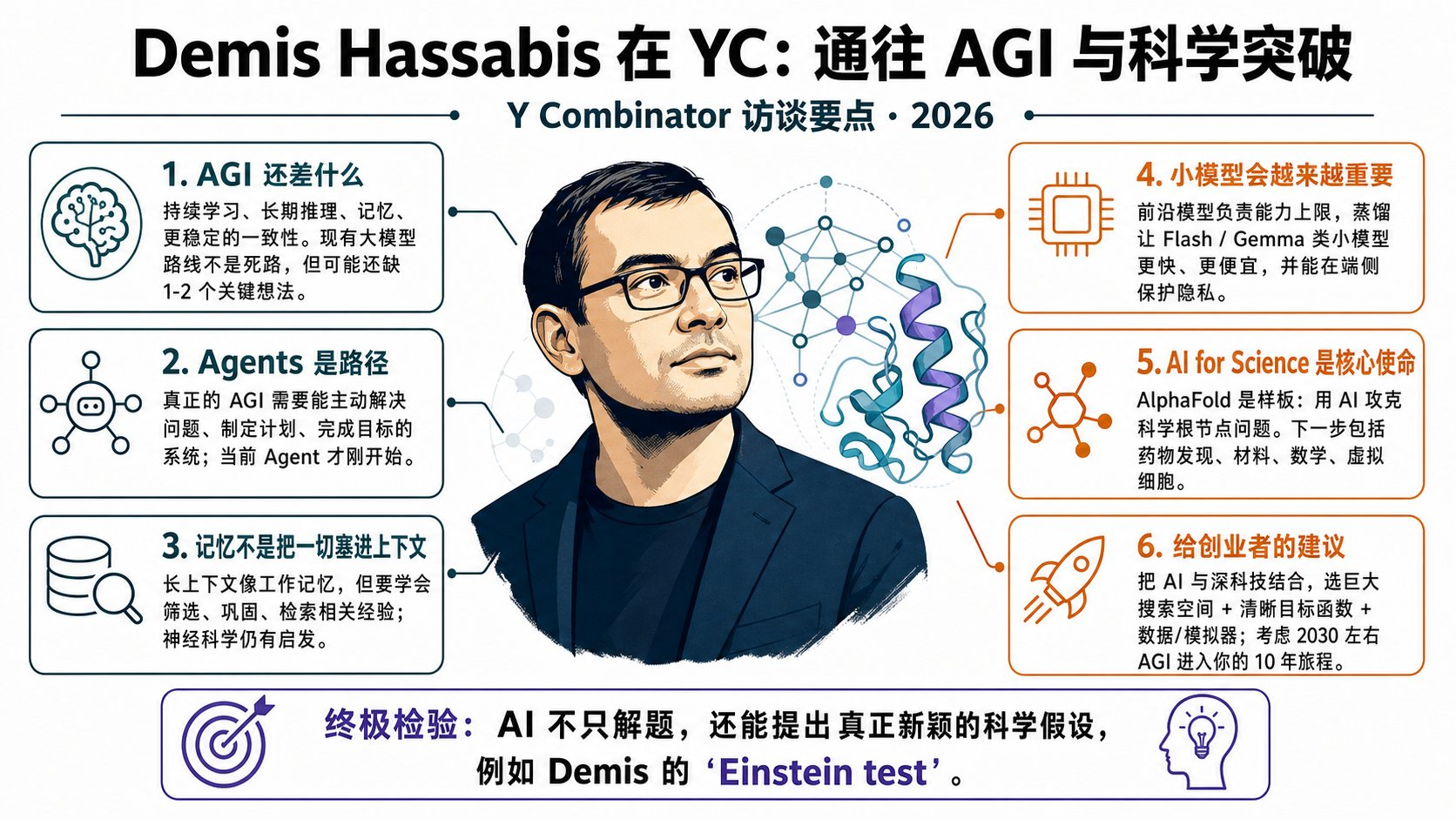
DeepMind CEO 访谈:人类离 AGI 只剩 4 年,只差最后 3 块拼图
楔子
前几天(4 月 29 日),Google DeepMind CEO、2024 年诺贝尔化学奖得主 Demis Hassabis 在一期播客节目《Agents, AGI & The Next Big Scientific Breakthrough》 中,预测 AGI(通用人工智能)有望在 2030 年实现,并介绍了当前 AI 的致命短板(为什么现在还不是 AGI)。
看完之后,小编的感受是——这可能比今年任何一场 AI 产品发布会都值得看。
不是因为发布了什么新模型,什么 benchmark 跑到了宇宙第一。恰恰相反,Hassabis 花了大量时间讲一件事:现在的 AI,到底还差什么?
