2015年6月1号, Twitter 对外宣讲了他们的Heron系统, 从ppt和论文中,看起来完爆storm。昨天,抽空把论文,仔细读了一遍, 把个人笔记和心得分享一下:
最后总结:
Heron更适合超大规模的机器, 超过1000台机器以上的集群。 在稳定性上有更优异的表现, 在性能上,表现一般甚至稍弱一些,在资源使用上,可以和其他编程框架共享集群资源,但topology级别会更浪费一些资源。
而从应用的角度,应用更偏向于大应用,小应用的话,会多一点点资源浪费, 对于大应用,debug-ability的重要性逐渐提升。 另外对于task的设计, task会走向更重更复杂, 而JStorm的task是向更小更轻量去走。
未来JStorm可以把自动降级策略引入, 通过实现阿里妈妈的ASM, debug-ability应该远超过storm, 不会逊色于Heron, 甚至更强。
现状:
所有的老的生产环境的topology已经运行在Heron上, 每天大概处理几十T的数据, billions of消息
为什么要重新设计Heron:
【题外话】这里完全引用作者吐槽的问题, 不少问题,其实JStorm已经解决
debug-ability 很差, 出现问题,很难发现问题, 多个task运行在一个系统进程中, 很难定位问题。需要一个清晰的逻辑计算单元到物理计算单元的关系
需要一种更高级的资源池管理系统
可以和其他编程框架共享资源, 说白了,就是类似yarn/mesos, 而在Twitter就是Aurora
更简单的弹性扩容和缩容 集群
因为不同task,对资源需求是不一样的, 而storm会公平对待每个worker, 因此会存在worker浪费内存问题。当worker内存特别大时, 进行jstack或heap dump时,特别容易引起gc,导致被supervisor干掉
经常为了避免性能故障,常常进行超量资源分配, 原本100个core,分配了200个
认为Storm设计不合理的地方
一个executor 存在2个线程, 一个执行线程, 一个发送线程, 并且一个executor运行多个task, task的调度完全依赖来源的tuple, 很不方便确认哪个task出了问题。
因为多种task运行在一个worker中, 无法明确出每种task使用的资源, 也很难定位出问题的task,当出现性能问题或其他行为时, 常用就是重启topology, 重启后就好了,因为task进行了重新调度
日志打到同一个文件中,也很难查找问题,尤其是当某个task疯狂的打印日志时
当一个task挂掉了,直接会干掉worker,并强迫其他运行好的task被kill掉
最大的问题是,当topology某个部分出现问题时, 会影响到topology其他的环节
gc引起了大量的问题
一条消息至少经过4个线程, 4个队列, 这会触发线程切换和队列竞争问题
nimbus功能太多, 调度/监控/分发jar/metric report, 经常会成为系统的bottleneck
storm的worker没有做到资源保留和资源隔离, 因此存在一个worker会影响到另外的worker。 而现有的isolation调度会带来资源浪费问题。 Storm on Yarn也没有完全解决这个问题。
zookeeper成为系统的瓶颈, 当集群规模增大时。 有些系统为了降低zk心态,新增了tracker,但tracker增加了系统运维难度。
nimbus是系统单点
缺乏反压机制
当receiver忙不过来时, sender就直接扔弃掉tuple,
如果关掉acker机制, 那无法量化drop掉的tuple
因为上游worker执行的计算就被扔弃掉。
系统会变的难以预测(less predictable.)
