《Volcano-An Extensible and Parallel Query Evaluation System》
Abstract
- volcano 提供一种增强扩展性并且支持并行的方式。 在算子,数据类型,算法,type-specific methods, 资源申请, 并行执行, load balancing, 查询优化启发式规则 上极具扩展性。 volcano 不假设任何特定的数据model, 仅仅假设查询基于用参数化算子来进行item tranformation。 为了达到data model 独立, 将processing control 和data item的interpretation 和manipulation 独立开。 可以同时在单进程环境和多进程环境下同时工作, 单进程query evalution plan 可以在shared-memory的机器上并行化, 也可以在distributed 环境下并行化。 并行查询过程的机制是独立于算子和语义。
有一些原则: - volcano 提供mechanism 来支持policy。 policy 是由人经验或优化器来进行设置。 mechanism和policy的独立性可以提升数据库的扩展性。
- 用迭代器来实现算子, 可以做到在单进程内高效传输数据和高效控制。
- 迭代器的统一接口容易集成新的算子和算法。
- 持续打开stream 元素的解释和控制以支持任何数据模型和任何类型,形状和展现的处理item。
- exchange的封装允许在单进程环境下开发查询算法依旧可以在多进程环境下工作。
有一些特性: - 用一种接口(support function)来将关系代数算子(很容易增加代数算子)和算子实现隔离开,support function 可以轻松增加算子和算子实现,并且可以实现任意数据类型和任意实现的算子,非预定义的。 support function 以独立item(如谓词)上的操作方式被引入进来。传递一个function给被调用的算子, 这个function会设置适当的参数来确定一些item 如selection 谓词,hash function等。
- volcano 提供2种创新的meta-operators, choose-plan 算子和exchange 算子。这2个算子不是用来进行数据处理如selection, derivation, file scan, sort, join等,主要用于查询的额外控制。
- choose-plan 算子可以用来干 dynamic query evalution, 并且可以支持延迟plan 优化直到runtime。 动态plan 允许准备多个等价plan, 每个plan 在一定实际参数下的范围下最优。choose-plan 在运行时(其他算子已经明确下来)选择一个plan,
- exchange meta-operator 算子支持并行操作, 可以在分区dataset 上进行算子间的并行, 也可以在算子内进行vertical 或horizontal 并行。其他算子可以不用exchange 算子就可以相互之间交换数据。其他算子都是设计为单进程处理环境, 并行由exchange 算子来实现, 其他算子都不考虑并行度, 所有并行问题如分区或data flow都封装在exchange 算子中。 因此data 操作和并行是正交的。exchange 算子可以帮助在数据处理时,数据驱动和demand 驱动相互切换。并行查询处理独立于算子和语义。这个算子在processor boundaries 之间交换数据。这种方式获得近线性性能提升。目前的exchange 算子只能工作在shared memory 环境下, 但我们正在在不破坏封装性的条件下移植到分布式环境中。
- 通过将处理控制(由算子提供或继承的, 在item上的操作)和解释性或控制性的data item 隔离开, 来达到data model的独立性。
相关工作:
- Wisonsin Storage System 是一个record oriented file system 提供heap files, BTree/hash index, buffer, 带谓词的scan.
- GAMA 是一个分布式集群,通过token ring来连接17台VAX 11/750, 8个cpu 各带一个local disk, 访问使用WSS, 本地磁盘只能被本地cpu 访问, 不带磁盘的cpu 可以用来干join
- EXODUS 是一个扩展的database, 带一些想tool-kit 方式的组件, 优化器生成器, storage manager。最开始,EXODUS 设计为data model 独立,但后来一个powerful,结构化的并且支持很多data model的object-oriented 的data model Extra 开发出来
整体框架
- volcano 是2层模块组成的library, 含1.5w行代码
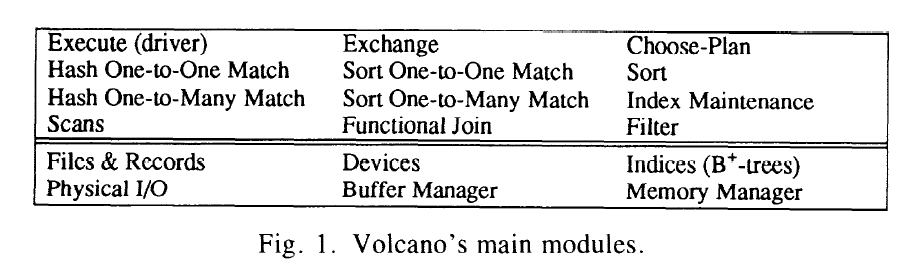
- 2层模块实现动态query evaluation plan和允许并行处理各种算法。 filesystem layer 和query process layer. File system 提供record, file, index 等带谓词的scan 和buffer 系统。 查询层是一套查询的module, 并且支持可以相互嵌套来组成一个复杂的查询tree。
- 单个record上的所有操作都是精心设计为left open。
- support function 带合适的参数 传给查询operators
File system
buffer manager 是最有意思的部分, 对性能至关重要, 它被设计支持海量的context和各种policy, 它包含多个buffer pools, 称为clusters的可变长度的buffering unit, 从high level传过来的replacement hint。 buffer manager 提供机制 (hint 是提供机制来支持灵活的policy的典型范例) pinning, page replacement, reading/writing disk pages, 这些policy来自上层软件来决定, 这些policy 由 data semantics, importance, access pattern 来决定。 buffer manager 主要通过obsered reference 来决定replacement ,而不管这个行为是上层软件来决定还是本filesystem 的提前决定。