Hassabis 的答案不长,但每个都很致命:
- 持续学习(Continual Learning):不能像人一样终身学习、不断更新知识
- 长程推理(Long-term Reasoning):复杂逻辑链、多步骤规划能力极弱
- 真正的记忆(Memory):不只靠上下文窗口,而是结构化、可索引的长期记忆
“A true general intelligence system shouldn’t have that kind of jaggedness.”
一个真正的通用智能系统,不该有这种锯齿。
他直言因为这三个问题,现在的 LLM 只是 “一半天使、一半智障”,甚至给现在的 AI 起了个不太好听但极其贴切的名字——“锯齿型智能”(Jagged Intelligence)。

什么意思?就是虽然 AI 能拿国际数学奥赛金牌,但却可能会因为无法持久地记住历史会话和用户偏好,而在面对简单问题时,无法做出正确的决策。接下来,我会把访谈里几个最核心的方向和短板,拆开聊上一聊。
一、暴力堆砌的上下文窗口 ≠ AI 记忆
你一定注意到了,最近各家大模型在比赛一件事:谁的上下文窗口更长。
从 4K 到 128K,到 100 万 token,到 1000 万 token。好像只要上下文足够长,什么问题都能塞进去解决。
然后他算了一笔让我愣住的账。现在最大的上下文窗口是 1000 万 token 对吧?Hassabis 的原话是 100 万 token = 约 20 分钟视频。按这个换算,即使放大到 1000 万 token,也就 200 分钟的视觉信息。
听起来很厉害,但本质上是暴力堆砌。 对于一个需要理解你数天、数周、数月,甚至数年生活、工作习惯的 AI 助手来说,200 分钟算个啥?
而且现在的问题不只是容量。更重要的是——现在的做法是把所有东西一股脑塞进 Context Window(上下文窗口),包括不重要的、错误的、过时的信息。每次对话本质上是无状态的。关掉窗口,上一轮聊了什么,全没了。
Context Window 其实就相当于人脑里的 Working Memory,工作记忆。人的工作记忆能同时装多少东西?心理学里有个经典数字,7 个左右。比如让你背一个朋友的电话号码,其实能记住 7 位左右,因为位数再多就“溢出”了。
而大模型呢?已经做到 100 万 Token。按理说,模型的工作记忆比人大几十万倍,应该比人聪明几十万倍才对。
但,显然不是。
记忆的本质:海马体 & 持续学习
Hassabis 拿 AI 和人脑做了个对比,因为这位大佬读博士时研究的就是:海马体如何把新知识优雅地融入已有知识体系。
问题也恰恰就出现在这。AI 习惯把所有东西都塞进 Context Window 里,里面包含了不重要的东西、错的东西、过时的东西。看起来信息很多,其实是一团乱麻。
那人为什么 7 个数字的工作记忆就够用?
