《The Cascades Framework for Query Optimization》
The Cascades Framework for Query Optimization
总结
在不损失Exodus 和volcano的模块性, 扩展性和动态编程, prototype的memorization 的情况下,解决volocao的一些缺点:
- rules
- rule as objects
- rule-specific 指导, 允许一组规则。 探索(生成各种等价逻辑expression)和优化(映射逻辑计划到物理计划)都可以有个数据库设计者进行控制和规范。
- 有一些规则用于, 映射输入pattern 到DBI-supplied 函数
- 有一些rule 来插入 enforcer 或 glu 算子
- 带替代品的规则 构成一个复杂表达式
- 规则用promise 进行排序(规则按权重排序)
- 有一些schema-specific 的规则用于物化视图
- 用rules或function来控制operator的参数。
- function rules和树算子可以通过DBI(database implementor)的supplied function 直接控制复杂树的item 操作。
- Framework
- 搜索的方式, 或者采用rule来指导, 或者穷举方式
- 有一些用于schema-specific 和query-specific 规则的工具
- 有一些抽象接口类, 他们用于定义DBI-优化器 接口 和DBI-定义 的子类层次结构。 干净的接口和实现 充分利用C++ 的抽象机制
- 算子既可以是逻辑的, 又可以是物理的, 如谓词
- pattern 是匹配一个子树
- 优化task 类似data structure
- 对逻辑表达式 进行等价增量枚举, 对评估逻辑属性进行增量改进
- 扩展性tracing 支持
- 一组工具来 并行search, 部分排序好的cost计算 和动态计划
优化算法和task
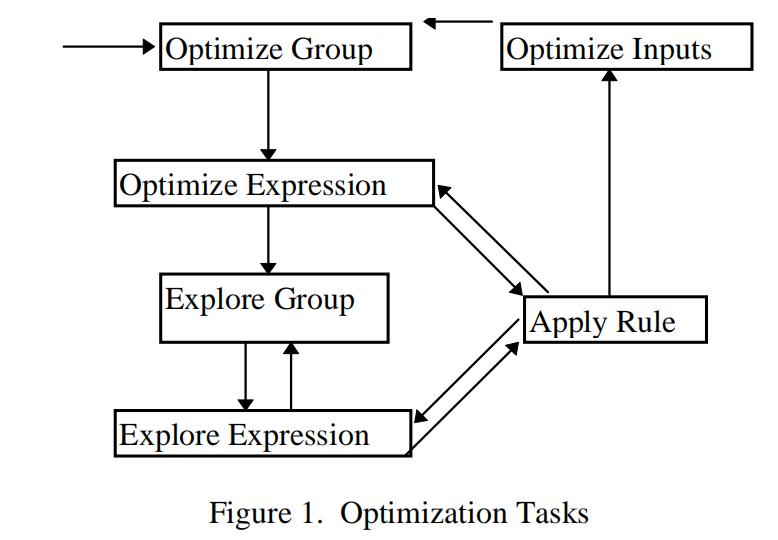
- 首先copy 原始query 到内部memo 数据结构中
- 启动一个task 优化 原始query 树root node
- 依次迭代一层一层优化子树。
将优化算法切分为几个task, task 是一个对象, 有一个执行函数。 task 相对过程调用来说扩展性更好。
- 可以用一个大的task 存放很多子task
- task实现为类似堆栈, 后入先出。
- task 很容易根据启发式规则来进行一些排序。
- 可以用topology来展示task 的依赖关系和先后顺序, 也可以方便进行并行search。
- 目前调度task 类似LIFO stack, 调度一个task 类似调用一个函数, task 完成是在子task 完成后。
优化目标: 对一个group或表达式 用要求的和排除的物理属性下进行优化, 优化的代价不超过限定值。 要么成功输出一个plan, 要么失败。 找到一个最佳plan, 对这个group 内所有表达式都适用并且将规则应用到每个表达式上, 优化一个表达式通常从单表达式开始。
在volcano search 逻辑中, 第一部分是应用转换规则做各种逻辑变化, 第二阶段执行实现规则, 并选取最佳plan
在cascade 中, 首先检查 这个优化目标之前有没有执行过, 如果执行,则返回之前search的结果, 这个动态编程和memorization 很重要的一个步骤。 另外抛弃了volcano 的2阶段优化。 他根据需要执行transformation rule, 根据一个给定的pattern 生成这个group的所有成员, 这个pattern 是task 定义的部分, 是规则的before-pattern或anticedent-pattern (前置pattern)的子树。同样可以避免一些重复工作, 在进行pattern 匹配时,可以检查这个group或表达式是不是之前就用过这个pattern, 如果用过,就结束这个task, 可以直接使用之前的search 结果。 有一个组件“pattern memory”来管理用过的pattern。 在volcano, 第一阶段使用了穷举策略, 这个产生的等价表达式太多了。 在cascade, 如果有一些guidance, 则可以做一些搜索路径的裁剪, 允许对同一个group使用不同的pattern进行多次操作。 在memo 中, 有一个bit map 来表示哪些transformation rule 已经被使用了(从而可以避免被再次使用)。 最差的情况下, casecade 如果没有任何guidance, 也会和volcano 的搜索效率一样。