records/clusters/扩展 组成file。 因为file 操作是一个高频操作, 因此file module 只提供最基本的功能,但这些功能性能最佳。 一个cluster 由一个或多个page 来组成, 它(cluster)是I/O 或buffer 的最小操作单元。 cluster size 由每个文件独立设定。 不同的file 可以有不同的cluster size。文件上的磁盘空间是连续空间,避免磁盘寻道并且更好的预读和write-behind。
RID 来标识一个record, 可以用RID 直接来access 一个record, 为了快速access 大量的record, volcano 不仅支持file/record的独立操作, 也支持带read-next 的scan和append 操作。 file scan 有2个接口, 其中一个是file scan的标准流程, open, next, close, rewind。 next 返回下个record的内存地址, 这个地址保证pin到内存中,直到下个next 执行时。 获得同一个cluster的下个record不需要调用buffer manager(无内存申请操作),可以高效执行。 另外一套接口是在query process过程中描述。
为了快速创建文件, scan 支持append 操作。 它申请一个record slot并返回这个新slot的内存地址, 由调用者用有效信息来填充这个record space。 append 函数不知道data和它的含义。
scan支持谓词。 next 以带参数和一个record 地址的方式来调用predicate function。 selective scan就是一个support function, scan 机制依赖从上层level传过来的predicate function。
support function作为函数entry point 传给 一个operation, 一个无类型指针作为predicate 参数。 support function的参数有2种, compiled和解释型的查询执行。 在编译性的scan中, predicate evaluation 函数是机器代码, 它的参数可以是一个常量或指向几个谓词函数的指针。 例如当predicate 是将一个string和record的field进行比较,comparison function是predicate function, string 是predicate 参数。 在解释型的scan中, 用一个通用的解释器来evaluate 查询的所有predicate, 可以传合适的code 给解释器。 解释器的entry point是predicate function。
indices 目前支持B+ tree, 接口类似files 。 一个叶子节点包含一个key和对应的信息(这个信息包含RID, 这个信息可以允许任意内容), key 和信息可以是任何类型, 必须提供一个比较函数用于比较key。 比较函数用的参数类似predicate scan 的参数。 b+ 树支持类似file 一样的scan, 如predicate和append 操作。除此之外,它还可以支持查询特定的key和 一个确定上下范围的区间。
处理的中间结果(后续称为streams), volcano 称他为virtual device, 它是只存在于buffer中, 一旦unpin,他们就消失了。 对于持久化结果或中间结果,都是使用相同的机制来简化实现。
file system 功能基本上都是很常规的, 但他们用一种灵活,高效和compact 方式来实现。 file system 支持最基本的抽象和操作, 并称之为 device, file, record, b+tree, scan。提供策略来访问这些对象,由高层软件来决定策略。设计和实现机制的一个重要目标是性能, 因为只有潜在的机制是高效的情况下, 才可以做性能研究和并行。 性能和扩展性的tradoff的前提条件是 有一个高效evaluation 平台。
query processing
查询用查询plan或关系代数表达式来表示。 关系代数的算子带查询处理算法,可以称这种关系代数为executable 关系代数(物理关系代数), 另外一种是逻辑关系代数(relational 关系代数), 算子可被viewed并被实现为一组object上的操作(volcano 不依赖这组对象的内部结构)。 实际上,更倾向在一个oriented对象数据库中使用volcano 作为query processing, 使用volcano 可以将 processing 和data item的解释进行分离。
所有的关系代数算子都被实现为迭代器, 他们支持open-next-close 协议, 基本上, 迭代器提供一个loop中的迭代组件,如initialization, increment和loop termination condition和最后的housekeeping。 允许对任意operation的结果进行迭代,类似对一个传统文件scan结果上的迭代操作。 每个迭代器带一个state record, 它包含一些参数, 如在open过程中申请hash table的大小和 state(hash table的location)。 迭代器的状态信息都存在state record并且没有static 变量, 因此可以在一个query中多次使用算法,只不过使用多个state record。
data object的操作和解释(如比较或hashing)以support function方式(entry point的指针)传给迭代器。 每个support function都使用一个参数(可以是解释型也可以是编译型)。 如果没有support function,迭代器就是空算法壳子。
迭代器可以嵌套并且可以像coroutine一样操作。 state records之间用input 指针link 在一起, 并且input指针也保存在state中。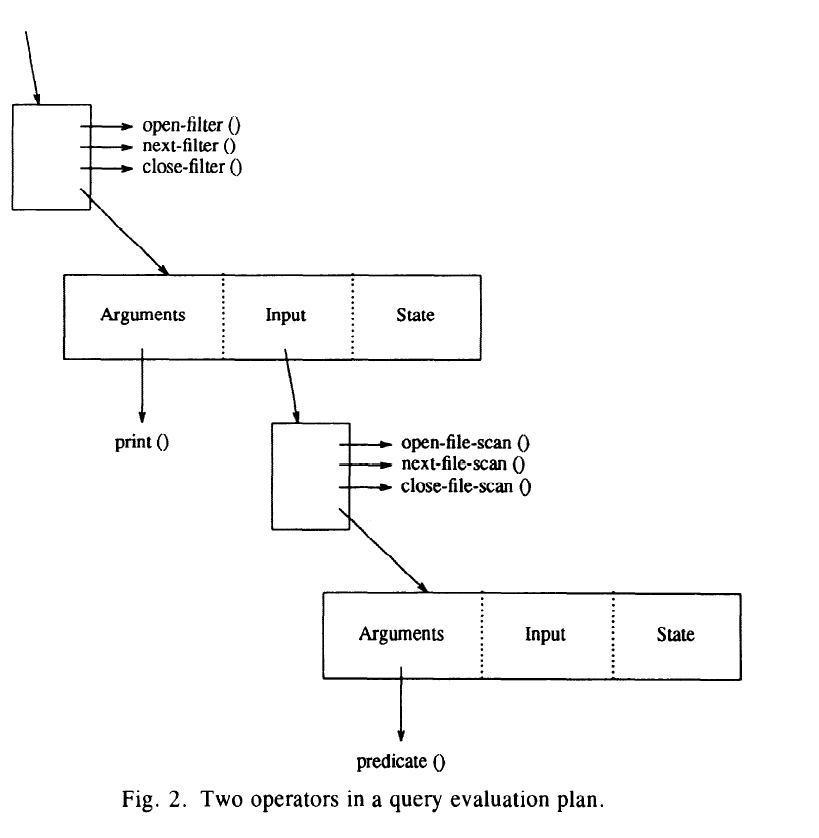
上图显示一个查询plan的2个算子。
filter operator的一个参数是print stream的function。 最顶层的结构可以访问state record和(print )function。 通过指向这个结构的指针, 可以调用这个filter 函数并将他们的local state 作为处理参数传给它(结构)。
