮点,是它把 run 看成”一串事件”,不是”一行记录”。SmithDB 专门为这个模型做了事件 fanout、merge 和 compaction 策略。
SmithDB 的性能数据也相当能打:Trace 树加载 P50 延迟 92 毫秒,单次 run 加载 71 毫秒,全文搜索 400 毫秒。相比 LangSmith 原来的体验,快了 12 倍。
但兹拉坦认为:真正的看点不在性能提升上的数字,在于 SmithDB 是专门为 Agent trace 设计的。
这件事真正有意思的地方,可能不在技术本身
LangChain 造 SmithDB,说明了一个比技术更重要的行业判断:Agent 运行时产生的那些数据极其重要,但通用数据库不一定能承载好。
Agent 的数据和传统数据库完全不是同一个画风。它是半结构化的,一段 JSON 里混着自由文本和向量。它是高频写入的,一次对话能爆出几十条记录。它是长生命周期的,一个 span 从开到关横跨好几个小时。

数据绿色循环,让生活更美好
Agent 最宝贵的资产,是它在你这儿跑出来的那些”个性化经验”。这些原始数据如果能被沉淀下来、提炼出来、再喂回去,Agent 就开始”长记性”了。
LangChain 显然懂这件事,SmithDB 社区博客里那些”text search”、”JSON filtering”、”tree-aware queries”,翻译过来就是——我们不只是存 trace,我们要让 trace 能被喂回去、用起来。
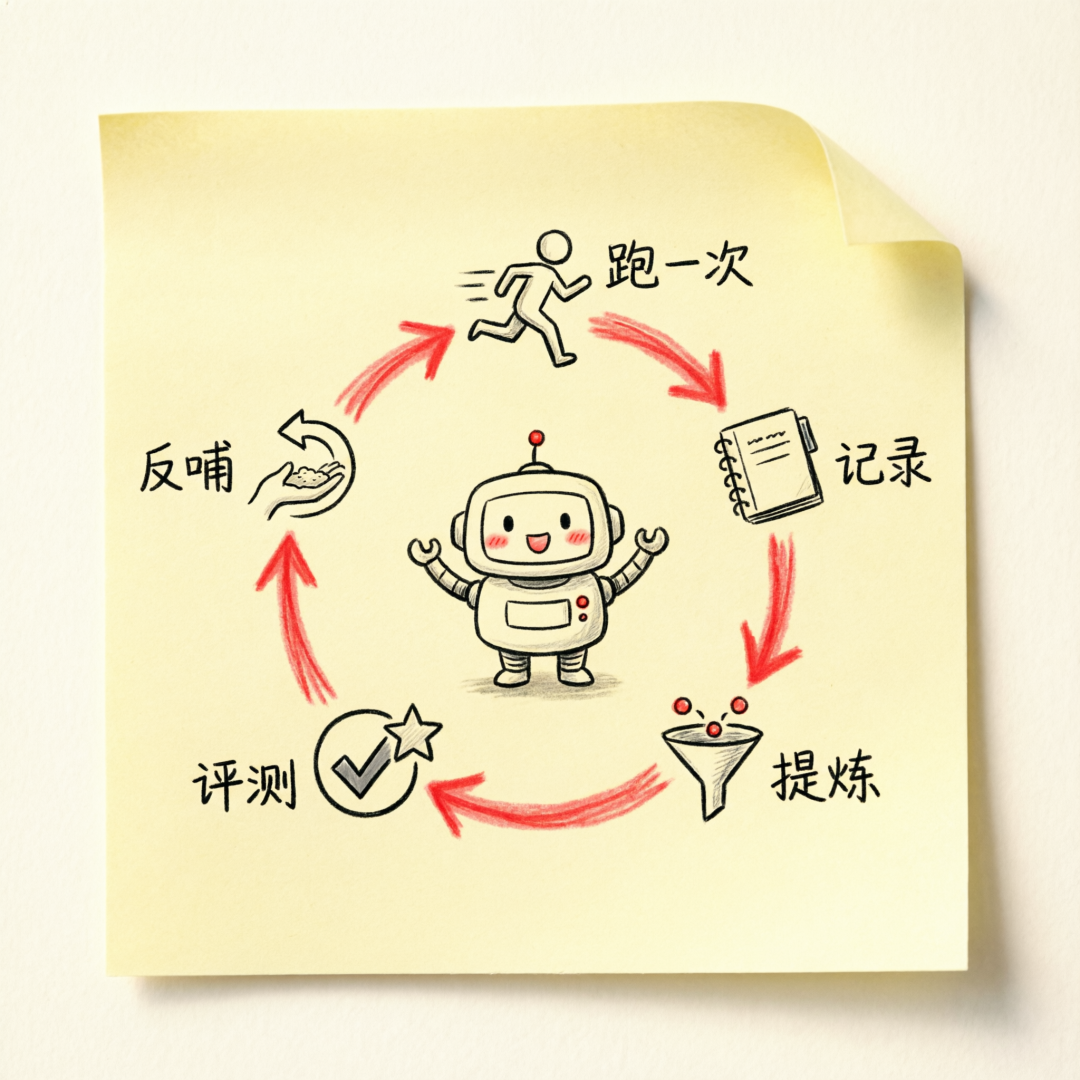
Agent 跑一次,就聪明一点点。循环越密,进化越快。
AI Agent 的”数据饥饿”问题