如果guidance 不正确,就会导致不正确的搜索空间裁剪, 有2种技术用于guidance, 第一: 检查所有的规则(尤其是top 算子的规则的前置pattern和后置pattern), 我们找出在一个单独规则使用中,那些算子可以影视为其他算子。 通过考虑闭包的传递性,排除一些规则。 第二 由DBI 实现一些机制来指导。
因为算子既可能是逻辑的又可能是物理的, 同样规则也是既可能是逻辑的又可能是物理的。
执行应用规则非常复杂, 分4个步骤,
- 这个规则pattern的binding 是派生的,并且是一个接一个迭代的
- 对每一个binding, 用规则来创建一个新的表达式, 对function rule, 对每一个binding 可能有多个新的表达式
- 集成新表达式到memo 结构中, 这里可以去重表达式。
- 对每个表达式用同样的目标和当前规则应用的context 进行explore 或优化。
因每个规则的前置pattern (antecedent)可能很复杂, cascade 使用一个复杂的过程来确定每个可能的binding。这个过程是递归的,对pattern的每个node 进行递归调用。 这个过程使用迭代器来实现的, 每一次调用都产生下一次可行的binding。 迭代的状态捕获在pattern内每个节点的BINDING 类的实例中。 一旦发现一个binding, 转化为有EXPR node 组成的树。 这一步copy的动作需要做一些努力,但他将优化器和这颗树要用的DBI method 分开。 对每个binding, 调用rule的condition function, binding就会转化为规则的结果(after-pattern, substitute)。 有一些规则,binding 非常简单并且完全由优化器来做。 对于一些规则来说, DBI 确定一个函数来创建substitue, 会重复调用这个函数尽可能创建多的substitute。 这样这个函数就是一个迭代器,被连续调用创建多个substitute。 因此, 从一个memo中提取binding 是需要评估的。
每个substitute(binding后续)表达式会集成到memo中, 这个过程包含search和去重。 从substitue的叶子节点(query/plan tree/表示rewriter operation 范围的operator 的叶子节点)开始递归, 从低向上至root。
最后, 如果substitute的root 是一个新的表达式, 随后的task就会启动, 如果这个substitute 是由exploration 的部分创建的, 就会创建一个task来expolre 这个相同pattern的substitute。 如果这个substitute 是优化的部分创建的, 随后启动的task就会依赖是一个转化rule还是一个实现rule,例如, 这个substitute 的root 算子是一个逻辑算子还是物理算子, 一个rule 可以同时是transformation rule和implementation rule, 这种情况下, 2种随后的task都会被创建。 对于一个逻辑root 算子, 一个optimization task 会被创建用来优化substitute。 对于一个物理root 算子, 会调度一个task来优化算子的input并计算处理代价。 优化输入(optimize inputs) task是不同于其他task。 其他task 调度他随后的task然后就小时, 这种task会激活多次。 也就是, 他调度随后的task, 然后等待随后task结束, 继续并调度下一个随后task等等。 随后的task是相同类型, 他们优化input group 。 cascade search engine 保证仅仅那些subtree和有兴趣的属性会被优化, 优化input task 获得派生的最好执行cost, 然后派生一个新的cost limit 给下一个优化input, 因此pruning 是尽可能的多。
数据抽象和用户接口
目标:
- DBI 和优化器 之间的接口 会专注在minimal, 功能性和干净的抽象
- 实现一个优化器原型尽可能高效的使用接口
- 在exodus和volcano的教训的基础上 设计和实现一个高效search 策略, 结合学术和工业界查询优化的研究。
专注在: - support function 干净的抽象, 保证优化器生成器能根据specification 创建他们
- rule机制允许DBI 选择rule或function 来控制算子参数
- 更准确和完整接口specification。
在cascade 优化器和DBI 之间的接口的类 被设计为子类的root。 这些类的object 会关联上其他的类。 例如, 创建一个guidance 的结构会关联到一个rule 对象。 这个rule 对象是接口类RULE的子类。 这个创建的guidance 是接口类GUIDANCE的子类。 优化器仅仅依赖接口定义的函数。 DBI 在定义子类时,可以添加额外的函数。
