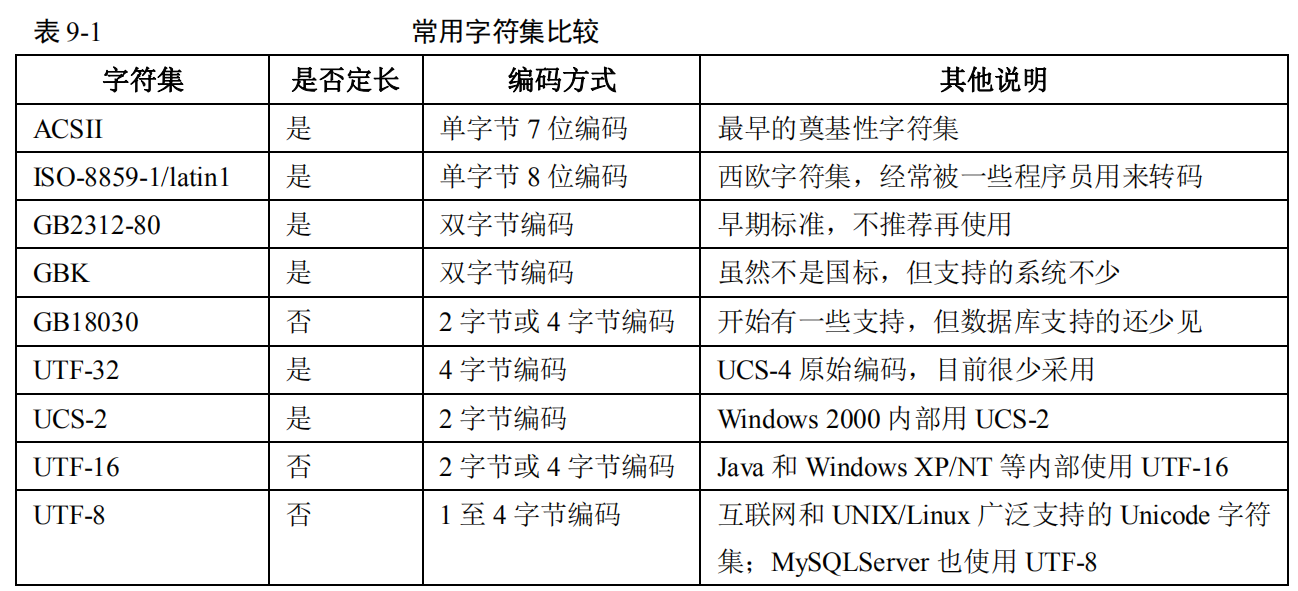
字符集
- ascii: 变成国标ISO-646, 由7位编码, 包括大小写字母, 阿拉伯数字和标点符号, 33个控制符号。
- unicode
- 为了统一字符编码,iso 1984 推出iso-10646 字符集 又称ucs-4, 4个字节来表示字节, 分为组,面,行和格, 每个一个字节来代表。
- 1988年, 美国计算机协会成立unicode , 反对iso, 推出unicode 1.0, unicode 16, unicode-8
- utf – unicode transformation format 所写, 对于iso-10646 的0组0字面 字符(basic multi -lingual plan, bmp) 保持不变, 对于其他字符转化为2个16位的unicode 编码
- utf-8 主要省字节数, 因为大部分场景下,都是ascii 编码, 因此utf8 1字节兼容 ascii 字符集, 2字节 可以转化0X0080 ~ 0X07FF UCS-4, 3字节 用于ucs-4 0x0800 ~0xFFFF, 4字节用于0x00010000 ~ 0001ffff 原始码。
![image.png]()

1 | mysql> show character set; |
字符集character: 定义mysql 存储字符串的方式
校对规则collation: 定义 比较字符串的方式。 一个字符集,可以对应多个校对规则, 比如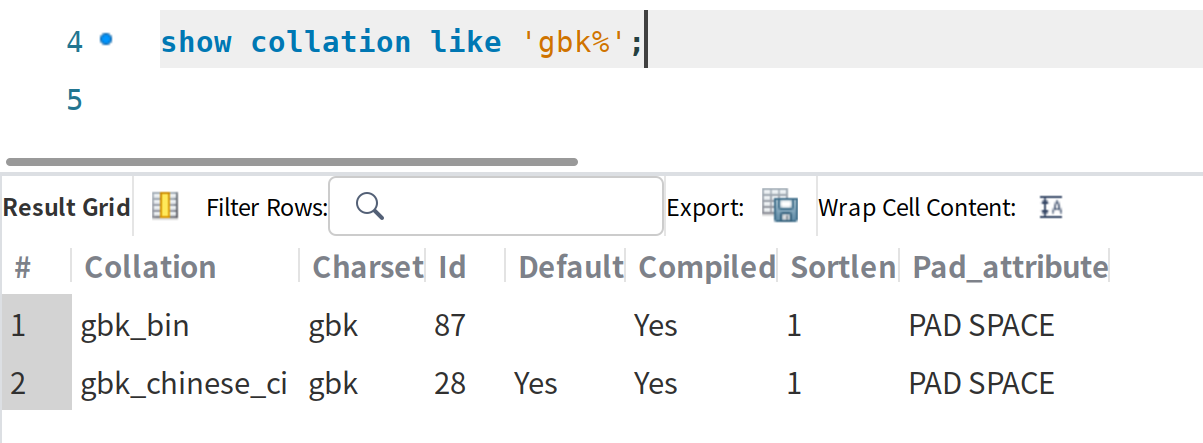
校对规则命名规范: 字符集开始, 通常包括一个语言名, 以ci(大小写不敏感), cs(大小写敏感), bin(基于字符编码的值)
服务器默认字符集
1 | 可以在 my.cnf 中设置: |
不能对已经存在数据的database 进行修改 字符集进行修改数据内容
- 如果指定了字符集和校对规则,则使用指定的字符集和校对规则;
- 如果指定了字符集没有指定校对规则,则使用指定字符集的默认校对规则;
- 如果没有指定字符集和校对规则,则使用服务器字符集和校对规则作为数据库的字
符集和校对规则。
显示当前数据库的字符集和校对规则
1 | show variables like 'character_set_database'; |