因为人脑背后还有另一套机制在工作。我们记得几年前的事,记得童年的事,记得几小时前发生的事。这些都不塞在工作记忆里,而是另一套系统,这套系统,就是刚刚提到的海马体,大脑里负责把新知识整合进已有知识库的那个部分。
Hassabis 在播客中介绍说,人脑在快速眼动睡眠(REM sleep)期间,会回放白天的经历,主动判断哪些值得记住、哪些应该遗忘,然后把有价值的经验“写入”长期记忆。
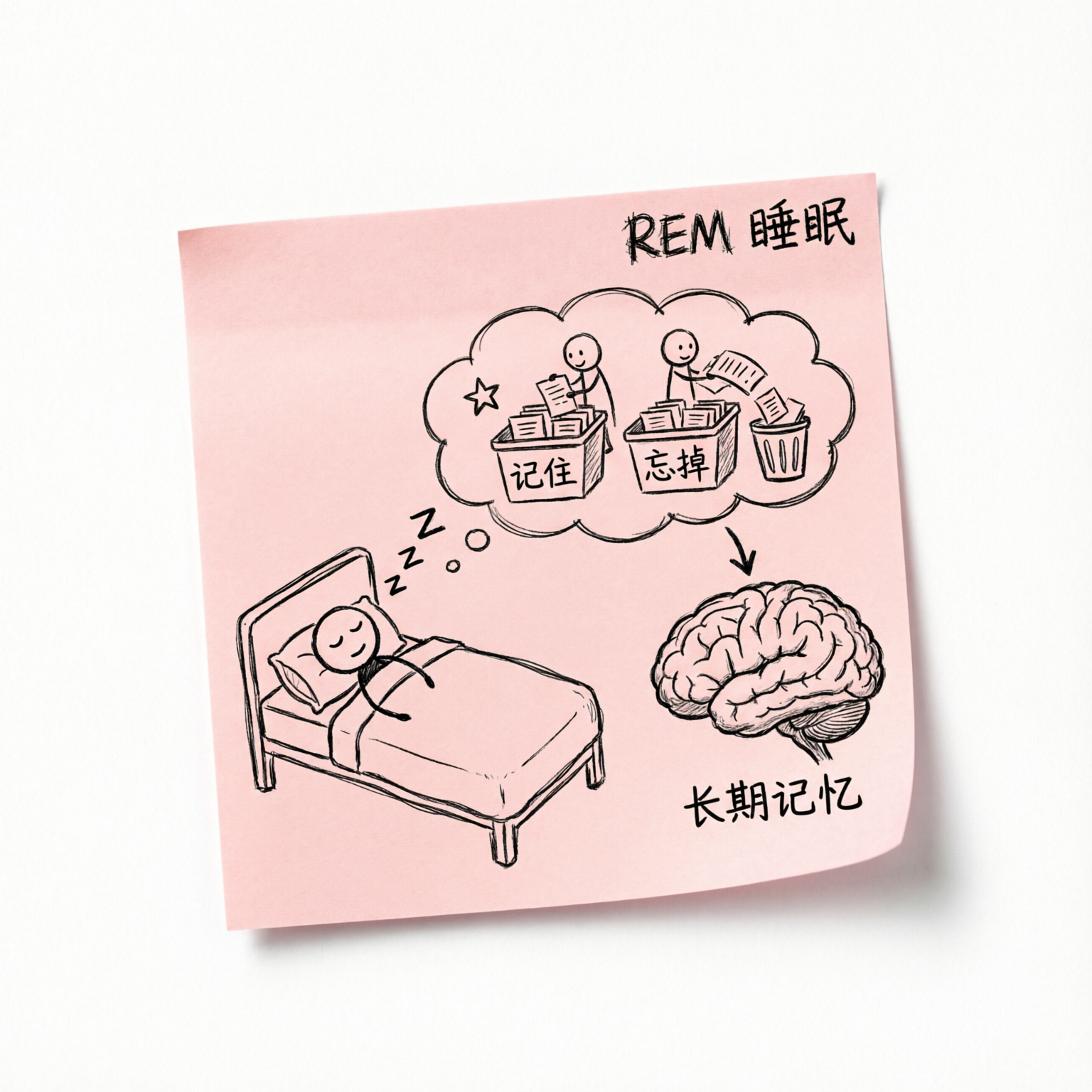
2013 年 DeepMind 那个名震一时的 DQN 算法(第一个在雅达利游戏上达到人类水平的深度强化学习系统),一个关键技术就是从这里借来的——经验回放(experience replay),反复回放成功路径来学习。这件事,放在 AI 领域,已经算是上古时期的了。
这个把新东西融进旧知识库的过程,就是所谓的持续学习(Continual Learning)。
2026 年,AI 普遍还没有做到这一点。
AI 海马体,应该长什么样子?