算子和参数
cascade 优化器接口的OP-ARG类包括逻辑和物理算子。 对每个算子, “is-logical” 现实算子是否是逻辑算子, “is-physical” 显示是否是物理算子。 但有可能一个算子既不是逻辑算子也不是物理算子。 当优化器支持一些扩展语法时,这些算子就发挥作用, 想starburst 支持“non-terminal”。 DBI 可以通过子类来获得严格的逻辑算子和物理算子的隔离。
算子的定义包括他们的参数。 在exodus和volcano中,没有机制来做“argument transfer”。 有2个关键工具用于帮助建模谓词(在exodus和volcano框架中 建模为算子参数)为逻辑和物理关系代数的主要算子。 首先一个算子既可以是逻辑的,又可以是物理的, 它天然是一个single-record的谓词,并成为sargable(Search Argumentable)in system R。 第二, 指定的谓词转换例如可以在join中push 的复杂谓词组件抽取出来的谓词, 它可以在DBI function内更容易并高效实现而不是由search engine解释的一个rule, 也可以简单实现为调用DBI-supplied的rule 来map 一个表达式为一个或多个substitute 表达式(后pattern 表达式)。 exodus和volcano 经常被吐槽谓词控制非常麻烦, cascade 可以提供很多方便工具。
优化器的设计不包括逻辑和物理关系代数优化。 因此没有query或plan的算子包括到优化器中。 为了使用rule, 有2个特殊的算子, “LEAF-OP”和“TREE-OP”。 叶子算子在任何规则中都是作为叶子被使用, 在matching过程中,它可以匹配任何子树。 在应用一个规则, 会从匹配这个rule的pattern的search memory中提取一个表达式, 如果这个rule的pattern 有叶子, 这个提取的表达式也有叶子算子, 这个叶子算子参考search memory中等价类。 树算子类似叶子算子除了这个提取的表达式包括一个完整的表达式, 和它的大小和复杂度无关, 会down到逻辑关系代数的叶子算子。 这个算子在连接function rule时,特别有用。
除了提供“is-physical”/“is-logical” 函数, 所有算子必须提供“OPT-CUTOFF” 函数。 在一个优化任务中,赋予一组move,这个函数决定有多少move 会被尝试, 尤其是哪些最可能被使用的。 默认, 所有可能的move 都会被尝试, 因为exhaustive的search 保证会找到优化plan。 有一小组函数用于那些被申明为逻辑的算子。 对于pattern 匹配和查找重复表达式, 会要求matching和hashing的函数。 用于查找并提高逻辑属性的函数用于决定一原始组的属性和当可选的表达式被找到后, 改进它。 最后, 对于exploration task, 有可能调用一个算子来初始化pattern memory 并决定在exploration过程中,尝试多少moves。
同样的, 有一些函数是给物理算子的。 明显的, 有个函数来决定算子的输出属性(展现的属性)。 更进一步, 有3个函数用于计算和检查cost。 第一个函数计算一个算法的local cost,不考虑输入的cost。 第二个函数 组合这个cost(应该是上一步的cost), 算法输入的物理属性到完整subplan的cost。 第三个函数verify, cost 没有超标, 在优化一个算法的2个输入下, 并计算一个新的cost limit用于优化下一个输入。 最后, 就像最后一个函数那样, 它map 一个表达式的cost limit 到他其中一个输入的cost limit, 同样有一个函数, map 一个表达式的目标到 其中他一个输入的优化目标, 例如, 一个cost limit 和要求的和排除的 物理属性。
逻辑和物理属性, cost
期待的执行cost的接口, COST 类, 非常简单, cost的实例 由 和其他类(如算子)关联的函数创建并返回。 除了destruction和printing, cost的唯一函数就是比较函数。 类似, 封装逻辑属性的唯一函数就是类 SYNTH-LOG-PROP, 它是一个hash 函数, 他可以更快检索重复的表达式即使这个函数还没有应用物理表达式。 封装物理属性的类是 SYNTH-PHYS-PROP, 却没有函数。 要求的物理属性类是REQD-PHYS-PROP, 只有一个函数,并且它决定一个合成的物理属性实例是否cover 这个要求的物理属性。如果一组属性比另外一组属性更明确例如 一个在A,B,C 上排序, 而另外一个只要求sort order在A,B。 这个比较函数就会返回MORE。 默认的返回是undefined。
表达式树