这些函数(如open-filter)可以使用被包含在state record内的input 指针来调用input 算子函数。 因此当需要时, filter的函数可以调用file scan的函数, 根据filter的需要来推进 file scan。 整体上就是打印一个文件中选中的行。
总的来说: input 是一个复杂结构的指针, 这个结构是operator之间的桥梁, input 内部包含下一个算子的function (这个function是一个参数), 下一算子的input 和state,当前input 存在当前state中。
使用迭代器的标准形式, 一个算子不需要知道是什么算子产生它的输入,不论是复杂查询或一个简单的文件扫描。 我们称这种方式为匿名inputs或streams。 streams是一个简单但powerful的抽象, 允许combine 任意数量和任意类型的算子为一个复杂查询, 是volcano 扩展性的第二个基石, streams 代表了最高效的执行时间(无同步operator)和空间。
对最顶上的算子调用open 会实例化对应的state record 的状态(如申请一个hash table)并对所有的input进行open, 通过这种方式, 一个query的所有迭代器都会被递归初始化。 为了处理query, 持续不断call 顶层的next知道碰到end-of-stream 标记。 顶层算子调用next时, 如果他需要更多的input data 来产生output, 他会调用它input的next。 类似close 操作。
许多query或环境变量(query predicate 参数和system load 信息) 会影响policy 的决定,当opening 一个查询plan。 传递这些参数的过程称为bindings。 它是一个无类型指针。 同样用support function来实现policy 的决定。 例如 hash join 模块允许动态调整hash table的大小 , bindings 参数是在动态query evaluation plan中特别有用。
树形结构的query evaluation plan 通过命令驱动的dataflow来执行query。 next 操作的返回值除了状态标识器外,还有一个Next-Record 结构, 它包含一个RID 和在buffer pool中的record 地址。 pinned在buffer中的record 一次只能被一个operator拥有。 一个算子接受一个record 后, 可以hold 一会儿(如在hash table中), unfix 他当predicate失败或传给下一个operator。 复杂的操作会产生新的record 比如join, 必须在传出output之前组装output 并unfix他们的输入。这导致了大量的buffer call。
一个Next-Record 结构智能指向一个record。当前实现是传完整的record在operators之间。 在join中,会产生新的record,中间涉及不少copy操作, 这容易引起争论, 有一种选择是保留原始的record, 产生一个pairs、triples等。 但这个没有明确实现, 因为volcano已经实现了必要的机制,如filter 迭代器, 可以在一个stream中用一个RID 指针pair 来替换record。
总的来说, 命令驱动的数据流通过封装算子为open/next/close迭代器来实现。将processing control(迭代机制) 和item的解释和操作 独立分开的方式提供对任何数据类型的处理能力。
- scans, functional join, filter。 第一套scan的接口已经在file system里面介绍了, 第二套scan 接口,可以scan file和b+ 树, 提供迭代器接口。 open 打开file或b+树,用文件系统level的scan 过程初始化scan。 把文件名或关闭的file descriptor 存到state record里面, 是一个可选的predicate和绑定到b+ 树scan。 2种scan接口功能上等价, 区别在于,filestem的scan大量被内部使用,迭代器接口提供在查询plan中的叶子操作。
B+树索引在他们的叶子包含keys和RID , 想要用B+树的索引, 需要获得record 所在的数据文件。 在volcano中, 这种look-up 操作从B+树scan迭代器中剥离出来,用functional join 算子来执行。 这个算子用包含RID 的stream records 作为输入,或者输出用RID对应的records, 或者用input record和retrieved record 组成新的record (作为输出), 这样join b+树的entry和对应的data record。
将index 的search和record的获取分开, 有几个原因, 第一, 在叶子节点存储数据不一定是个好主意, 有时我们需要实验用lookup key来获取其他的相关信息, 其次, 这样可以将RID list的控制和复杂查询切分开, 第三,目前这种方式比较自然,可以更智能的组装复杂的对象。
上例的filter 算子执行3种功能, 依赖stat record 是否含对应的support function。 predicate 函数使用一个selection predicate, 如实现bit vector filter。 transform 函数 创建一个新的record, 一般一个全新record(如使用projection 创建一个新的record)。 apply 函数在每个record上只调用一次因为side effect受益, 典型的example就是update并打印。 filter 算子也是一个side-effect 算子(如创建一个用bit vector 过滤的 filter)。 filter 算子是一个单入单出的算子,可以干非常多的事情。
- one-to-one match, 同filter 算子一起, one-to-one match 算子可能是最高频算子, 它实现了许多set-matching 函数。 在一个算子中, 他实现了join, semi-join, outer-join, anti-join, intersection, union, difference, anti-difference, aggregation, 和duiplicate elimination。 one-to-one match 算子是一个像sort 一样的物理算子。 operator来实现所有的操作, 一个item的输出依赖对一对item比较的结果.