Hassabis 在播客的观点很清晰:AI 需要一套独立的、高效索引的记忆模块——能主动决定记住什么、遗忘什么。这是 AI Agent 在长时间维度可信赖地自主运行的前提条件。
换句话说,上下文窗口只是一张越摊越大的桌面。AI 真正缺的,是一颗海马体。

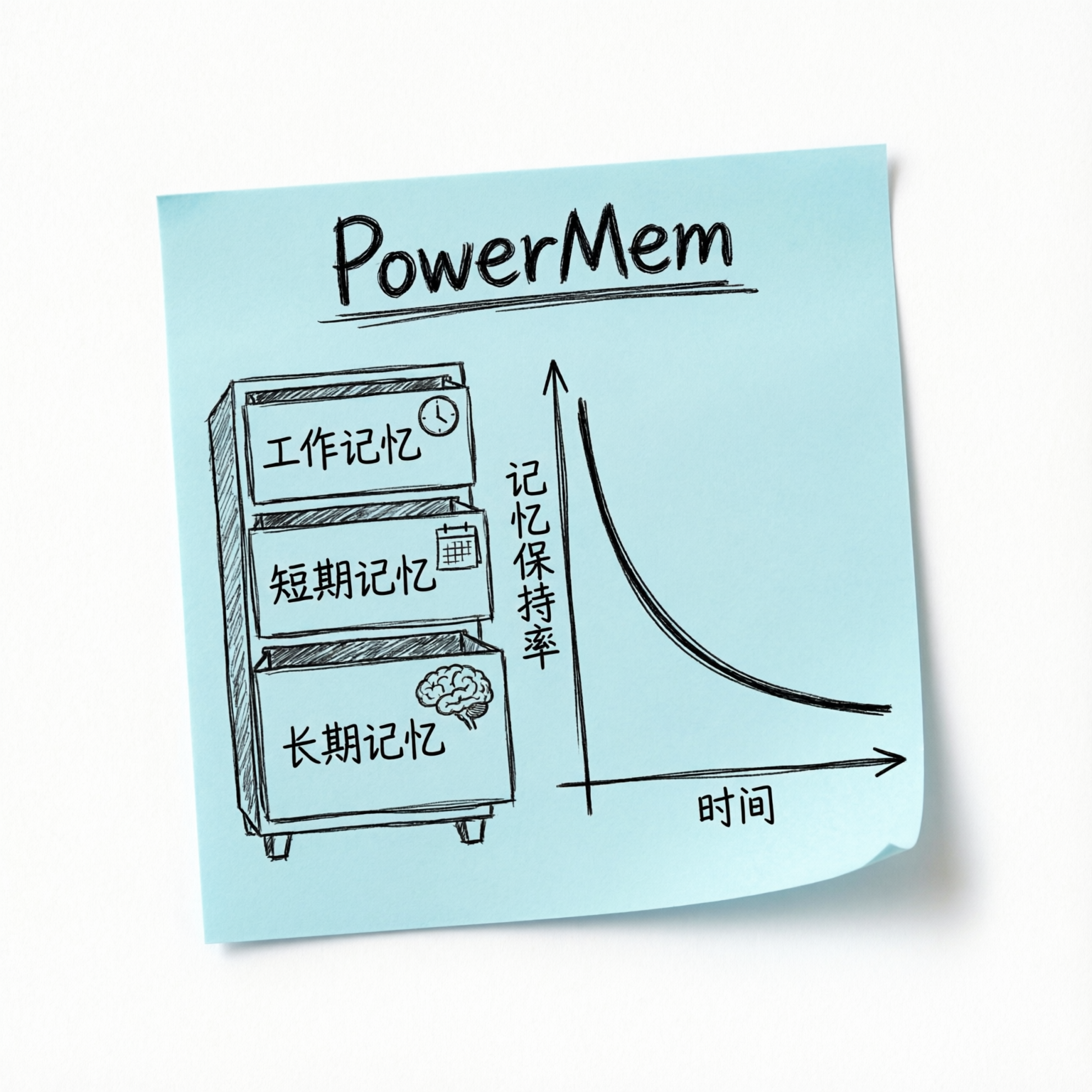
PowerMem
小编参与的一个 PowerMem 开源项目,就专门为 AI Agent 加上了这个“海马体”——一套能够持久化 & 持续学习的记忆系统。
它的思路和 Hassabis 描述的方向高度一致:
- 不是把所有对话都塞进上下文,而是从对话中提取关键事实,按工作记忆、短期记忆、长期记忆分层管理
- 引入艾宾浩斯遗忘曲线机制——用到的记忆会强化,长期不用的记忆会逐渐淡出,甚至自动清理(和 Hassabis 说的“主动决定记住什么、遗忘什么”异曲同工)
- 支持向量 + 全文 + 图谱三路混合检索,多 Agent 之间可以做记忆隔离和共享
而且有一个数据很直观。在长对话记忆基准测试 LOCOMO 上:
| 指标 | PowerMem | 全上下文方式 |
|---|---|---|
| 准确率 | 78.70% | 52.9% |
| 检索 p95 延迟 | 1.44s | 17.12s |
| Token 消耗 | ~0.9k | ~26k |
同样的任务,用 PowerMem 的 token 消耗只有全上下文方式的 18%。少了 82% 的 token,结果反而更准——因为,不是所有旧对话都有价值。
Python SDK 一行 pip install powermem 就装好,也支持 CLI(pmem 命令行)、HTTP API + Web Dashboard、MCP Server。OpenClaw 框架可以直接通过 memory-powermem 插件接入。
当然,这可能还达不到 Hassabis 描述的那套人类的“能在梦中回放和整合经验”的完整记忆系统。但方向是对的:记忆,不该只靠暴力堆砌的上下文窗口硬撑。
seekdb M0