常常出现性能问题, 导致tuple fail, tuple replay, 执行变慢
不良的replay, 任意一个tuple失败了,都会导致整个tuple tree fail, 不良的设计时(比如不重要的tuple失败),会导致tuple轻易被重发
当内存很大时,长时间的gc,导致处理延时,甚至被误杀
队列竞争
Heron设计
设计原则:
兼容老的storm api
实现2种策略, At most once/At least once
架构:
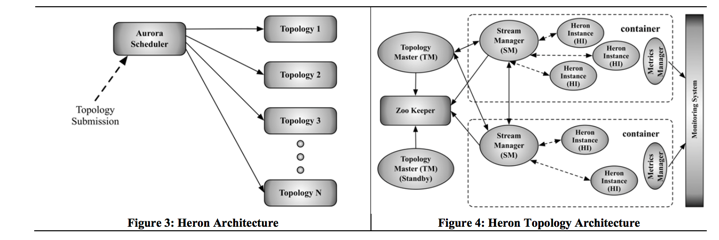
调度器
Aurora是一个基于mesos的通用service scheduler, Hero基于Aurora 实现了一套Topology Scheduler, 并且这个调度器已经提供了一定的抽象,可以移植到yarn/mesos/ec2(我的理解应该稍加修改就可以运行在其他通用型调度器上)
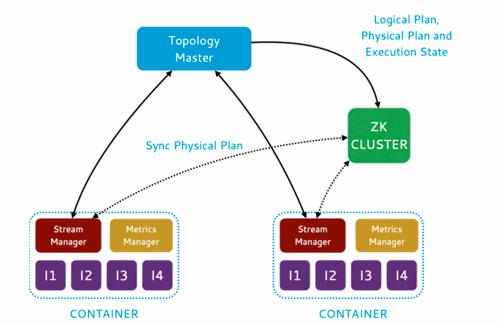
第一个container 运行 Topology Manager(TM), 其他的container 内部会运行一个Stream manager/Metrics Manager 和多个Heron Instance。 这里一个container类似一个docker感念,表示一个资源集合,是Aurora的调度单元, 多个container可以运行在一台机器上, 分配多少container由Aurora根据现有资源情况进行分配, 另外一个container设置了cgroup。 从逻辑或角色上,这里的container相当于jstorm中的worker。
Topology Manager
tm伴随整个topology生命周期, 提供topology状态的唯一contact (类似yarn的app master)
可以一主多备, 大家抢占zk 节点, 谁胜出,谁为master, 其他为standby
Stream manager(SM)
最大的改变就是源自Stream manager, Stream manager就相当于一个container的tuple的总线(hub)。 所有的Hero Instance(HI)都连接SM进行send/receive
如果container内部一个HI 发送数据到另外一个HI,走的是本地快速通道。
Backpressure 反压机制
当下游处理速度变慢后,通过反压机制,可以通知上游进行减速, 避免数据因buffer被塞满而丢失,并因此带来资源浪费。
TCP 反压:
当一个HI 处理慢了后,则该HI的接收buffer会被填满, 紧接着本地SM的sending buffer被填满, ? 然后会传播到其他的SM和上游HI。
这个机制很容易实现,但在实际使用中,存在很多问题。因为多个HI 共用SM, 不仅将上游的HI 降速了,也把下游的HI 降速。从而整个topology速度全部下架,并且长时间的降级。
Spout 反压
这个机制是结合TCP 反压机制, 一旦SM 发现一个或多个HI 速度变慢,立刻对本地spout进行降级, 停止从这些spout读取数据。并且受影响的SM 会发送一个特殊的start backpressure message 给其他的sm,要求他们对spout进行本地降级。一旦出问题的HI 恢复速度后,本地的SM 会发送 stop backpressure message 解除降级。
Stage-by-Stage 反压
这个类似spout反压,但是一级一级向上反压。
结果
Heron最后采用的是spout反压, 因为实现比较简单,而且降级响应非常迅速。 并且可以很快定位到那个HI 处理速度慢了。 每个socket channel都绑定了一个buffer, 当buffer 的 queue size超过警戒水位时,触发反压,减少时,接触反压。
这种机制,不会丢弃tuple,除了机器宕机。
topology可以设置打开或关闭。
Heron Instance
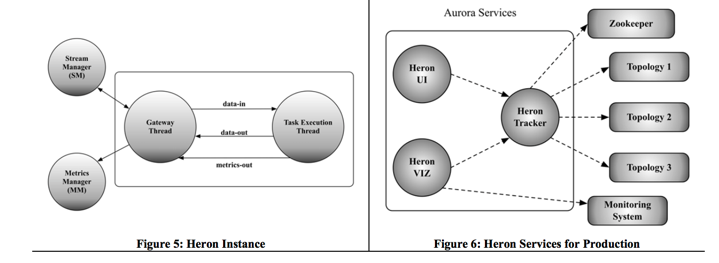
一个task 一个进程,
所有的进程之间通信都是使用protocol buffer
一个gateway线程, 一个执行线程。 gateway线程负责和外围通信, sm/mm。 执行线程和现有storm的执行线程非常类似。执行线程会收集所有的metrics,然后发送给gateway线程。
这个data-in/data-out队列会限定大小, 当data-in 队列满了的时候, gateway线程停止从local SM 读取数据。同理如果data-out队列满,gateway会认为local SM不想接受更多的数据。 执行线程就不再emit或执行更多的tuple。
data-in/data-out队列大小不是固定, 如果是固定时, 当网络颠簸时,会导致内存中大量数据堆积无法发送出去,并触发GC, 并导致进一步的降级。因此是动态调整, 定期调整队列大小。 如果队列的capacity超过阀值时, 对其进行减半。这个操作持续进行指导队列的capacity维持在一个稳定的水位或0。这种方式有利避免GC的影响。 当队列的capcity小于某个阀值时, 会缓慢增长到配置大小或最大capacity值。
Metrics manager(mm)
收集所有的metrics,包括系统的和用户的metrics, 也包含SM的。 mm会发送metrics 给monitor系统(类似ganglia系统),同样也会给TM.
