《数据库实现》-- 第六章 故障恢复
第六章, 故障恢复
概述
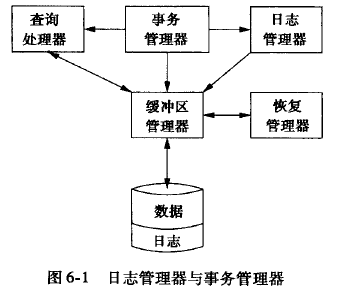
故障恢复, 依赖很多组件一起协同完成,
- 日志管理器, 存储日志
- 事物管理器, 保障事物的一致性
- 恢复管理器, 备份和恢复的协调者
事物原语操作
地址空间
- 物理磁盘块空间
- 缓冲区的内存地址
- 事物的局部地址空间
一种描述数据在地址空间移动的操作:
- input(x), 将磁盘块含有数据库元素 x load 到内存, 由缓冲区管理器触发
- read(x), 将数据库元素x 拷贝到事物的局部变量t, (如果不在内存,则先执行input(x), 然后赋值给事物局部变量t)。 事物管理器触发
- write(x), 将事物局部变量写到内存x。 事物管理器触发。
- output(x), 刷到磁盘。 缓冲区或日志管理器触发。
因为事物的原子性, 有一些设计上的要求
- 数据库元素大小不超过一个块 (无论是在内存中操作或磁盘io操作)
例子:
需求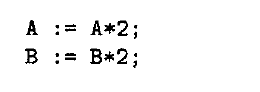
则事务的原语是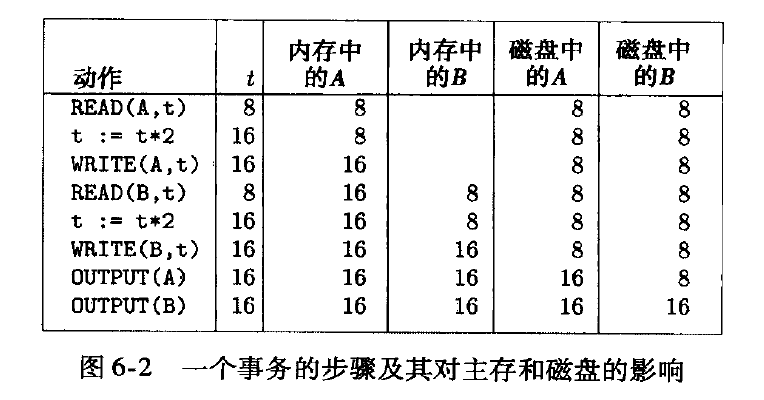
如果不再缓冲区, 还需要增加input 指令。
- 在output 之前,发生故障, 都能保持数据库一致性
- 在output 之后, 发生故障,也能保持数据库一致性
- 在output过程中,发生故障, 会破坏一致性。
undo 日志
undo 日志, 撤销事务在系统崩溃前还没有完成的动作来修复数据库状态。
日志通常是一个三元组<T, X, V>, 事务改变了数据库元素x, x原来的值是v。
- 日志是反映write 动作,不反映output动作
- 日志记录是原始值, 不记录新值。
- 如果事务t 改变了数据库元素x, 日志必须在数据刷到磁盘前,日志写入磁盘
- 如果事务提交, commit日志必须在所有元素写到磁盘之后写到磁盘,而且要快。
新的逻辑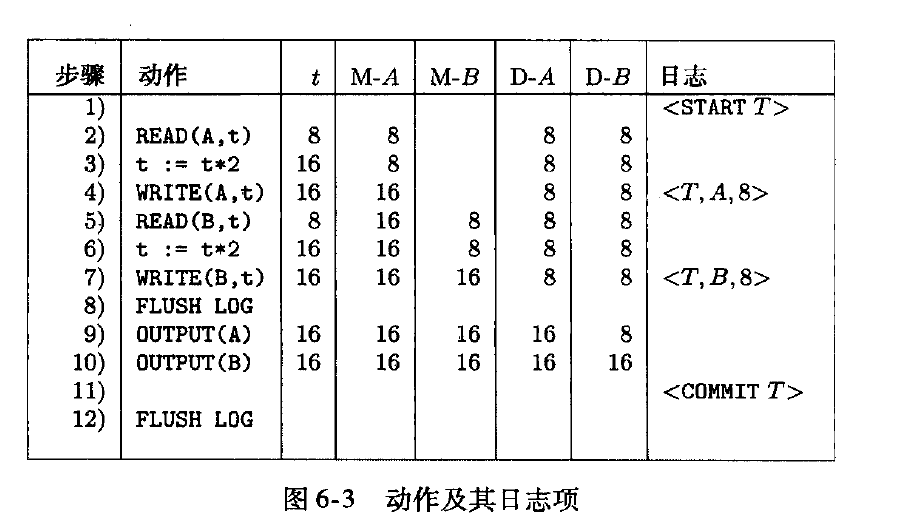
undo 日志恢复
恢复管理器,
- 事务分已提交和未提交日志。
- 恢复时, 按顺序从尾部向头部扫描
- 如果发现commit 日志, 则事务已经刷到磁盘,不需要额外恢复操作
- 当发现abort 日志记录或发现start,但没有commit日志时, 这个事务必须被回滚。
- 用日志内部的原始值更新到磁盘, 强制刷到原始值
- 如果没有abort 日志, 写入abort 日志
- 恢复过程中的二次崩溃, undo的设计时幂等的,可重入的。
