大模型VS小模型:论国产数据库运维AI Agent的正确打开方式
作者:孙鹏,大衍(北京)科技有限公司研发工程师
暴论:通用满血大模型”不适合”用于赋能国产数据库智能诊断运维
在传统数据库运维领域,长期面临三大核心挑战:
- 数据量的迅猛增长:随着现代应用程序的数据量迅速增加,数据库实例的数量也随之增多,监控指标变得更为复杂。面对海量的数据库实例,人工进行运维诊断变得越发吃力。
- 过度依赖经验:数据库类型的多样化导致专家的经验难以迅速普及与传承,在故障定位上平均需要耗费数十分钟的时间。
- 传统技术的局限性:基于规则(RBO)或成本(CBO)的静态优化器难以适应复杂的查询场景变化,同时处理非结构化数据的能力也较为薄弱。
随着AI大模型的应用,这些问题得到了全新的解决方案。AI大模型通过其动态优化能力,突破了传统静态优化器的限制,能够实时生成高效的执行计划;借助自然语言交互能力,大大降低了复杂查询的技术门槛;并且具备多模态分析能力,可以统一处理如日志、性能指标等异构数据。这些进步促使数据库运维模式实现了质的飞跃,从以往的被动响应转向主动防御,由依赖经验转变为依靠智能决策。
但是在使用大模型赋能数据库运维的过程中,却发现两个问题:
1. 通用大模型对国产数据库的认知不足,生产环境难利用。
在使用大模型对传统数据库(如Oracle、MySQL)进行问题诊断时,通常能够取得较好的效果。然而,当将同样的技术应用于国产数据库时,诊断结果往往不尽如人意。这主要源于当前通用大模型在训练过程中所接触的国产数据库相关知识相对匮乏。
此外,出于企业数据安全与合规性的考虑,生产环境中的运维数据无法上传至外部网络,也就无法为”满血版”大模型提供实时参考。
2. 数据库运维数据的可观测性、准确性不足。
即便使用的是功能完备的”满血版”大模型,其产生幻觉的概率依然较高。例如,在分析数据库负载问题时,如果仅提供总数据量等粗粒度信息,大模型往往难以准确还原特定时间段内的负载变化趋势。
以小模型取代满血大模型的可行性探索
许多企业在落地AI能力时面临现实挑战:受限于高端显卡难以获取或高昂的算力成本,无法在内网部署功能完整的”满血版”大模型。出于成本和部署条件的考量,企业往往只能选择更为经济的私有化小模型方案。
那么,我们是否可以在资源受限的生产环境中,部署一个成本更低的小模型,却使其具备接近大模型的能力呢?
这一设想面临两个关键挑战:
- 一是如何使小模型复现大模型强大的推理与泛化能力;
- 二是如何弥补大模型在国产数据库知识覆盖不足的问题。
回溯到2020年发表的重要论文《Language Models are Few-Shot Learners》,文中提出了一种”上下文学习”(in-context learning)机制,表明大模型可以通过输入上下文信息,在不更新参数的前提下实现在线学习。