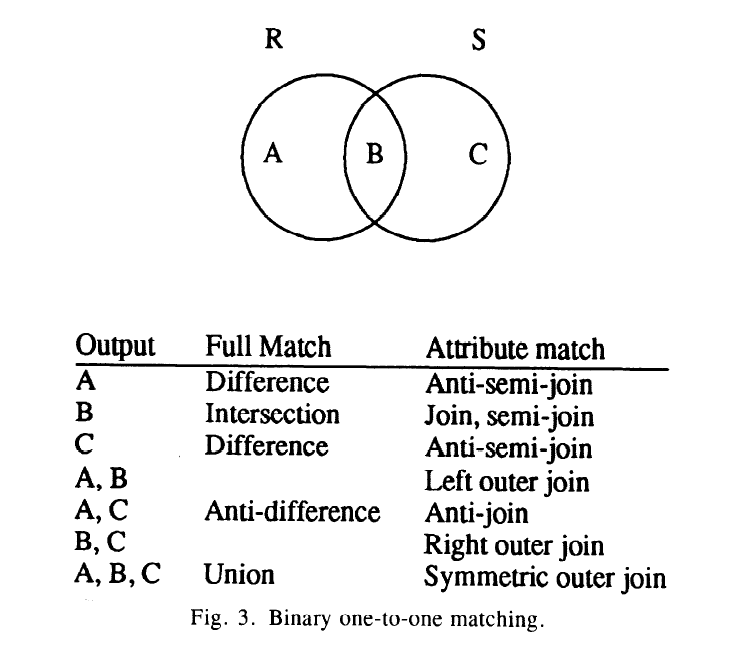
上图显示在one-to-one match 的二元算子的基本规则, 切分matching和非matching 2个set的组件,称为R, S, 产生相应的子集, 可能在一些类似join后的transformation和combination。 因为所有操作基本要求相同的步骤, 因此逻辑上实现在一个通用和高效的模块内部。 一元操作(aggregation)和二元(equi-join)操作的区别在于前者是对同一个input进行比较,而后者是对不同input比较。
因为volcano的one-to-one match 是data model 独立, 所有data item上的操作都是通过support function引入的, module不限制为关系模型但可以在任意数据类型上执行set matching 功能。
volcano 实现了2种join, merge-join/hash join, 允许对sort-/hash-base的查询算法的tradoff和对duality上进行探索。 在传统的hash join(纯内存操作,非hybrid hash join)上, build阶段(用一个input来build hashtable)后,probe 阶段(用另外一个input 来probe 这个hash table 来决定匹配并构建新的tuple)后, 原来的hash table 会扔弃掉, 增加了第三个阶段flush phase, 这个阶段用于做aggregation或其他操作。
one-to-one match 算子也是象其他算子一样的迭代器, open 包含build 阶段, 其他2个阶段都包含在next function, 当第二个input exhausted后,自动从probe阶段切换至flush 阶段。
build阶段可以用来去重或在build input上执行aggregation。 one-to-one match module 并不强制要求一个probe input, 如果只有aggregation而没有后续的join, probe 阶段就可以跳过。对于aggregation来说, 不是像传统hash join 一样来插入一个tuple到hash table中, 一个input 如果直接匹配 hash bucket的tuple, 新的tuple直接扔弃, 把值累加到老的tuple中。
hash table 会消耗大量内存,当内存oom时, 称为hash table overflow, 有2种办法解决, 如果用了优化器时, 可以做partition input, 另外一种是,当出现overflow时 创建overflow 文件。 目前volcano 使用hybrid hash join算法, 比在GAMMA里面的hybrid hash join 有几个优点:1. 插入到hash table的tuple 不需要被copy, hash table 直接指向在buffer中的record。 如果不能densely pack, 很容易内存用完。 有一个参数称为packing threshold 表示填充memory 非常快,当hash table中的item数到达这个数,就必须将item 发到overflow 文件(overflow 文件的cluster 并没有unfix到buffer, 也就是还在内存中)中,当hash table中item数达到spilling threshold, 这时将第一个分区文件spill到磁盘, hashtable 内的tuple数量减少, 当再次达到spilling threshold, 第二个partition 被再次spill到磁盘, 依次进行recursive。
第一个parition的fan-out 是由总内存大小减去packing threshold 的内存大小。 通过设置packing和spilling threshold 基于expected build input size, 优化器可以避免对小的build input 进行record copy, 避免大的build input的overflow。 当build input size 不能被准确estimated时, 优化器可以基于评估的input size进行动态调整, 如可以很确定不会出现overflow, 可以把threshold 设置很高, 如果overflow极有可能, 就会把threshold设定为相对低的一个值。
可以把初始的packing和spilling threshold 设置为0, 这样overflow的avoidance行为就和grace database machine是一样的。 除了调整overflow的参数, 还可以优化cluster size, recusion depth参数。
one-to-one match的第二个版本是基于sorting, 有2个模块, 一个是disk-based merge-sort 和实际的merge-sort。 merge-join类似hash-join 一样支持semi-join, outer join, anti join和set 操作。 sort 算子用迭代器来实现。 open sort 迭代器 准备sorted runs for merging, 如果输入数超过最大支持数, 会进行多级merge。最后一个merge 有next 函数来进行驱动。 如果完整的input 可以放到sort buffer中, 他会保留在buffer中,直到下一个next 函数。 sort 算子同样支持aggregation和去重。 可以在操作的早期执行, 比如写临时文件。