checkpoint
定期做checkpoint, 清理老的日志, 避免恢复到一个比较过时的状态。
静态checkpoint
- 停止新事务
- 等待当前活跃的事务, 提交commit或abort
- 刷日志到磁盘
- 写入日志记录ckpt
- 重新接收事务
动态checkpoint
静态checkpoint 需要停止新事务, 这个过程对用户非常不友好。
- 写入 日志记录< start ckpt(t1, t2, t3, …. tk)> 其中t是所有活跃的事务
- 等待t1, t2, t3, 。。。 tk 提交或中止, 但允许其他事务进行
- 当t1, t2, t3, 。。。。 tk 完成后, 写入
当写入end ckpt 后,可以将上一个start ckpt 之前的记录全部清楚掉
lsn
日志经常是使用旧的日志文件, 会循环使用旧的数据库, 这种情况下, 日志得有一个只增不减的序列号。 
如果发现下一条记录的lsn 比当前记录的lsn还要小, 说明已经到结尾了。
日志通常是一个多层次结构, 顶层文件记录日志文件的构成, 顶层文件的最后一条, 表明可以在什么地方找到最后一条记录。
先不考虑循环文件, 如何恢复, 有了checkpoint, 恢复的速度可以大大加快, 恢复可以提交停止。
- 还是按照之前的逻辑进行恢复
- 如果先遇到
, 向前扫描, 当遇到start ckpt 就停止, start ckpt 之前的日志没有必要再恢复了 - 如果先遇到start ckpt, 记录这个ckpoint 所涉及的事务列表, 向前扫描, 找到最早出现这些事务的日志的地方, 之前的事务日志就不用再扫描了。
redo 日志
redo 日志忽略未完成的事务, 重复已经提交事务所做的改变。
redo 日志是记录commit后的值
<t, x, v>, 事务t 为数据库元素x 写入新值v
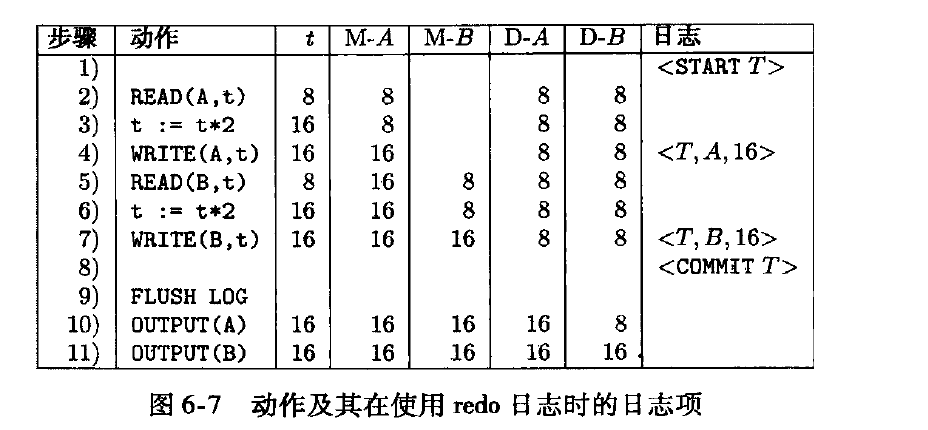
整个顺序是不同
- 写到内存中redo日志
- 写commit日志
- 在output磁盘前,刷redo log
redo log 的恢复
从日志首部向下扫描
- 如果t是未提交的事务, do nothing
- 如果t是已经提交的事务, 写入v
- 对没有完成的事务, 写入一个
到日志
redo 的checkpoint
在真实环境中, 数据output 到磁盘会比较慢, 但redo 是按时刷到磁盘。
写checkpoint过程
带检查点redo恢复
- 只找最后一个start ckpt提到的事务即可