除了 PowerMem 之外,小编参与的另一个项目 seekdb M0 也是专门为 AI Agent 设计的自进化的云记忆,支持一键接入,分享经验,无限进化。
seekdb M0 有一套记忆和经验提取、验证、注入、反馈的闭环,驱动 AI Agent 持续迭代。
- 自动提炼工作经验,新任务启动即自动注入相关最佳实践,无需手动检索。
- 当经验被 Agent 成功验证 3 次以上,将进入经验池,开始为其他 Agent 提供服务。
- 基于 Agent 反馈结果动态调整权重,优胜劣汰,持续优化
二、模型蒸馏 —— 大模型有多强,六个月后你的手机就有多强
访谈中另一个让我反复回看的判断,是关于模型蒸馏(Distillation)。
Garry Tan 问了一个很多人都好奇的问题:小模型到底能聪明到什么程度?蒸馏有没有理论极限?
Hassabis 的回答很干脆:
“我不觉得我们已经碰到了信息论上的极限。至少目前没人知道有没有碰到。我们的假设是,一个前沿的 Pro 模型发布后,在半年到一年内,它的能力就能被压缩到非常小的、几乎可以跑在边缘设备上的模型里。”
他给了具体数字:蒸馏后的小模型可以达到前沿大模型 90-95% 的能力,成本仅约十分之一。
这不是远期展望,而是正在发生的。DeepMind 自家的产品线就是这套逻辑:Gemini Pro(前沿旗舰)→ Flash(蒸馏后的消费级推理)→ Nano(端侧设备)。开源的 Gemma 4 模型发布两周半,下载量达到 4000 万次。
“小模型的价值不只是成本低。速度快同样会带来巨大的好处——你能迭代得更快,迭代速度赚回来的,远超那 10% 的能力差距。”

Hassabis 还特别提到了边缘场景的意义:车载设备、智能穿戴设备、具身机器人……这些场景不光需要效率,还需要隐私和安全。
“想象一下你家里的机器人,你会希望本地跑一个高效且强大的模型,只在特定场景下把任务委托给云端大模型。音频和视频流都在本地处理、数据留在本地——这是一个很好的终极状态。”
这话让我想到一个正在发生的趋势:当大模型的能力以 6-12 个月的周期“流”向端侧,一个很自然的问题浮现——端侧设备上,谁来给这些小模型提供数据底座?