另外一个抽象数据类型是部分接口 – EXPR 类。 这个类的实例是树上的一个节点, 由一个算子和指向input node的指针组成。任何一个表达式节点的子树数量等于这个node 算子的参数数量。一个表达式节点的函数,除了构造函数,析构函数,打印函数之外, 包括提取算子的函数或者有一个输入是匹配函数的函数, 递归遍历2个表达式树并调用每个节点算子的匹配函数。
搜索指导规则
除了pattern, cost limit, 要求和排除的物理属性, 启发式规则可以控制规则应用, 启发式规则是GUIDANCE 类的实例来表示。 他用于转化优化启发式规则 从一个rule 应用到另外一个。 注意当执行一个plan时,会产生 正在操作的表达式的cost和属性和 中间结果的cost和属性; guidance 类会捕获搜索过程的只是和未来搜索用的启发式规则, 例如一些如交换率的规则就只被使用一次, 被叫做“once-guidance”和“once-rule”。
有一些研究者将优化规则分成模块, 一次只调用一个模块, 如MITCHELL。 GUIDANCE 可以很容易使用这个设计, 一个guidance结构可以显示哪个模块会被调用, 每个规则检查在它promise或condition 函数中的标识, 然后当为一个新建表达式和它input创建guidance结构时,会创建合适的标识。
Pattern memory
除了search guidance之外, pattern memory会限制探索。 pattern memory是防止一个group的无用探索,如2个相同patterm。 每个group 都会有一个pattern memory。 在针对一个pattern探索一个group前, 允许增加这个pattern到pattern memory并决定探索是否应该使用。 在大部分简单search中, 任何pattern的exploration都是穷举transformation 规则应用, pattern memory 需要包含一个boolean, 表示这个group是否之前被exlored, 更复杂的pattern memory 会store 每个pattern。
明显, pattern memory会和expoloration promise 函数交互。 对于大部分简单的promise 函数(使用穷举),上面简单的pattern memory是足够的。 由DBI 来设计pattern memory和promise 函数, 使用要被优化的关系代数。
除了检查一个pattern是否已经存在与pattern memory中, pattern memory最复杂的函数是merge 2个pattern mmory。 当发现2组等价的表达式(例如一个转化后的表达式在不同group中出现)时, 会执行这个函数。
rules
除了算子, 最重要的类就是rule。 注意rule是对象, 可以在run-time 创建并打印。 其他rule基础的优化器,如volcano 有逻辑算子和物理算子一样有transformation rule和implementation rule。 cascade 不区分这2中规则, 除了在新建的表达式中调用is-logical和is-physical 函数。 所有的rule 都是类RULE的实例, 他提供rule name, 一个祖先(before-pattern)和一个结果(substitute, after-pattern)。 pattern和substitute 都是用表达式树来表示。
任何时候 发现一个pattern或由exploration task 创建一个pattern, 在search memory中都会包括这个substitute 表达式。 rule的pattern和substitute 都可以是任意复杂。在volcano中, 一个implementation的rule的substitute 不能包含超过一个implementation 算子。 在cascade中,去掉了这个限制。 但还有一个限制就是substitute的top 算子必须是逻辑算子。 例如, 可以tranform 一个逻辑join 算子为物理的nested loop 算子(这个算子带一个在它自己input上的selection), 因此, 可以将这个谓词从join上下推到input tree上。
对于一些复杂rule, 可以支持2中类型的condition function。 他们不仅考虑rule并且当前优化目标(cost limit, 要求和排除的物理属性)。在exploration 开始, promise 函数通知优化器 这个规则有多有用。 optimzation task 有一个promise 函数, expoloration task 也有一个。对于unguided 穷举search, 所有的promise 函数都会返回1.0. 0或更少表示优化器不会用他。 如果要求一个明确的物理属性, 默认promise 函数返回0, 如果substitute是一个实现算法,返回2. 其他就返回1. 如果关联这个算子的cutoff 函数选择穷举search, promise function的返回值不会改变最终plan的质量, 尽管他会影响发现plan的顺序, pruning的有效性,以及耗费的优化时间。
