Abstract
论文是很早以前看的, 后来把笔记梳理一下。
F1 就是一套胶水系统, 将oltp和olap 系统粘在一起提供一个统一接口层和服务层, 类似数据库里面的HTAP系统, 但数据库htap系统往往是自身提供oltp和olap 服务, 而f1 是通过不同的系统来达到htap的效果。
F1 有一个背景就是现有很多数据库系统,如spanner, bigquery, dremel, 如果让应用无缝的在这么多系统中切换,一套接口,一套服务完成所有的事情。
今天的 TiDB 有一点点f1 的味道, 上层tidb server + tikv, tispark + tiflash,不过tidb 朝着tidb server + tikv/tiflash的方向演进, 融合程度更高一些, 不过f1 在oltp 上主要是依赖spanner 来完成。
曾经的hybriddb 更类似f1 这种架构。
坦白讲: 这种胶水系统没有什么前途, 对于oltp 业务, 对时延是非常敏感, 增加一层胶水系统, 不仅让时延增长很多,而且带来不确定性, 动不动抖动一下, 这些对oltp都是无法接受的, 因此粘合的场景是大数据的和olap的业务, 对于中小型企业, 大数据的系统太复杂, 一个olap 就够用,看看aws 上redshift 大行其道,就知道这个事实, 如果粘合多个olap,那就更不现实, 哪家公司没事干运行一大堆各式各样的olap系统, olap系统基本上就是赢者通吃, 没有那么多一个业务要跑好几个olap系统的, 所以这种胶水系统是没有什么前途的。 最后,google自己的员工透露到现在为止f1 已经事实上失败了。
架构图: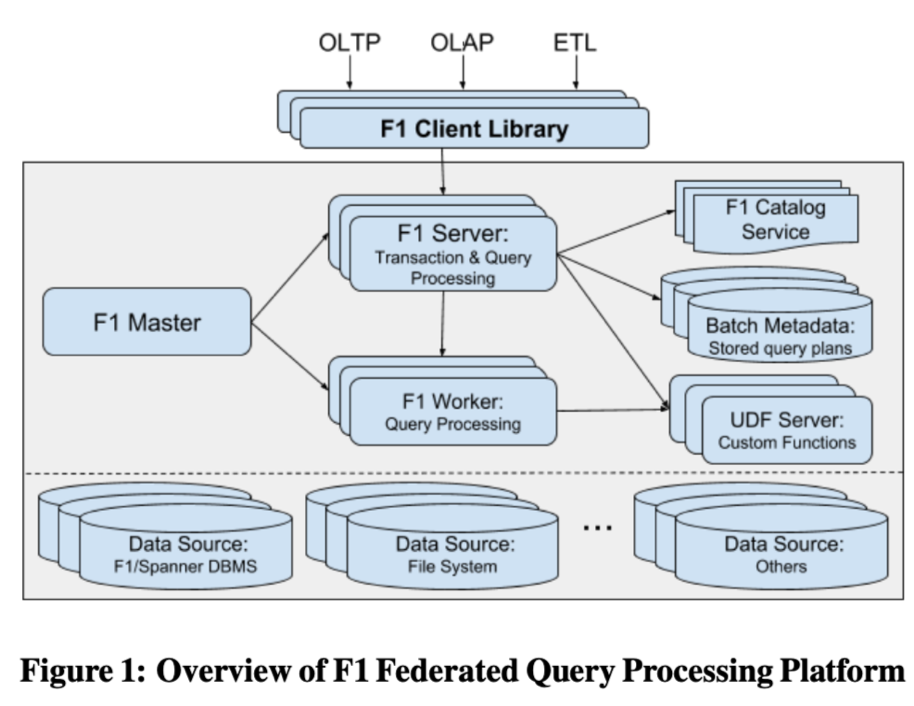
需求
- 存储计算分离, 从架构上就可以看出计算层和存储层已经分离
- 可以支持跨机房部署, 不过跨机房部署,很多时候是依赖底层的存储系统来完成, 比如spanner 本身就可以支持跨机房
- 同时支持 oltp 尤其是点查, olap, 以及大型的etl请求
- 可以很容易提高并发度来支持大数据量的计算。
- 支持UDF/UDAF/TVF
模块介绍
- F1 master, 对worker/节点 进行监控, 对查询进行监控
- F1 Server
- 对于oltp 查询(点查), 负责查询的执行, 个人理解, 做一个转义层,转成底层spanner的请求
- 对于olap的请求, 其实就是类似前端节点功能, 负责一些sql 解析,生成执行计划,查询catalog之类的工作
- F1 worker: 就是计算节点, 类似mpp数据库的worker节点
- F1 server/worker 是无状态的,不存数据, master节点会进行实时监控, 并且做failover 和扩容和缩容
- catakig service : 各种异构的数据的元数据存放在这里, 对用户展示一个统一视图
- batch metadata: batch execution 模式下,任务的元信息,如执行计划
- udf server, 一个比较有意思的模块,
- 在执行引擎以外,专门存储udf, 执行引擎和udf server 进行rpc 进行交互
- 可以对执行引擎做一些保护, 资源隔离之类的事情
- 存储系统:
- 可以是spanner, 这些主要是针对oltp的
- 分布式 file system (colossus), file system
- 其他的data source
使用
- SQL : 兼容sql 2011, 共用在dremel, bigquery, spanner, 可以多个应用迁移
- 数据写入
- 默认是分布式文件系统
- 可以export 到指定存储
- 支持session 级别临时表
- 执行模式
- central execution: 小查询, 单线程执行, 直接在server 就干了
- batch execution: 超大查询, 生成mapreduce 任务/flumejava sql 任务,放到后台大数据平台进行计算
- 执行非常类似spark方式, 一个stage 一个stage 执行,前一个stage 落盘, 当stage 挂了可以只重启单stage
- distributed execution: 普通olap 执行, 分布式执行, server 起到前端功能, 执行在worker 节点进行执行