通过将item组上的操作控制 和独立item上的解释/控制进行分离, 他可以高频执行大量的set matching task并可以在任意data types和models 上执行这种task。 这种在overflow 管理上的机制和策略的切分可以支持overflow avoidance 和hybrid hash overflow resolution 一样。 同时支持sort/hash-based 算法提供一些实验性质的研究, 在duality和trade-off 在sort和hash基础的查询处理算法之间。迭代器保障了one-to-one match 算子 可以很容易和其他算子合并甚至一些还没有设计的新算子。
3. one-to-many match, 这个算子是 compare 每个item 和许多其他的item 进行比较以决定是否生成一个新的item。 典型例子是relational division, 这个关系代数算子对应在关系微积分中的全称量化。volcano中有2个关系除, 第一个版本是基于sorting的 native division, 第二个版本被称为hash division, 用了2个hash table, 一个用于除数, 一个用于商。 可以发现有2种算法和基于aggregation 函数的可选算法, 在分析的和实验性的性能比较结果和对hash table overflow和多处理器实现的2个分区策略的讨论细节中。 我们正在研究怎样生成这些算法, 用一种和aggregation/join的类 可比较的方式来生成这些算法。
扩展性
讨论volcano 用了哪些方式来提升扩展性。
- 当extend 对象类型系统,比如 一个新的抽象数据类型类似date/box, volcano 可以不受影响的, 因为他自己不提供type system。 所有对独立object的操作和计算都是由support function来执行的。 volcano 不完整,但将处理独立 instance的解释, 提供了一个好的接口。 volcano 在instance type和语义上继承了扩展性。
在算子之间用next 迭代器处理的data item是记录。 这会是一个不可接受的问题和限制。 volcano 只传root component 节点 records, 在load 和fixing 必要的record 到buffer中和合适的swizzling record内部指针。 一些非常简单的对象会被一些函数性的join算子给封装起来。 在对象或者non-first-normal-form 数据库中, 对这种算子的通用化是很有必要的, 可以在volcano中很容易做到。实际上, 在REVELATION 对象数据库中, 用了一个assembly 的算子。
为了在单独object或aggregate 函数中增加新的函数, 如几何平均, 要求合适的support function, 并把他传给一个query procession routine。 也就是, 只要接口和返回值是正确的, query 处理路径不会受support function的语法影响。 volcano 在functionality on 单独object的扩展性是因为 volocano 只提供抽象和实现 在处理和sequencing 对象集合用stream, 解释和控制 独立object 的能力是通过supoort function来引入的。
为了合并一个新的access 函数, 如R-tree的多维索引, 必须定义合适的迭代器。 不仅检索并且维护storage 结构用迭代器的形式。 比如, 由predicate 定义的一组item需要被update, 迭代器可以 feed 它的data 到一个维护的迭代器。 fed into到维护迭代器的item 会包含要被update的storage 结构, 如RID 或一个key, 一个新的值会被计算出来。 update 多个结构可以用nested 迭代器来高效组织和执行。 更进一步, 通过btree排序让维护更高效, 一个sort/ordering的迭代器很容易可以加到计划中。 很容易考虑计划不仅通过检索并且update plan。 stream的概念很开放,匿名的input 可以保护现存的查询处理模块和来自其他迭代的新的迭代器。
为了引入一个新的算法, 这个算法需要支持code迭代器的范式。 算法必须实现open/next/close , 必须用这些函数来处理输入stream和输出。 当以这种形式添加算法后, 集成这个算法到volcano是非常简单。 例如, one-to-one match或者division 算子 不用考虑其他算子就被加入进来, 在早期 支持overflow的hash base的one-to-one match算子替换in-memory-only的hash base 算子给取代时, 没有其他的算子或者meta 算子被修改。 最近添加了一个复杂object assembly 算子。
在不同的context下考虑扩展性。 为了长期运行, 提供一个交互式 前端可以让使用volcano 更简单。 我们正在做一个 双前端, 一个是非优化的命令解释器 基于volcano的执行代数, 另外一个是基于逻辑关系代数或微积分语言的带优化的前端。优化器生成plan的翻译 由一个模块 walk 优化器生成的evaluation plan, state records, support function。 用有优化能力的前端来做 动态 查询evaluation plan。
dynamic query evaluation plan
在大部分数据库系统中, 一个查询嵌入到用传统编程语言实现的程序后, 一旦程序被编译,这个查询就会被优化。 查询优化器必须假设这个查询内出现的程序变量和这个数据库的数据是不变的。这些假设包括, 通过猜测程序变量的典型值和database 在查询期间是不变, 优化器同样也会预测资源的使用量。 优化的结果依赖这些假设。 如果一个查询计划在一个时间内重复使用, 则重新优化就很有必要。 我们正在避免重新优化, 通过一个dynamic query evalution plan的技术。