表的字符集和校对规则, 类似数据库的定义方式
查看表的字符集和校对规则
1 | mysql> show create table z1 |
可以对一个列 进行单独的设置
对于应用来说, 还有3个不同的参数, character_set_client, character_set_connection, character_set_result.
通常情况下, 这3个参数应该一样, 否则会有乱码。 可以一次性全部设置
1 | SET NAMES UTF8; |
建议在my.cnf 中进行设置
[mysql]
default-character-set=utf8
字符串常量的字符集 是由 character_set_connection 参数来指定。
也可以手动强制进行设置
1 | [_charset_name]'string' [COLLATE collation_name] |
修改空数据库或空表的字符集和校对规则
1 | alter database character set *** |
如果对一个已经有数据的进行调整
1 | 比如将一个latin1的字符集修改为gbk的字符集 |
–quick:该选项用于转储大的表。它强制 mysqldump 从服务器一次一行地检索表中
的行而不是检索所有行,并在输出前将它缓存到内存中。
–extended-insert:使用包括几个 VALUES 列表的多行 INSERT 语法。这样使转储文件
更小,重载文件时可以加速插入。
–no-create-info:不写重新创建每个转储表的 CREATE TABLE 语句。
–default-character-set=latin1:按照原有的字符集导出所有数据,这样导出的文件中,
所有中文都是可见的,不会保存成乱码。
(4)打开 data.sql,将 SET NAMES latin1 修改成 SET NAMES gbk。
(5)使用新的字符集创建新的数据库。
create database databasename default charset gbk;
(6)创建表,执行 createtab.sql。
mysql -uroot -p databasename < createtab.sql
(7)导入数据,执行 data.sql。
mysql -uroot -p databasename < data.sq