随着 AI Agent 越来越频繁地遇到”数据饥饿”问题,LangChain 的做法很有意思。
兹拉坦认为:LangChain 等 Agent 公司自研数据库,目前还处在非常原始的”发现某些场景玩儿不转,然后就去补”的阶段。AI Agent 发展的速度极快,过几天大概率还会再遇到诸如数据分片、容灾备份、安全合规等新问题。
一些思考
LangChain 这一手,捅破了一层窗户纸:Agent 跑出来的那些破事:推理链、工具调用、上下文、反馈,很多数据库都扛不住。

这事不只是 LangChain 一家在头疼。Claude Code 的对话历史存哪?JSONL 文件。OpenClaw 呢?Markdown。讲究点的团队上了 SQLite。想加向量?装个 pgvector。要存上下文?再来个 Redis。数据在它们之间来回搬运,搬一次掉一次精度、烧一次 token。

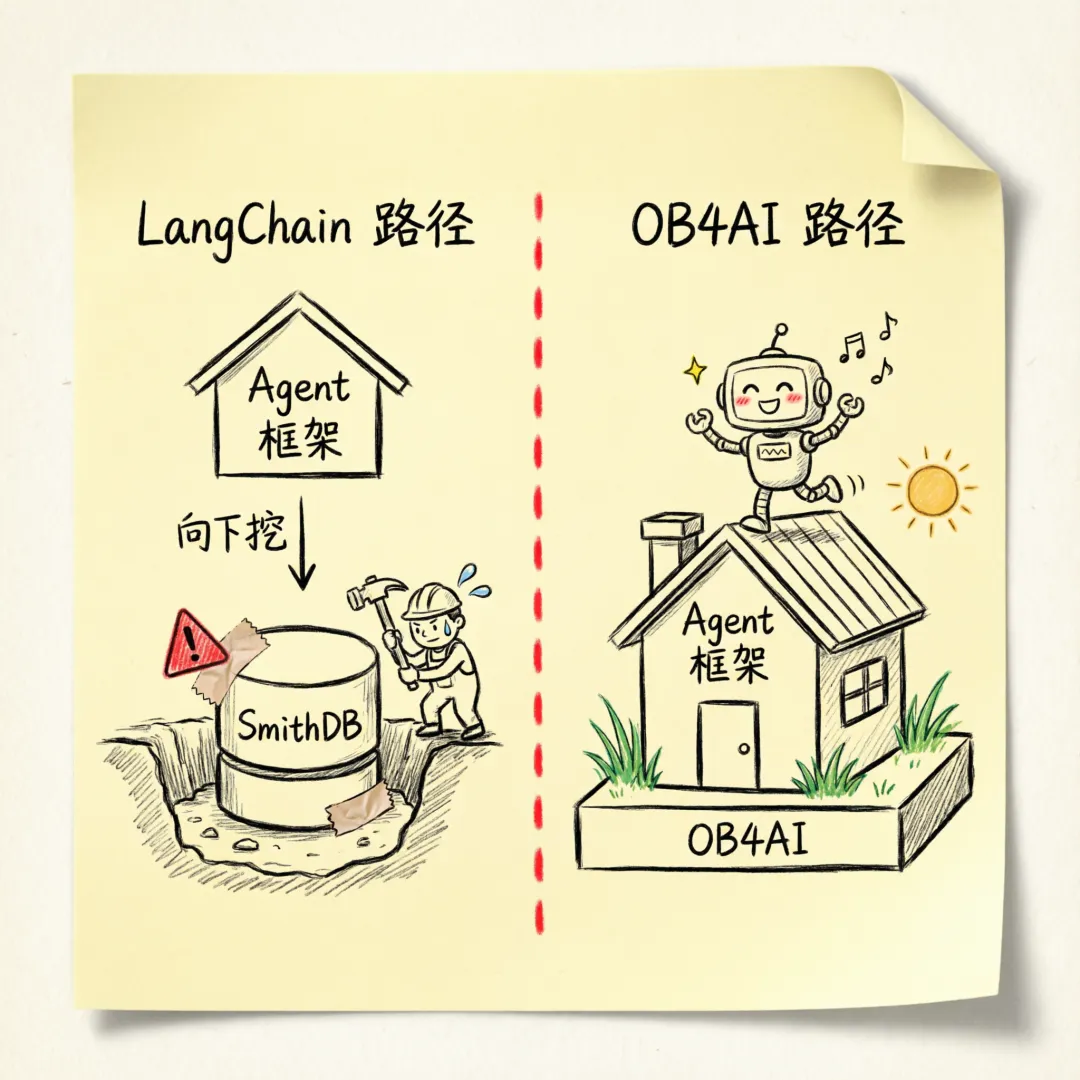
LangChain 从 Agent 框架往下,做了一层数据库。那反过来呢?从更成熟的数据库层往上,去接一层 Agent 框架?让 Agent 从第一行代码跑起来,产生的数据,天然就在一个非常成熟的数据库里。

这跟 LangChain 的路数构成了一个有趣的对照。LangChain 正在踩的那些数据库的坑,数据库公司 N 多年前早就踩完了。
1 | Agent 运行产生数据 → 存进 OB4AI |
| 做法 | 特点 |
|---|---|
| 传统做法 | 循环的每一步都在不同系统里完成,数据搬运成本极高 |
| “也许”更好的做法? | 所有数据从一开始就在同一底座上,整个循环是”内循环” |
What’s more?
LangChain 用自研 SmithDB 证明了:Agent 行业正在从”卷谁的模型更聪明”走向”卷谁的数据底座更扎实”。
5 月 30 日,OceanBase × LangChain Meetup 上会有新产品的重磅发布!
Reference: 《We built SmithDB》: https://www.langchain.com/blog/introducing-smithdb