因为promise 函数是在exploration subgroup之前被调用的,例如从search memory中explored和提取出对应一个规则的完整表达式树, 在exploration 执行完和可以获得一组完整的算子(对应rule内pattern)之后 condition 函数坚持这个规则是否可用。 promise 函数返回一个表达promise 级别的值, condition 返回一个boolean表示这个规则是否可用。
除了promise和condition 函数, rule 有一些函数,除了构造函数,析构函数,打印函数外,还有提取pattern的函数, substitue,rule name, 和他的参数个数(pattern的叶子节点个数)。 “rule-type”函数展示一个规则是一个简单规则还是一个function fule。 top-match 函数决定search memory的一个算子是否match rule pattern的top 算子, 这个函数是built-in 检查, 在promise 函数调用前。 opt-cases 函数现实一个物理表达式被不同物理属性优化的次数。 有一些特殊的case, 它会返回1, 例如在merge-join 算法中, 有2个clause (R.a=s.a and r.b=s.b)会被优化为2个sort orders(“A,B” 和“B,A”)。 当优化一个新创建的表达式和他的输入时, 新建的guidance结构会用到剩下的函数。各有2个函数用于优化(optimization)和用于探索(exploration), 各有2个函数用于新表达式和它的输入。 “opt-guidance”,
“expl-guidance”, “input-opt-guidance”, “input-expl-guidance”. 默认他们读返回null。
如果一个rule的substitute 仅仅包含一个叶子算子, 这个规则是一个reduction 规则。 如果使用reduction 规则, search memory的2个group会做merge。 如果一个规则的pattern 仅仅包含一个叶子算子, 这个规则是一个一直可以被使用的膨胀规则。 cascade 优化器以来DBI 来设计合适的promise和condition 函数来避免无用的transformation。 有一个重要的类, 插入可以enforce或保证期望的物理属性的物理算子, 这个规则叫enforcer 规则。 例如sort-merge的输入必须是sorted。 一个enforcer 规则插入sort 算子, 这个规则的promise和condition function 允许这个要求sort order的规则, sort 算子的“input-reqd-prop”函数必须设置排他属性以避免 产生sort oder和input sort一样的的plan的考虑。 An enforcer rule may insert a sort operation, the rule’s promise and condition functions must permit this rule only of sort order is required, and the sort operator’s ”input-reqd-prop” method must set excluded properties to avoid consideration of plans that produce their output in the desired sort order as input to the sort operator.
在一些情况下, 更容易实现一个函数直接转换一个表达式,比设计并控制一个rule 来做这个转换。 例如, 切分复杂join 谓词为clause, 这些clause 用于left, right,和2个input 是一个确定性的过程, 这个切分用单个函数最好实现。cascade 支持rule的第二个类 FUNCTION-RULE。 一旦从对应rule pattern提取出来的表达式, 会重复调用一个迭代器函数来创建这个表达式的substitute。 这个提取的表达式可以任意复杂度, 只要在这个rule pattern中用到这个树算子。 树算子和function fule 允许DBI 实现任何转换。 在极端场景下, 一组function rule执行所有的转换, 有可能违背cascade的设计初衷。