volcano 使用choose-plan 算子来实现 多plan的access module和动态计划。 它并不是像data 控制算子那样运行。 他提供查询执行上的控制, 类似meta-operator。 他也提供open/next/close 函数, 因此可以插到plan的任何地方。open 操作决定了用那个等价plan, 并用他作为输入。 在open 上调用support function 来支持策略决定。 next/close 会调用对应的操作来出来open 选择的那个input。
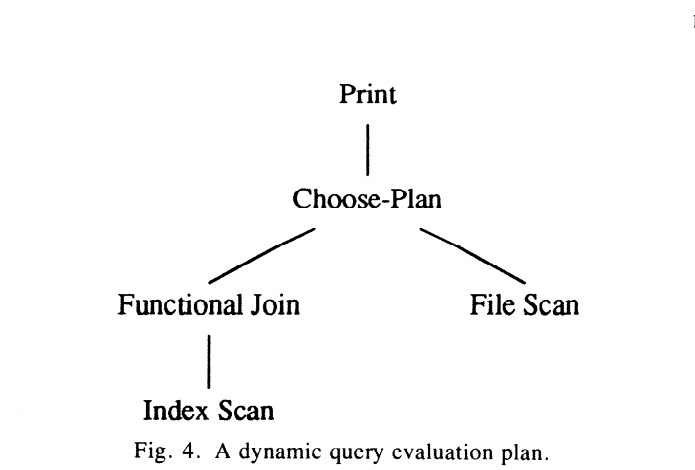
selection 谓词是由一个程序变量来控制的。 index scan 和function join 一般比file scan 更快,但如果index 没有load到内存并且大量的item 需要检索时, file scan 更快。 优化器会为这2种case 高效准备, 应用程序可以在任何谓词值下都可以工作很好。
choose-plan 灵活性很高,如果在一个query evaluation plan的顶层, 它实现多plan access module。 如果在一个计划中,插入了多个choose-plan 算子, 他实现一个动态query evaluation plan。 所有动态plan的形式可以用一个简单和高效的机制来实现。 choose-plan 没有policy来决定选择那条plan, 它仅仅提供机制, 通过support function引入policy, 决策由query 变量/resource/竞争 状况,其他考虑(如用户priority)。
choose plan 算子提供在查询优化和极少的代码上很大的自由。因为他符合查询处理的范式, 他对其他operator 毫无影响,并且可以用很灵活的方式来使用。
多进程查询evaluation
大量研究表明查询处理可以用并行算法进行加速。 很容易在数据里面探索多进程处理
- 查询用一个计划树来表示, 算子很容易用几个进程来处理, 进程之间形成pipeline。 – 算子之间的并行
- 每个算子生产和消费数据, 这些数据可以被分区, 从而可以被并行 – 算子之内的并行
当volcano 移植到多进程环境中, 代码基本不用修改。 所有的并行在一个算子内部并在算子间提供标准的迭代接口。
目前并行和同步 都是在一个叫做exchange的算子完成。 它同样有open/next/close, 因此它可以查到计划树的任何地方。
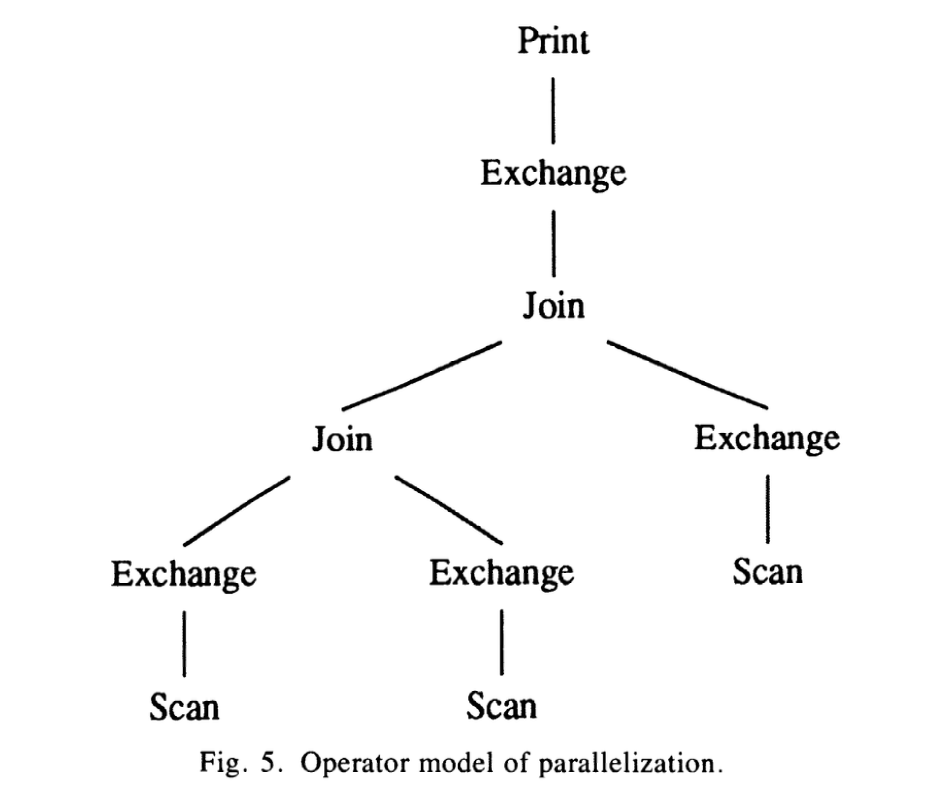
上图显示一个复杂的查询,包括file scan, join和exchange。
vertical 并行(垂直并行)
exchange的第一个功能是做vertical parallelism 或者处理之间的pipeline。 在共享内存中创建用于同步和data exchange的port 数据结构后,open函数创建一个新的进程。 子进程完全复制父进程。 在父进程和子进程中, 各自的exchange 算子走不同的路径。
父进程作为消费者, 子进程作为生产者。 消费者进程内部的exchange 算子像普通迭代器一样运行, 仅仅是它接受到的数据是跨进程的而不是迭代器之间的call(同进程的)。 在创建子进程后, 消费者的open_exchange 就完成了。 next_exchange 就等待port 来的数据 并一次返回一个record。 close_exchange 通知生产者 可以close了, 等待生产者的acknowledgement并返回。
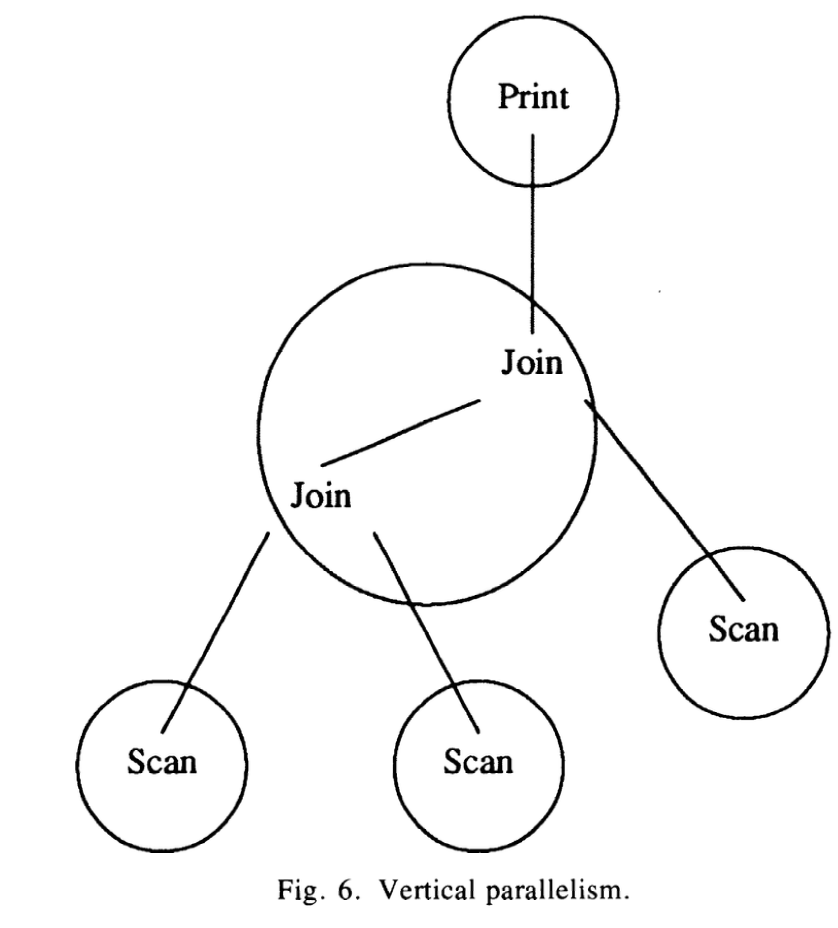
上图显示了vertical 并行或exchange 算子形成的pipeline。 exchange 算子创建多进程, 并执行各自进程的边界, 将现存的进程边界对work 的算子透明起来。 join 算子执行在同一进程, exchange 算子可以在执行树中任意放置。 exchange 仅仅提供并行的机制, 而各种并行策略都是有可能的。
在生产者进程中, exchange 算子通过在它自己输入上的open/next/close 成为查询树上在exchange 算子之下的其他算子的驱动。 对next 输出进行打包, 是一组next-record的数据结构。 打包大小是exchange 迭代器的state record 上的一个参数, 可以设置1 到32000. 但打包好, 它会发送到port 的一个linked list,并用信号量通知consumer 有个新的packet。 packet 放到共享内存, 只能被consumer 进行拆包。
当生产者的输入处理完, 生产者会标记最后一个packet 为end-of-stream tag, 等待consumer 同意关闭所有的open files。 等待一下很有必要, 因为虚拟设备上的文件不会被close 直到所有的record 都在buffer中被unpin。
exchange 模块使用一个和其他算子不同的dataflow 样式, 其他模块都是基于命令驱动方式的data flow, exchange 算子内的生产消费者使用一种数据驱动方式的dataflow。 我们同样倾向于对于horizontal parallelism 中使用exchange 算子, 它很容易基于data驱动来实现。 第二, 这个计划不再需要request message, 即使一个计划含有request message,比如使用信号量, 在一个共享内存的机器上执行会产生不可避免的延迟和开销。 高并行度和高性能的查询需要一个紧密网络, hypercube,共享内存机器, 最后证明data exchange的工作方式在share nothing的数据库中工作良好。