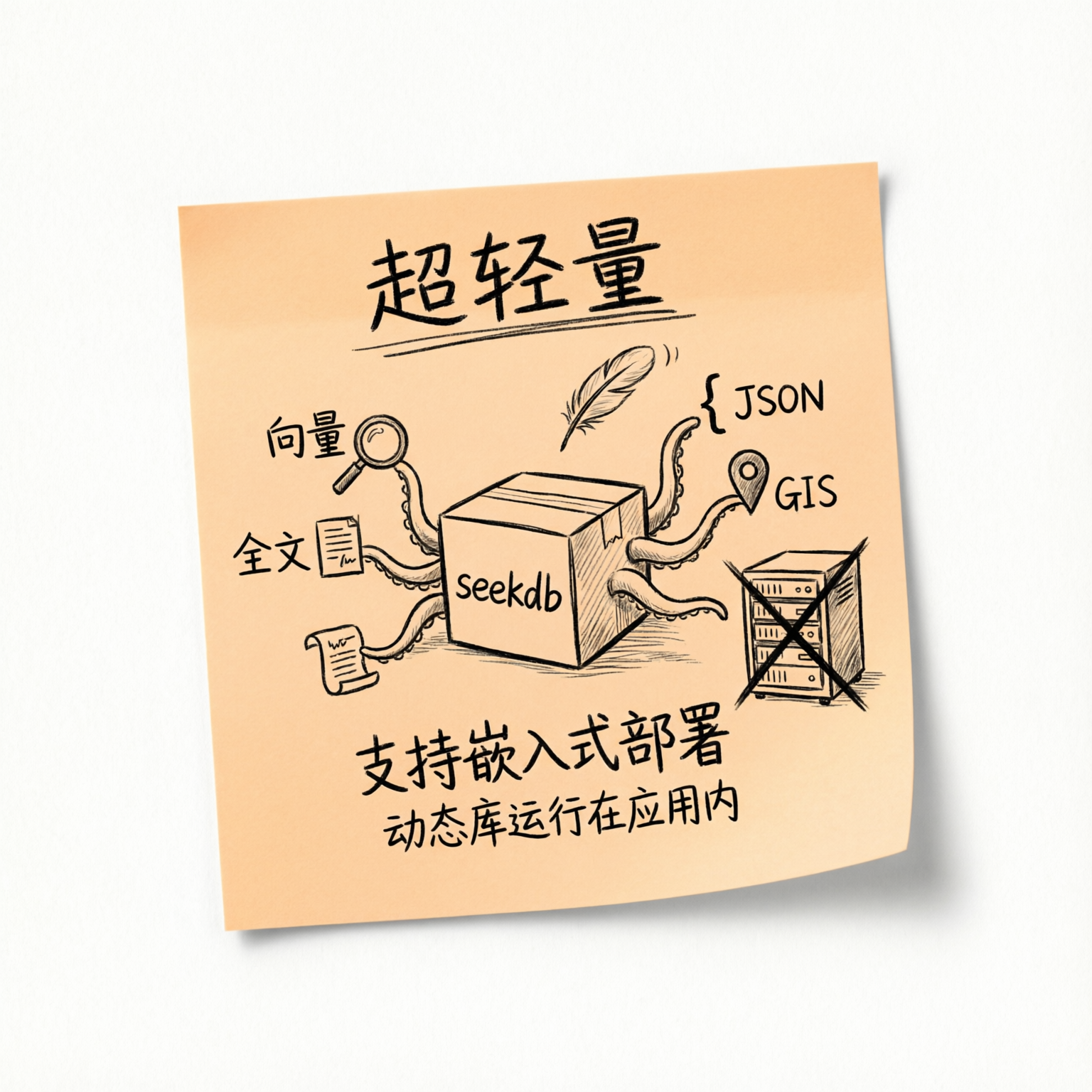
它需要边缘设备上跑一个完整的传统数据库实例,同时还要让它支持向量检索、全文搜索、结构化查询。
这就是小编参与的另另一个项目 —— seekdb 瞄准的方向。
- seekdb 的服务器模式,只需要 1C2G 的资源,支持
pip install一键安装、秒级启动。 - 嵌入式模式甚至可以作为一个 Python 库,直接运行在应用程序内部,不需要独立数据库进程,几乎没有任何资源开销。
- 同时塞进去了向量检索、全文搜索、JSON、GIS——一个引擎全包,兼容 MySQL 语法,学习成本极低。
关于 AI“从重到轻”的大趋势,小编之前写过两篇文章来分析。这里不再继续展开,感兴趣的可以翻翻看~
Hassabis 的判断让我更加确信:端侧智能不是“未来某天的事”,它以 6 个月为周期在逼近。 那些能在极低资源开销下提供完整 AI 数据能力的基础设施,很快会从“可选”变成“刚需”。
三、AI 安全只写在 prompt 里,还远远不够
Hassabis 在访谈中花了不少篇幅谈安全。他的核心判断:
“目前的 AI 系统在网络攻防方面已经相当强了。关键是要确保防御能力跑在攻击能力前面。”
他认为 AI 是典型的“双重用途”技术——既能加强防御,也能被利用来发现漏洞、自动化攻击。最紧迫的风险有两类:
- 恶意人类行为者利用 AI 发动攻击
- AI 自主性增强带来的长期对齐问题
第二点尤其值得警惕。随着 AI Agent 越来越能“自己做判断”,“它自己做了个判断然后把你的数据搞没了”这种事已经不只是理论推演。PocketOS 数据被 Agent 误删的事故,就是一个活生生的案例。
这也是为什么 Hassabis 说“技术狂奔的同时,底线不能丢”。但“底线”不能只写在 prompt 里,得落到硬约束上。
数据库层面,OceanBase 和 seekdb 在设计上恰好有几道防线:
- 数据分支(Branch / Fork):像 Git 一样。AI Agent 在 Fork 出来的分支上随便实验,主库纹丝不动。改好了 MERGE 回去,改砸了直接扔掉。Fork 基于 LSM-Tree 的写时复制,毫秒级完成,不复制全量数据。