受此启发,在使用小模型进行具体问题分析时,尝试将该问题相关的背景知识、指标数据、实时运行状态以及精心设计的提示词(prompt)一并输入模型,借助上下文增强其推理能力。经过多轮测试验证,小模型的回答准确率已接近”满血版”大模型的表现。
(一)高质量数据是小模型落地的核心基础
将小模型应用于数据库智能运维,通常需要满足三个关键前提:
第一,具备强大的系统可观测能力。 包括提供丰富且准确的运行指标与统计信息,如系统性能指标、等待事件分析、完整的日志记录与TRACE数据,以及宏观层面的AWR报告与微观层面的ASH信息。
第二,沉淀高质量的运维知识体系。 该体系涵盖两个维度:
- 运维理论知识主要来源于权威的原厂文档、第三方技术书籍等结构化知识资源;
- 运维实践经验则包括专家经验总结、用户故障案例库等非结构化或半结构化经验资产。
相比理论知识,大模型更容易理解和吸收来自实际场景的运维经验。因此,在小模型训练和推理过程中,注入真实业务场景下的经验数据尤为重要。
第三,依托强大的推理模型能力。 当高质量的数据与强大的推理能力相结合时,即使是在资源受限的私有化部署环境下,小模型也能够实现接近大模型的准确性和稳定性。
(二)智能化指标加工,为数据库构建强大的可观测能力
通过智能化指标加工可以为数据库构建强大的可观测能力。首先从数据库、中间件等各种IT运维对象中采集数据,比如运行数据、日志数据,以及从数据中台获取加工数据等,从而得到指标集。其次基于原始数值进行二次加工,得到时间段的增量差值、平均值、单次平均值等统计分析值。然后在统计分析值的基础上再进行加工,可以得到平均值、稳定性、趋势评估值、风险评估值等相关数值。
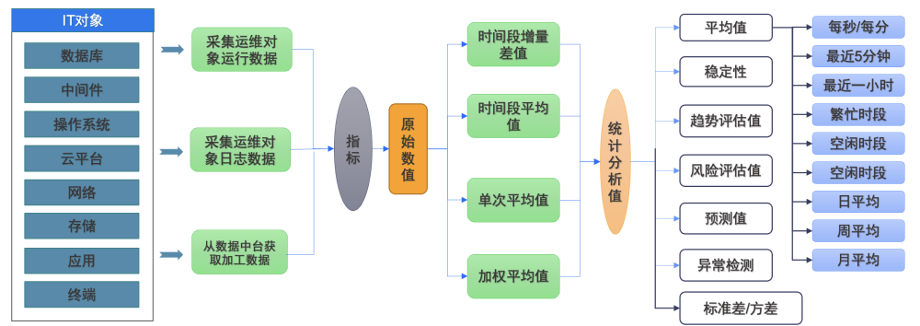
与此同时,还需构建知识图谱。因为运维知识图谱建设是数字化能力的基础,通过知识梳理形成了初始化的运维知识图谱,并根据实际应用案例不断提炼和丰富知识图谱,使其分析能力不断提升。
(三)数据库智能运维诊断架构设计
数据库智能诊断分析流程主要包括以下关键步骤:
- 数据采集与加工 — 从OceanBase数据库中采集并加工关键性能指标,构建全面、细粒度的可观测能力
- 数据存储 — 将采集和加工后的指标数据统一存储至数据仓库
- 故障模型触发与分析 — 当某一故障模型被触发时,系统将自动启动异常检测智能体(AI Agent):
- 从知识图谱中提取与该故障模型相关的背景知识
- 同步从数据仓库中获取当前数据库的实时运行指标
- 结合预设提示词模板,将上述信息整合后输入大模型
- 大模型进一步从向量数据库中检索相关案例、专家经验及场景化信息,最终输出一份逻辑清晰、内容准确的诊断分析报告
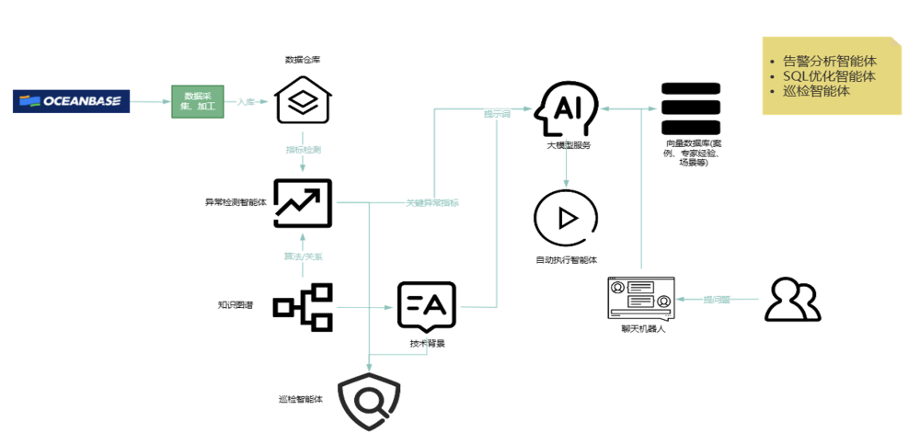
目前,已成功构建并部署了三类智能体(AI Agent):
一是告警分析智能体:
- 当数据库产生告警时,该智能体可自动调用大模型进行深度分析
- 分析完成后生成结构化的诊断报告,并通过邮件等方式推送给相关人员
二是SQL优化智能体:
- 可自动识别数据库中的Top SQL(如高频执行或资源消耗高的语句)
- 借助小模型对这些SQL进行智能优化,生成优化建议及诊断报告
三是巡检智能体:
- 用户可根据需要设定特定时间段,由巡检智能体对该时段内的数据库健康状态进行全面检查
- 智能体根据巡检结果生成详尽的健康报告
以下面两个场景为例,说明上述智能体的工作原理及效果:
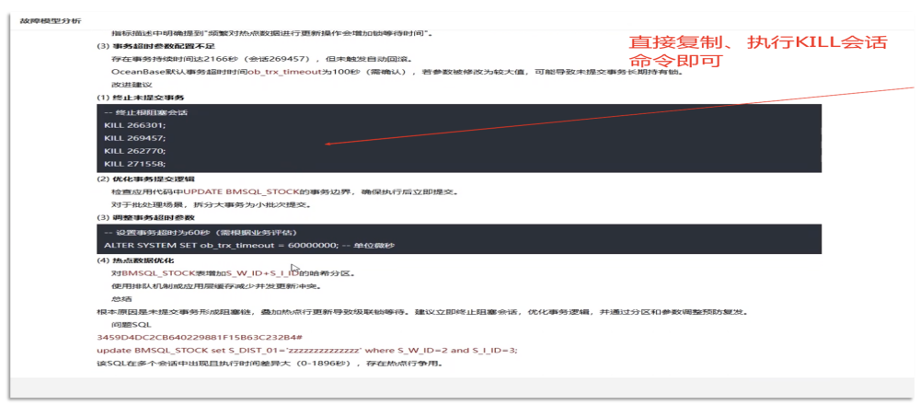
1. 小模型分析锁冲突场景。
首先需要把OceanBase的锁冲突的阻塞数据和被阻塞数据的背景知识一起发给小模型,小模型就可以通过阻塞数据和背景知识找到每个根阻塞,提示终止相关会话以解决阻塞场景,同时给出原因分析,并提出诊断建议。
2. 小模型SQL优化。
在小模型进行SQL性能优化的过程中,首先会深入分析SQL的执行计划,识别其中最主要的性能瓶颈,并结合具体执行路径给出判断依据。
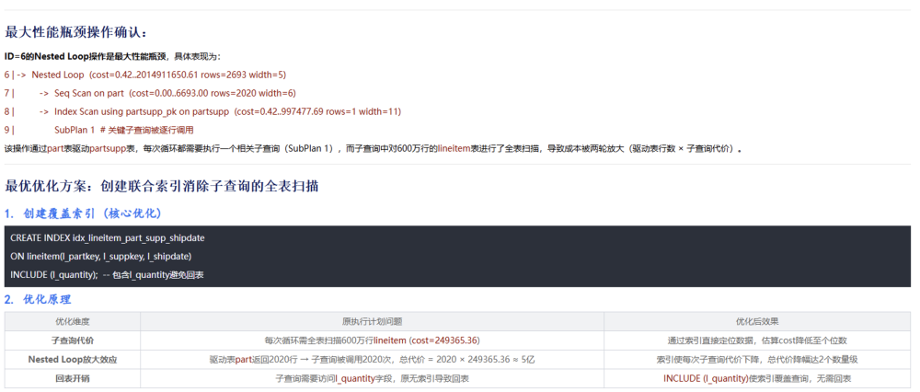
例如,在执行计划中若发现某张分区表作为驱动表,使用了Nested Loop连接方式,且该连接过程包含两个层级的循环,这意味着part表中的每一条记录都会触发一次对被驱动表的完整扫描或查找操作,造成数据访问次数成倍增长。优化建议包括:将Nested Loop改为Hash Join或Merge Join;考虑对被驱动表的相关字段建立索引,或调整分区策略以减少扫描范围。
实践表明:AI Agent诊断推理水平已具备实战能力
为了验证AI Agent的诊断推理能力,选择了实验室环境中的四个典型故障模型进行了测试,包括Oracle数据库的日志同步延时异常和热块冲突问题,以及OceanBase数据库的阻塞会话数过多和活跃会话数过多问题。
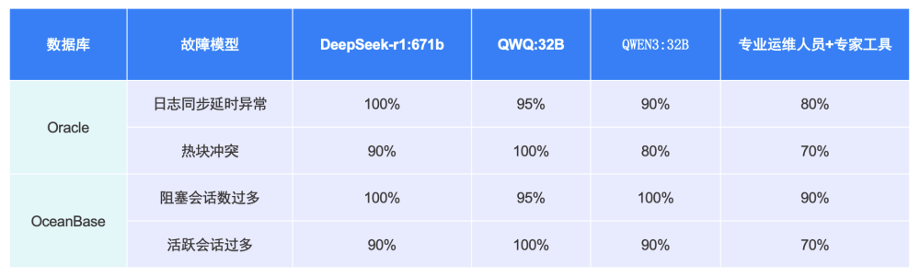
测试结果令人鼓舞:无论是使用满血大模型还是私有化部署的小模型,其分析准确率均达到了90%以上,这一成绩超越了当前内部专业运维人员结合专家工具所能达到的准确率水平。
在实验室环境中,不管使用满血大模型还是用私有化部署的小模型分析,包括分析SQL、优化SQL、分析告警,耗时一般在3~5分钟之内(通义千问Qwen 3系列的模型分析速度在两分钟左右)。而传统的专家分析,经过收集指标数据、根据诊断路径分析原因,时间已经消耗3小时左右,甚至可能达到半天或一天。相较之下,基于AI的智能诊断效率远远高于运维专家,提升了50倍以上。
本文内容来源于OceanBase “Data✖️AI”黑客松大赛,欢迎查看更多精彩作品:https://open.oceanbase.com/ai-hackathon