exchange 有2个开关 flow control 和反压, 他们使用额外的信号量。 假设生产者的速度比消费者快很多, 生产者就会pin 很多buffer, 这样自然就把整体性能拖慢。 如果使用flow control, 当生产者发送一个packet 到port, 它必须请求一个flow control 的信号量, 直到消费者接受到packet后释放对应的flow control 信号量。 信号量的初始值可以决定生产者可以领先多少个packet。
注意, 流控和命令驱动的数据流不是一回事。 一个区别是 命令驱动是一个刚性请求和分发, consumer 会等待producer 直到下个输出。 第二个区别是, 流控很容易结合水平分区和并行。
水平并行
有2种形式的水平并行, 一种称为bushy 并行和算子内并行。 在bushy 并行中, 不同的cpu 执行复杂查询树的不同子树。 算子内并行,表示不同的cpu 执行相同的算子,对数据集或中间结果做分区。
bushy 并行很容易通过在执行树中插入exchange 算子来实现, 比如树中含有merge join, 在2个input 各插入sort 算子后,在sort 算子和join算子之间插入exchange 算子。 在fork 子进程后, 子进程produce 第一个输入按照sort order, 父进程执行第二个sort input。 这样2个sort 就并行操作了。
算子内并行要求数据分区, 分区需要使用多文件, 尤其是在不同的设备上。 可以通过增加多队列在一个端口上实现中间结果的分区, 如果有多个消费者,则每个消费者消费自己的队列, 生产者用一个support function 来决定数据将去哪个queue, support function 可以是round robin, key range或者hash 分区。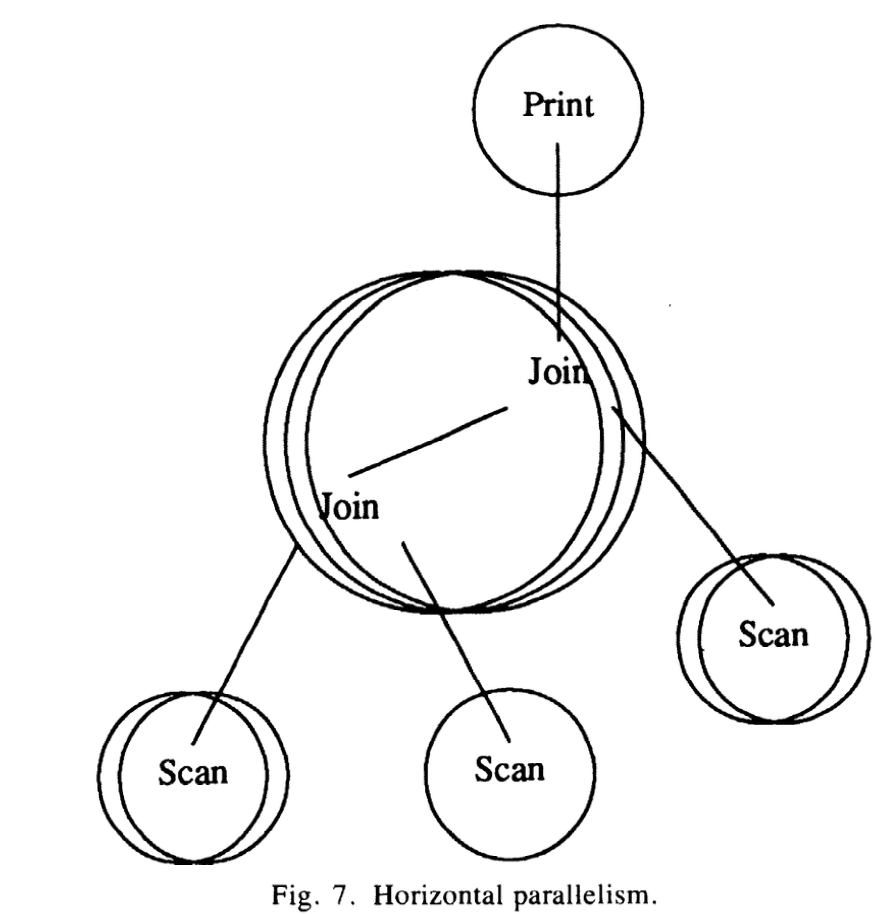
上图显示水平分区。 join 算子被3各进程来处理, 每个file scan 算子被一个或2各进程来处理, 尤其是不同设备上文件分区。 和之前图的区别, 在exchange state reocrd内的并行度参数 会被设置为2或3, exchange 算子用分区support function来传输文件扫描输出到join 进程。 所有的文件扫描进程都可以传输数据到所有的join进程, 但数据只会出现在它自己的join 进程。 如果在不同属性上有2个join和使用分区性质的并行join, 这种限制就会让并行join 不可行。volcano 提供一个新的exchange 算子,叫inter-change。
如果一个算子或者一个子树 被一组进程并行执行, 有一个进程会被称为master。 当打开一个查询树,并只有一进程运行,很自然就是master。 当一个master fork 了一个子进程 在生产者-消费者关系中, 子进程就是这个group的master。 master 生产者的动作就是通过support function 决定需要多少个slave。 如果生产者需要并行, 他就会fork 一些生产者进程。 当fork 生产者进程后, 生产者之间是没有同步, 除了2个列外, 第一, 当访问一个共享数据时, 指向消费者或buffer table的port, 在插入linked-list时,需要获得一个短时间的lock。 其次,如果一个生产者group 又同时时消费者group, 又至少2个exchange 算子和3个进程group 在vertical pipeline中, 同时兼生产者和消费者的group 需要同步2次。 在同步的空隙中, group的master 会创建port, 这个port 服务这个group的所有进程。
当close 自顶向下传递时,到达第一个exchange operator时, 消费者的master 执行close_exchange 通知所有的生产者进程, 他们可以用之前vertical 并行提到的信号量来close。 如果生产者又是消费者, 它会通知其他生产者。 这样,所有的算子会按序shut down并且整个查询会是自调度的。
exchange 算子的变体
这些变体都是实现在exchange 算子中, 由state record中的变量进行控制。
对于一些操作, 需要复制或broadcast 一个stream到所有的消费者。 一个例子就是 fragment-and-replicate 并行join算法, 其中一个输入不动,而另外一个输入需要发送到所有的进程。为了支持这个, exchange 算子可以直接发送所有的record 给所有的消费者, pin 他们多次在buffer pool中, 注意不是让他们被copy 多次,而是在共享内存中,每个消费者不再需要他们的时候可以unpin。
变体给exchange 加了2个feature,
第一个, 实现一个merge network, 通过这个网络, 多个进程生产的sort stream 可以被其他进程并行merge。 sort 迭代器可以生成sorted stream, 一个merge 迭代器很自然来自sort module。 它用一个单路merge,而不是cascade merge。 merge算子的输入是exchange, merge 迭代器要求分辨input record 通过他们各自的生成者。 另外一个例子, join 算子不关心输入的record 从哪里产生, 所有的输入在一个stream中就可以被计算。 对于merge 算子,识别input record由哪个producer 产生很重要, 这是为了正确的merge 多个sorted stream的function。