- 如果是end ckpt,则记录这个ckpt 对应的事务列表, 对应start ckpt 前提交的事务已经刷到磁盘, 不需要恢复
- 对ckpt 列表的事务 进行恢复
undo/redo 一体日志
日志格式<T, X, v, w>, v 为修改前的值, 新值为w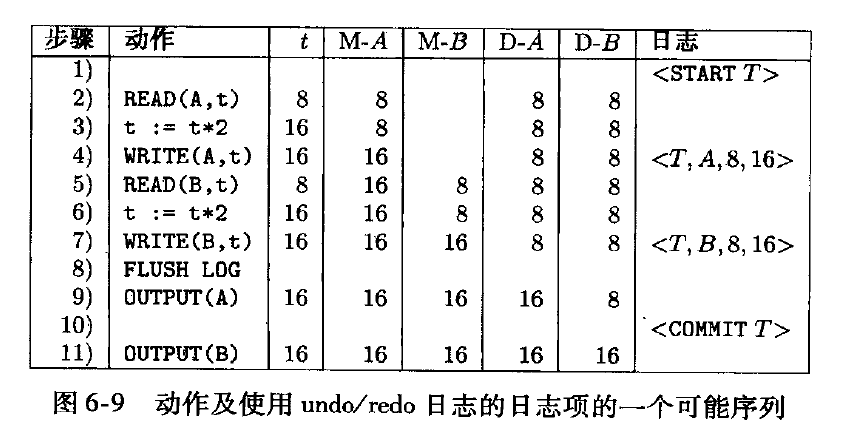
MySQL innodb undo 和redo 协同工作
假设有A、B两个数据,值分别为1,2.
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘。
I.事务提交
innodb 有2个优化
- redo log 不是直接写入磁盘, 是先写入redo log buffer, 然后定期flush到磁盘, 因此,当flush到磁盘时, 会把一批commit和abort/uncommitted的redo log 都刷到了磁盘, 后续如何处理依赖undo log
- 在恢复的时候, 是结合undo log 一起进行恢复, 因为在恢复的过程中,还有一些log是没有commit的,但已经刷到了磁盘, 当前还是会把他apply,但通过undo log来进行恢复
- redo log的文件空间是预分配的,为了最优性能,操作是append only
- 把undo log当作数据来处理, 因此undo log 也能用buffer来缓存, undo log 也是定期刷磁盘, 而不是每次commit必须刷磁盘
记录1:<trx1,Undo Loginsert<undo_insert…>>
记录2:<trx1,insertA…>
记录3:<trx1,Undo Loginsert<undo_update…>>
记录4:<trx1,updateB…>
记录5:<trx1,Undo Loginsert<undo_delete…>>
记录6:<trx1,deleteC…>
记录7:<trx1,insertC>
记录8:<trx1,updateBtooldvalue>
记录9:<trx1,deleteA>
针对介质的防护
备份
- 备份可以使用日志
- 备份分2个等级
- 全量转储
- 增量转储, 第一次为0级, 而后每一级即为上一次的delta备份
日志方式倾向于redo或者undo/redo 一体 日志, 使用undo 日志干不了
- 写入
- 根据采用的日志方式(如redo log)执行一个适当的检查点
- 执行转储, 拷贝数据到远程节点
- 至少dump 第二步中的checkpoint 和checkpoint之前的日志完成dump
- 写入日志记录
恢复
- 先找全量转储
- 再找增量转储,