- 回收站 + 闪回:被 DROP 的表暂存回收站,
FLASHBACK一键捞回。闪回查询可以看任意历史时间点的数据快照——AI 在 9 秒前干了什么,9 秒后就能精确回滚。(这个是小编当年通过古法编程开发出的功能,欢迎各位试用和反馈~) - 主备物理隔离:备份和主库跑在独立的存储集群上,不在同一个“爆炸半径”里。

说到底,Hassabis 的焦虑和 PocketOS 的事故,都指向同一个结论:与其指望 Agent 不犯错,不如假定它一定会犯错。然后在数据库层面,把所有破坏性操作的口子焊死。
四、AI 领域,还在等它的“爱因斯坦”
访谈快结束时,Hassabis 说了一段让人很难忘的话。他提到了一个他称为 “爱因斯坦测试” 的标准:
“给一个 AI 系统截止到 1911 年的所有知识,看它能不能像爱因斯坦在 1915 年那样,自己推导出广义相对论。很明显,今天的系统做不到这一点。”
他进一步解释:现在最强的 AI 系统能做到在既有框架内解决问题——解一道物理题,甚至是奥赛级别的。但 AGI 需要的是发明框架本身——不是答好一道物理题,而是创造一套全新的物理理论。
“能发明围棋吗?给系统一段高层描述:‘一个五分钟能学会规则、但穷尽一生也难以精通的游戏,美学上很优雅,一个下午能下完一盘’——然后系统返回给你围棋。今天的系统做不到。”
AlphaGo 能在棋盘上下出惊世骇俗的第 37 手,但它发明不了围棋。
这大概就是当前 AI 的处境总结:能在考试里拿满分,但还没学会发明考试。Hassabis 说,这个领域还在等一次“爱因斯坦式突破”——一个底层理论革新,一次性解决推理、记忆、进化学习的难题。
在那个时刻到来之前,我们能做的是:把记忆造好,把端侧铺好,把安全兜好。 让 AI 在通往 AGI 的路上,少摔几个跟头。
而要做到这三件事,光靠模型层不够。基础设施层,也必须跟着一起进化。
本文观点素材主要来自 Demis Hassabis 与 YC CEO Garry Tan 的 How to Build the Future 播客访谈视频(2026 年 4 月 29 日),以及访谈文字稿。