我们修改了exchange模块,这样可以将输入record 独立他们的生产者。 next_exchange 的第三个参数用于和对应生产者通讯, 从merge 到exchange 算子。 一些更进一步的改进,比如增加exchange 用的input buffer数量, 在生产者和消费者之间信号量的数量。 这些改动都是用这种方式,支持多路merge tree。 自动选择merge 路径, 这样在每个level load 都可以均匀分布。
第二个feature, 我们实现一个sort 算法, sort 随机分区的磁盘data到一个range partition的文件, 比如,一个sorted 文件分布在多个磁盘上, 要求每个cpu 2个进程 , 一个执行file scan 和分区record, 另外一个进程执行sort them。 创造比cpu 数还多的进程会带来显著的额外成本。
为了更好的利用可使用的算力, 减少每个cpu的进程数, 一个cpu 一个进程, 这样就需要对exchange 算子进行改动。 在这之前,exchange 算子只能位于一个进程的算子数的top或bottom。 这样,exchange 算子可以在进程算子树的中间。 当open 一个exchange 算子, 它并不fork 任何进程,而是建立一个通讯端口用于数据exchange。 next 会要求它input tree的record, 可能发送他们到group的其他进程, 直到找到这个record所属的partition。 这种算子被叫做inter-change。 这种方式不再需要flow control。 一个进程只有当没有input数据时跑生产者。 因此,它可能作为消费者overrunning , 生产者不会被调度。
File System Modification
需要修改文件系统以支持多进场并发请求。 volcano 不包含保护文件和record,而是磁盘的volumn table的内容,另外那种非重复性的操作如mount 都是在root process 开始前或查询结束后执行。
改动最大的还是在buffer module。 实际上,让buffer manager 在sharing memory的机器上不成为bottelneck, 本身就比较有挑战。 buffer manager上的并发控制被设计成为未来有效和高效率机制研究的测试平台,从而没有破坏policy和mechanism的分离。
用一个排他锁是最简单保护一个buffer pool和它内部数据的方式。 减少并发会把并行查询的优点给抹杀掉。 因此buffer manager 用了2层设计。每个buffer pool 都有一个锁, 并且每个描述符(page或cluster)也有一个锁。当search或update hash table和bucket chain时,必须持有buffer pool的锁。 在做i/o 操作时,绝不能持有它, 对于长时间的操作也不能持有buffer pool的锁。而当执行i/o操作或跟新buffer中的description(修改count值)时,必须持有page或cluster 锁。
当一个进程请求buffer中的一个cluster时, 可以使用原子try 机制(test-and-lock). 如果try 失败,则pool lock失败(读者感觉应该是descriptor lock失败吧) , 这个操作就会被delay并被重启。 因为持有锁的进程有可能替换请求的cluster, 因此有必要重启buffer的操作,如hash table的查询。 请求的进程必须等待上一个操作的结果。 这种对descriptor lock的重试机制可以避免死锁。 死锁有4种要求, mutual exclusion, hold-and-wait, no preemption和circular wait。volcano 破坏了第二个条件, 但另外一方面, 可能会出现饥饿, 如果减少buffer 竞争的buffer 修改可以极大的避免饥饿。
总的来说, exchange 模块封装的并行处理, 它提供一个丰富的并行机制。 buffer manager 和file system 只需做很小的改动。 exchange 最重要的属性就是它实现了3种并行方式,让并行执行完全自调度, 支持各种policy,如分区, packet size。 完全将data selection, 控制, derivation 相互之间独立开。
未来
研究:
- 研究lru/mru buffer 替换策略, 通过一个keep-or-toss hint。
- 研究在一个device 上不同的cluster size, 通过动态申请内存,而不是静态(要求仔细的evaluate),从而避免buffer shuffling。
- 研究duality 和trade offer between sort- andhash-based 的查询处理算法和实现
- 需要并行算法的性能测试和在share memory 架构下的瓶颈识别, 类似在分布式环境下的研究
- 在分布式环境下,一个独立的调度进程的优缺点
- 在shared nothing 环境下, data-driven 工作的挺好的, 尝试在shared memory的网络环境下, demand- 和data- 驱动 的结合。
改进:
- volcano 对error 探测扩展性很好,但没有用fail-fast 函数来封装error。 因此,当有一个all-or-nothing的语义时,需要修改所有的模块,在exchange 模块中,这个非常复杂, 尤其是分布式内存环境。
- 为了更好性能评估, volcano 需要加强多用户系统以允许查询之间的并行。
- 需要增加事务语义包括recovering