流程:
提交任务, Aurora分配必要的资源和在一些机器上调度container
TM 在一个container上运行起来,并注册到ZK
每个container的SM 查询ZK 找到TM, 向TM 发送心跳。
当所有的SM 连上TM后, TM 执行分配算法, 不同的compoent到不同的container。 这个阶段叫物理执行计划(类似SQL解析和执行过程)。并将执行计划放到ZK。
SM 下载执行计划,并开始相互之间进行连接, 与此同时, 启动HI, hi开始发现container,下载他们的执行计划,并开始执行
整个topology完成初始化,开始正式的发送和接收数据。
三种failure case
进程挂了
如果TM 挂了, container会重启TM, TM 会从ZK 上重新下载执行计划。如果有一主多备,则备机会被promotion。 所有SM 会切到新的TM
如果SM 挂了, container依旧会重启TM, 并从ZK 下载执行计划, 并检查是否有变化。其他的SM 会连到新的SM
如果HI 挂了, 重启并下载执行计划,并重新执行。
外围系统
外围系统就介绍一下Heron Tracker
Heron Tracker
负责收集topology的信息, 类似一个gateway的角色。 通过watch zk,发现新的TM, 并获取topology的一些原数据。是一种Aurora service, 提供load balance在多个instance之间。
可以提供REST API。可以获取
逻辑和物理执行计划
各种metrics, 系统的和用户的
日志link
Heron UI/VIZ
UI 提供传统的UI 方式。
VIZ 提供全新的UI, 可以看到更多的metrics, 曲线和健康检查。比UI 炫酷很多。
性能报告和测试过程:
了解整个系统架构和工作流程后, 后面的性能测试报告, 没有看了, 也差不多有个概念了。
个人思考和总结:
相对于JStorm, Heron把角色剥离的更清晰明了。
- 调度器
scheduler 负责container的调度,这个调度非常的纯粹,可以直接复用yarn/mesos/, 现有的TM 其实就是nimbus,唯一一点变化就是这个TM 只负责自己topology的信息, 不是负责所有topology。这个TM 就相当于yarn下的app master, 非常适合目前主流的调度系统。 当集群规模非常大的时候, 并且每个应用都比较大的时候, 这个架构会非避免nimbus成为瓶颈。 不过storm-on-yarn模式下, 可能通过一个nimbus管理一个小的逻辑集群,也可以解决这个问题, 并且当topology 比较小的时候, 可以通过大家公用一个nimbus,节省一些资源。
- container
这里特别要把container拿出来仔细说一下, 这个container是Auron的一个资源单元。如果将Auron类似JStorm的worker, 你就会发现角色和架构是多么的类似。
* container和jstorm的worker都可以设置cgroup,达到一定的资源隔离
* container内部的SM/MM 其实就类似jstorm worker内部drainer/dispatcher/metricsreport线程。
但container 相对jstorm 的worker 还有一些其他的优缺点:
优点:
* 这个粒度可以控制的更自由, 这个container 可以控制cpu 到更多的核,更多的内存上限。 但jstorm的worker 基本上最多10个核, 而且当内存太大,在core dump和gc的时候压力会比较大。
* container还带一定的supervisor的功能,当container内部任何进程挂了, container都会负责把它重启, 因此整个系统的心态逻辑会非常的简单。 ?Auron <–> container, ? ?Container <– > tm/sm/mm/hi. ?整个系统的心跳压力模型会更简单, 心跳压力(对ZK)也更小
性能:
ppt和文档里面说性能有15倍以上的提升, 这个在某些设置下是可以达到这种效果, 但通常情况性能应该比JStorm还要差一点点。
如何达到这种效果呢,
前提条件是, grouping方式不是选择localOrShuffle或者localFirst
就是把container设置的尽可能的大, 最好是独占一台机器。这样SM和SM 之间的通信就会大幅减少, 而一个container内部的HI 通信走内部通道。因此会有更多的HI走内部通道。而jstorm/storm, worker比较多的时候, worker和worker之间会创建netty connection, 更多的netty connection会带来更多的内存消耗和线程切换。 尤其是worker数超过200个以上时。
但为什么说通常情况下,性能应该还要比JStorm差一点点呢。
因为在生产环境, container 是不可能占有这么多资源, 否则Auron的调度太粗粒度,一台机器只跑一个大container, 会导致更严重的资源浪费。正常情况下, 一个container绑定2 ~ 4个核, 这个时候,和一个普通的jstorm worker没有什么区别, 但jstorm worker内部task之间数据传输的效率会远远高于Heron, 因为Heron的HI 之间即使是走进程间通信方式, 也逃脱不了序列化和反序化的动作, 这个动作肯定会耗时, 更不用说IPC 之间的通信效率和进程内的通信效率。
资源利用率:
Heron 可以非常精准的控制资源使用情况, 能够保证, 申请多少资源,就会用多少资源。 在大集群这个级别会节省资源,在topology级别浪费资源。
如果JStorm-on-yarn这种系统下, 因为每个逻辑集群会超量申请一些资源, 因此资源可能会多有少量浪费。无法做到像Heron一样精准。 如果改造nimbus成为topology level 类似TM(腾讯在jstorm基础上实现了这个功能), 这个问题就可以很好的解决。在普通standalone的JStorm模式下, jstorm不会浪费资源, 但因为Standalone,导致这些机器不能被其他编程框架使用, 因此也可以说浪费一定的资源。 但这种情况就是 资源隔离性– 资源利用率的一种平衡, 现在这种根据线上运行情况,浪费程度可以接受。
在topology这个粒度进行比较时, Heron应该会消耗掉更多的资源。 最大的问题在于, Heron中一个task就是一个process, 论文中没有描叙这个process的公共线程, 可以肯定的是, 这个process比如还有大量的公共线程, 比如ZK-client/network-thread/container-heartbeat-thread, 一个task一个process,这种设计,相对于一个worker跑更多的task而言,肯定浪费了更多的CPU 和内存。
至于吐槽在Storm和JStorm,超量申请资源问题, 比如一个topology只要100 个cpu core能完成, 申请了600个core, 这个问题,在jstorm中是绝对不存在的, jstorm的cgroup设置是share + limit方式, 也就是上限是600 core,但topology如果用不到600个core, 别的topology可以抢占到cpu core。 在内存方面, jstorm的worker 内存申请量,是按照worker最大内存申请, 但现代操作系统早就做到了, 给你一个上限, 当你用不了这么多的时候, 其他进程可以抢占。
在稳定性和debug-ability这点上:
Heron 优势非常大, 主要就是通过2点:
自动降级策略, 也就是论文说的backpressure, 这个对于大型应用是非常有效的, 也很显著提高稳定性。
一个task一个process, 这个结合降级策略,可以非常快速定位到出错的task, 另外因为一个task 一个process, task之间的影响会非常快, 另外也避免了一个进程使用过大的内存,从而触发严重的GC 问题。
最后总结:
Heron更适合超大规模的机器, 超过1000台机器以上的集群。 在稳定性上有更优异的表现, 在性能上,表现一般甚至稍弱一些,在资源使用上,可以和其他编程框架共享资源,但topology级别会更浪费一些资源。
另外应用更偏向于大应用,小应用的话,会多一点点资源浪费, 对于大应用,debug-ability的重要性逐渐提升。 另外对于task的设计, task会走向更重更复杂, 而JStorm的task是向更小更轻量去走。
未来JStorm可以把自动降级策略引入, 通过实现阿里妈妈的ASM, debug-ability应该远超过storm, 不会逊色于Heron, 甚至更强。
其他流式编程框架
1.S4 Distributed Stream Computing Platform.?http://incubator.apache.org/s4/
Spark Streaming. https://spark.apache.org/streaming/?
Apache Samza. http://samza.incubator.apache.org
Tyler Akidau, Alex Balikov, Kaya Bekiroglu, Slava Chernyak, Josh?Haberman, Reuven Lax, Sam McVeety, Daniel Mills, Paul?Nordstrom, Sam Whittle: MillWheel: Fault-Tolerant Stream?Processing at Internet Scale.?PVLDB 6(11): 1033-1044 (2013)
5.?Mohamed H. Ali, Badrish Chandramouli, Jonathan Goldstein,Roman Schindlauer: The Extensibility Framework in Microsoft?StreamInsight.?ICDE?2011: 1242-1253
Rajagopal Ananthanarayanan, Venkatesh Basker, Sumit Das, Ashish?Gupta, Haifeng Jiang, Tianhao Qiu, Alexey Reznichenko, Deomid?Ryabkov, Manpreet Singh, Shivakumar Venkataraman: Photon:?Fault-tolerant and Scalable Joining of Continuous Data Streams.?SIGMOD?2013: 577-588
DataTorrent.?https://www.datatorrent.com
Simon Loesing, Martin Hentschel, Tim Kraska, Donald Kossmann:?Stormy: An Elastic and Highly Available Streaming Service in the?Cloud. EDBT/ICDT Workshops 2012: 55-60